Networking & Content Delivery
CloudFront Migration Series (Part 2): Audible Plus, The Turning Point
Introduction
In 2020, users have come to expect a flawless streaming media experience, whether it’s video, music, or audiobooks. Playback must start quickly and be resilient to changes in network availability and bandwidth. To deliver all of this content, you must have a performant, highly available and reliable Content Delivery Network (CDN) to reach customers worldwide. But what do you do if your infrastructure is not able to evolve with your requirements? Audible, an Amazon company, faced these challenges over 2019-2020 which motivated our move to Amazon CloudFront for our Audio Streaming Infrastructure. Click here to learn more about edge networking with AWS.
Audible is one of the world’s leading producers and providers of original spoken-word entertainment and audiobooks, having a catalog of over 590,000 titles and 100,000 podcasts. In August 2020, Audible launched Audible Plus, an all you can listen benefit that enabled unlimited listening to a large collection of expertly curated audiobooks, podcasts, and Audible Originals. To reduce the barrier to discover new content, members can freely stream titles, downloading them for later offline listening once they’ve fully committed to the title.
To backstop this high-profile launch, we needed a more optimized and extensible CDN that could grow with us as we improved our new offerings. Our CDN at the time posed many challenges:
- Startup Latency: We frequently breached our P90 performance thresholds, resulting in management escalations.
- Error Rates: High error rates resulted in a collection of workarounds to have content play flawlessly.
- Audio Quality: Many Audible Originals incorporate dynamic sound design, music and multi-channel dramatization to engross listeners in the world of the story. Some listeners were dissatisfied with the quality of their content. But increasing bitrates or launching alternative codecs was either not supported or resulted in increased issues.
After we dived deep into these issues, we root caused them to fundamental architectural flaws in our CDN. It was fundamentally built for video, had scaling issues with the stream generation process, and did not provide enough transparency to view and react to issues quickly.
This blog details the challenges, journey, and results of our migration onto CloudFront, including many best practices that helped us along the way.
What makes Audible unique?
Audible’s use cases go beyond traditional VOD for music or video largely due to the nature of our content:
- Audiobooks are audio only, like music.
- Audiobooks are tens of hours long on average, but are frequently more than 100 hours long.
- Audiobooks are distributed as a single large book, broken up into chapters to facilitate navigation, similar to an e-book.
- Audiobooks are delivered as VOD streams. Live Streaming is not a use case.
These characteristics alone made us unique enough to the point where a standard architecture of AWS Elemental MediaPackage and Amazon CloudFront would not suffice. Keeping these characteristics in mind, let’s dive into the existing use cases we’ll have to carry forward onto AWS:
Progressive Download and Play
 |
This has been the primary consumption use case for many years including today. Users can queue up a list of titles to download and start to listen to them as soon as 1 second of audio is downloaded. They can also listen while offline, but playback is not instantaneous, especially when resuming a previous session. Users have to wait until they have downloaded up to their previous position to resume listening to their title. |
Full-Title Streaming
 |
This is the base case scenario for all streaming applications. Applications will want to stream the entirety of the audiobook at once. Users can skip through chapters of the book without the player fetching a new manifest file. This is typically done by mobile, desktop and web apps where sufficient memory to load large manifests is available. |
 |
The Clipping Feature is an innovative feature that Audible launched in 2016. Users can create clips of their favorite audiobook passages and then listen to them before committing to navigate away from the current position. |
Chapter by Chapter Streaming
 |
Chapter by Chapter streaming is where devices will specifically ask to stream a title a chapter at a time, internally building a playlist of chapters. When users navigate between chapters, the player will actually switch streams, fetching new manifests and creating new buffers. This is typically used on resource constrained devices that can’t fit large manifest files in memory. |
As AWS gives full control to the developer to architect systems, we saw we could generalize the clipping capabilities to create new experiences in the future: creating downloadable parts or new ways of sampling for example. Therefore, the ability to extend the base solution to new use-cases was paramount.
Previous Architecture
The following diagram depicts our previous Content Delivery system at a high level:

On the left, we have our Content Ingestion workflow that will manage Audible’s catalog contents, and the accompanying Transcoding Pipeline. The key highlight here is the fact that all content is packaged twice in two different containers. We use a simple MP4 container to serve as the backing asset for the Streaming CDN. AAX is an Audible proprietary download-only container specifically designed for audiobooks since Audible’s founding. It is based off of the M4B standard, and packages not only the audio, but chapters and product metadata in a single container. This helped to simplify integration with “Audible Ready” devices since transferring just one file would be sufficient to start playback.
The rest of the content delivery infrastructure is largely industry standard in terms of rights, licensing and URL vending functions. The interesting thing here is what happens in step 5 (Fetch Manifest w/clipping params). The CDN works largely on demand—creating the Streaming Manifest on receipt of a request. When a manifest is not cached, the CDN downloads the backing MP4 from Amazon S3 to the edge, transmuxing it to an MPEG-TS container while creating the manifest in parallel. This process can be time intensive since it largely depends on the speed of downloading and processing of a large audio asset.
This solution ended up not scaling for our catalog contents, leading to manifest generation timeouts. Sometimes the CDN would generate segments that were so small, they couldn’t be downloaded. This was because of rounding errors introduced by not using floating point segment durations.
Next, due to legacy reasons, our transcoding pipeline could not guarantee that assets it created were completely valid, resulting in playback issues. We built up a patchwork of workarounds to ensure a relatively healthy quality of service for users, but the writing on the wall was clear that our solution needed to be re-architected. This prevented us from using the streaming assets for our primary consumption use cases.
Finally, the duplicate assets and infrastructures (download vs streaming) adds extra complexity to the clients, delivery system and extra storage costs. This duplicity is largely due to legacy reasons.
In summary, our legacy system posed the following challenges:
- Timeouts and Generation Errors: our CDN solution couldn’t generate streams correctly and quickly
- Legacy Transcoding Pipeline: our old transcoding pipeline couldn’t guarantee the validity of the published assets
- Duplicate Assets & Infrastructure: we used multiple separate infrastructures for download and streaming, when one would suffice
- Lack of Extensibility: our CDN solution did not support MPEG DASH, modern DRM systems, or alternative audio codecs
Why CloudFront?
Amazon CloudFront is a content delivery network (CDN) service that securely delivers data, audio, videos, applications, and APIs to customers globally with low latency, while providing a self-service, developer-friendly environment.
CloudFront is one of the most powerful CDNs on the market today—supporting advanced features such as read-ahead byte range fetching, cache key customizations, multi-origin support and multi-tiered caching.
AWS Lambda@Edge is an additional CloudFront feature that allows you to customize CDN behavior by executing your own custom logic close to your users around the world. Lambda@Edge promises a performance boost over origin deployed compute due to its proximity to users. Users do not have to connect to servers half way around the world over the open internet.
The customizability of both services offers us the flexibility to support our existing use-cases, while enabling future ones by simply manipulating settings or modifying Lambda code.
Another important consideration was the ability to get detailed insights into how the infrastructure is performing. CloudFront comes with quite a few metrics out of the box, which AWS expanded on during re:Invent 2019. In addition to these, you can extend CloudFront with custom Amazon CloudWatch metrics and alarms you implement in Lambda functions to get even deeper insight for your use case. Everything is self-service and at your fingertips.
Ultimately the superior performance, control, customizability, and insights capabilities sold us on moving to AWS and CloudFront.
Architecture on AWS
The following diagram shows our new architecture on AWS. The primary differences are upgrades to the transcoding pipeline and a pair of Lambdas running in CloudFront using Lambda@Edge. An origin request Lambda generates manifests, and a viewer request Lambda controls access by verifying our custom auth scheme.

We field three new streaming protocols, backed by two assets:
- A raw AAC backed elementary audio HLSv4 stream. Since all of our clients support HLSv4, this stream serves as the one we migrate all of our clients to onto AWS. This serves as a fallback stream for any future resource constrained clients, as it is a relatively simple stream. Finally, we can also generate clips, samples and more from a single asset as it is byte range addressable.
- A CMAF backed MPEG DASH & corresponding HLSv7 stream. These streams serve as the primary playback streams we want all clients to adopt. CMAF is codec agnostic and supports CENC DRM which can help replace AAX to serve as the single asset type for Audible. CMAF is also byte range addressable.
Manifest Generation
The key realization here was that clips, chapters, parts, samples or full title streams are nothing more than byte range requests into a larger single asset. Since players use the manifest to decide which byte ranges to request, controlling the manifest creation was key.
Since clipping is defined by the user, we have to continue to generate manifests dynamically. But we make a critical change here by leveraging the transcoding pipeline to prepare the content enough so manifest generation does not depend on the asset. The key is to export all asset metadata to an external data store that the Lambda can retrieve quickly. We need access to asset metadata—bitrate, sample rate, channel count, duration, and an array of segment byte offsets to create segments.
We evaluated several options here: Amazon DynamoDB global tables and flat files on S3. Since DynamoDB and S3 flat files had similar performance, we decided to use S3 as it was the simpler of the two. There’s hardly any maintenance and it scales automatically. Ultimately, we aligned on Protocol Buffer (Protobuf) encoded binary files due to its fast decode performance, compact size, and future extensibility through a schema.
So in conclusion, Manifest Generation here entails:
- Downloading the Protobuf file
- Using the desired start/end time offsets to select a sub-list from the segment offsets array.
- Aggregating groups of offsets together to form segments. This is where the desired segment size comes in, which does not have to be uniform throughout.
Since we could download Protobuf files quickly, and the remaining computations are mostly text manipulation, this helped to resolve our performance issues.
Resolving our asset generation issues required us to modernize our transcoding pipelines, replacing our packager and validation steps. We used a new packager that could:
- Package our content in our new formats with our current and any future set of audio codecs.
- Supported FairPlay and CENC DRM.
- Package our largest content in seconds or minutes.
We removed the patchwork of workarounds by integrating a new validator that would use the Protobuf file to “stream” the audio exactly as the client would play it. This meant parsing the Protobuf, container format, and decoding the audio inside. This ensured the final results of the pipeline were clear to be uploaded to S3. This helped to resolve our generation errors.
Lastly, this set us on a path to reduce duplicate assets over time. By using CMAF, we could stream or download it, use Industry Standard DRM, and support any audio codec regardless of the consumption method.
Why Lambda@Edge?
After selecting a generation mechanism, we had to decide where to run it. We evaluated AWS Elemental MediaPackage, Amazon API Gateway and Lambda@Edge. We ruled out Elemental since it did not support audio only streams or 100+ hour long content.
| Elemental | API Gateway | Lambda@Edge | |
| Supports Long
Audio Content |
No | Yes | Yes |
| Deployment Location | CDN Origin | CDN Origin | Edge |
| Deployment Modes | Origin | Edge Optimized, Regionalized | CloudFront Edge |
| Supports Clipping | Yes | Yes | Yes |
| Supports Caching | Yes | Yes | Yes |
| Turn Key Solution | Yes | No | No |
| Flexibility | Depends on Elemental Feature Set | High | High |
| Limitations | No audio only support | 6 MB response
10,240 MB RAM |
1 MB response
|
This left API Gateway and Lambda@Edge as contenders. To choose between them, we created a prototype and subjected it to a worldwide performance test.
| %age Improvement, compared to Regionalized API Gateway | ||||
| Region | Run Count | Regionalized API Gateway | Edge Optimized API Gateway | Lambda@Edge |
| India | 2036 | – | 15.40% | 30.20% |
| Germany | 1323 | – | 7.30% | 16% |
| France | 660 | – | 3.50% | 13.60% |
| Canada | 497 | – | 0.40% | -0.30% |
| United States | 7116 | – | 9.26% | 6.08% |
| United Kingdom | 991 | – | 4.04% | 4.62% |
| Australia | 664 | – | 19.73$ | 20.40% |
| Japan | 576 | – | -5.60% | 8.65% |
| Italy | 331 | – | -5.70% | 16.23% |
Lambda@Edge proved to be faster in our tests, in most regions around the world, largely owing to proximity of the processing to the user. Performance being our key consideration, it outweighed the negatives of not supporting multiple CDNs.
Optimizations
Playback Startup Performance
Optimizing playback startup performance requires optimizing manifest creation/delivery and segment sizes. Therefore, we looked to optimize our usage of Lambda@Edge, reduce our manifest sizes and select an appropriate segment size. Let’s dive into each of these areas one at a time:
Lambda@Edge Optimizations
Although Lambda@Edge is already optimized in many ways out of the box, what you do in your code is very important to maximize performance. We optimized the performance of our functions by:
- Reducing Lambda Invocations – manifests, once generated, can be reused by multiple users. Thus, it made sense to generate manifests in an origin request Lambda. We made sure to only set cache key options where our Lambda would generate a different response: clipping query parameters and CORS headers. In our traffic pattern, we achieved upwards of a 94% cache hit ratio, executing Manifest Generation only 6% of the time worldwide.
- Making Regional Network Calls – Lambda@Edge runs in numerous regions around the world, and any network call made out of region can negate its performance benefit. Therefore, we ensured to make all network calls in region. This includes the obvious, but easy to forget ones like authorization keys, and CloudWatch metrics.
- Reducing TLS/TCP Handshakes – all AWS SDK service objects allow you to set network options such as TCP Keep Alive, retries, timeouts, and region.
- Leveraging Container Reuse – Lambda@Edge runs a full-fledged Lambda container, similar to Lambdas running in a VPC at an origin. Therefore, you have access to global Lambda container memory, where you can store objects or data between invocations. We leveraged Container Reuse to initialize all of our objects and make any static network invocations, such as auth keys.
- Choosing an Optimal Origin – we replicated the catalog to multiple regions and leveraged CloudFront’s Origin Failover feature to ensure we have better availability. In addition, we modified the origin section of the request object to influence which origin a request goes. For example, a Lambda running in South Korea probably shouldn’t go to us-east-1 first, but eu-west-1 or something closer. But a Lambda running in South America should probably go to us-east-1 first simply due to proximity.
- Reducing Network Invocations – we recognized the Asset Metadata we download from S3 is read-only and immutable. Therefore we can cache that data. We chose to cache this data within the Lambda itself using an LRU cache. This ensured the most popular content could skip requests out to origin. In our traffic pattern, we achieved upwards of 70% cache hit ratio on this secondary cache.
Please see the Lambda@Edge Best Practices blog to read about these best practices in greater detail.
Manifest Size Reductions and Segment Sizes
The HLS protocol declares each segment in groups of 2 – 3 lines of text. This can result in manifests with 1000s of lines of text. While working on this, we had an interesting observation: the longer the content was, the longer a manifest is, and the slower it is to generate. But if you increase segment sizes, there is fewer looping through the offsets array and text manipulation, boosting performance.
We initially looked to keep the 10 second segment sizes carried over from our previous CDN, but we ended up increasing it to 20 seconds. This immediately halved the manifests, bringing our generation times down accordingly. The downside here is that a larger segment size means clients have to download more audio to start streaming. We accepted this risk and decided to modify the segment sizes as needed based on performance tests.
MPEG DASH has facilities like SegmentTemplate and SegmentBase to reduce this to a few lines. Unfortunately, we couldn’t launch SegmentBase style manifests as we need to modify the audio asset itself to inject a dynamically created segment index. Therefore, we used SegmentList style manifests as they are relatively small compared to HLS and its generation performance met our requirements.
| Duration | HLS CMAF | HLS CMAF | DASH | DASH |
| (Compressed) | (Compressed) | |||
| 11m | 13 KB | 747 bytes | 2.8 KB | 1.2 KB |
| 10h 4m | 634 KB | 18 KB | 86 KB | 16 KB |
| 36h 2m | 2.3 MB | 63 KB | 310 KB | 55 KB |
| 58h 4m | 3.8 MB | 102 KB | 502 KB | 88 KB |
| 91h 4m | 5.9 MB | 158 KB | 800 KB | 137 KB |
| 153h 59m | 10 MB | 262 KB | 1.4 MB | 232 KB |
Bandwidth Consumption
Next, we wanted to ensure we consumed the least amount of network bandwidth as we could. This has two benefits:
- The smaller the data you deliver, the faster the player can start
- Bandwidth savings for users on expensive cellular connections
Besides making smaller manifests, we had to maximize the amount of audio we delivered for every bit the user downloaded. This influenced which container format we used. We deep dived into various formats here which resulted in our selection of CMAF and AAC:
| Quality | File Size Comparison |
| 22/32 LC-AAC Mono | CMAF < AAC by 5.5%, AAC < MPEGTS by 5.96% |
| 22/64 LC-AAC Stereo | CMAF < AAC by 0.58%, AAC < MPEGTS by 6.44% |
| 44/64 LC-AAC Stereo | CMAF > AAC by 2.4%, AAC < MPEGTS by 6.76% |
| 44/128 LC-AAC Stereo | CMAF > AAC by 1.2%, AAC < MPEGTS by 7.96% |
| 44/256 LC-AAC Stereo | CMAF > AAC by 0.6%, AAC < MPEGTS by 9.66% |
| 44/320 LC-AAC Stereo | CMAF > AAC by 0.48%, AAC < MPEGTS by 7.97% |
CMAF is not as compact as AAC at the higher sampling rate, but it is definitely better than MPEG-TS. MPEG-TS is the worst option for bandwidth consumption.
Cache Hit Ratios
An important innovation with CMAF was the use of byte range addressing while being codec agnostic. By using byte range requests, we avoid competing with ourselves for cache width on the CDN since they typically use URL path, query parameters, and certain HTTP headers to determine cache keys. Byte range fetches usually map to the same cache key and force the CDN to optimize how it handles multiple requests for ranges. CloudFront has some interesting optimizations here that helped us.
Read-Ahead Byte Range Fetching is a CloudFront feature that helps achieve high cache hit ratios for subsequent byte ranges as users “walk through” a file. It works by first requesting relatively large byte ranges (1 MB) of a file from the origin as the user makes their byte range requests. If the user’s request can be completely fulfilled by the byte range in cache, the edge responds and the request ends. If not, the edge makes subsequent requests to pull the next large (1MB) byte ranges into cache.
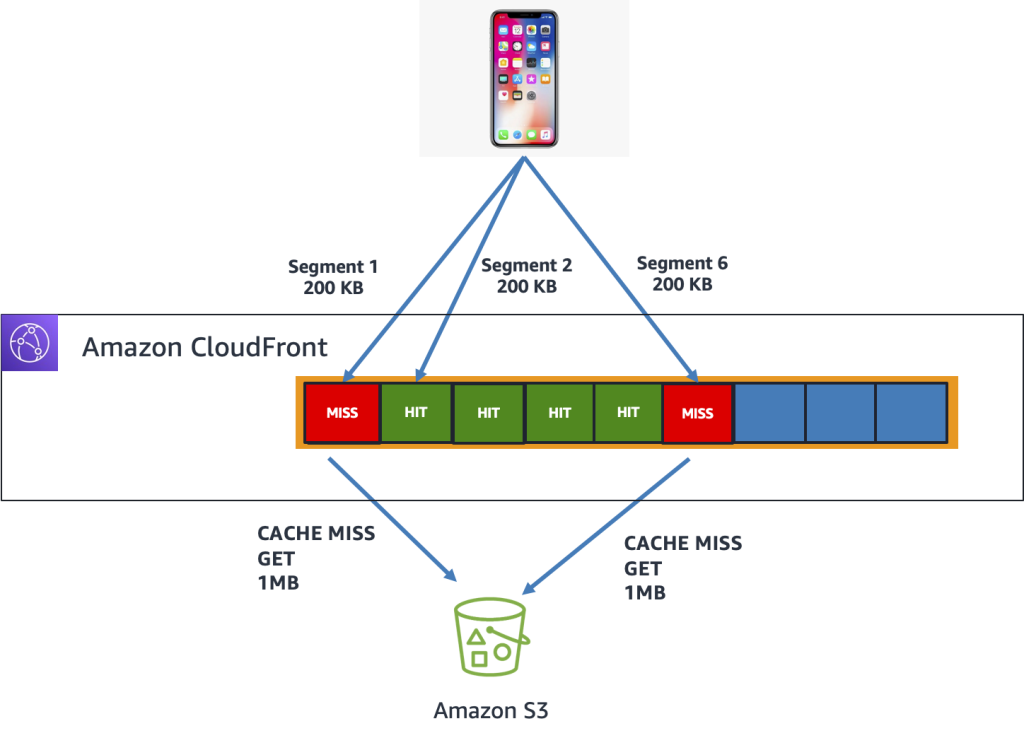
Once CloudFront has managed to pull twenty 1 MB ranges into cache, it optimizes subsequent requests by asynchronously downloading the remainder of the file to the edge. Once the download completes, every request from then on is guaranteed to be a cache hit. This translates to better performance for the end user as the user “walks” through the file, bringing subsequent bytes into the cache without relying on other users. This helps give the first user a similar experience as subsequent users who hit a primed cache.
Due to these optimizations, we were able to achieve Cache Hit Ratios of 94%:

Integration and Rollout
Final Performance Tests
Once we stood up our new infrastructure, we ran some final performance tests to compare manifest generation on the two CDNs. Ideally, we would have wanted to test end to end Playback Latency, but could not do it at scale around the world easily. Therefore, we settled with what we could do in our lab tests, punting to actual launch to collect more data from real users.
We set up a 3P tool, such as Catchpoint or Dynatrace, to hit both CDNs in every major country where Audible has a presence. We set up a representative set of assets, varying duration and bitrate, to collect information across the spectrum of our existing content. We tested using ISP backbone networks to rule out any variation between end user networks. This helped to isolate the raw performance of manifest generation and CDN delivery.
Our tests showed very impressive improvements compared to our old CDN:
| %age Improvement on CloudFront vs Legacy | |||
| Country | P95 | Average | Number of Runs |
| Australia | 34% | 49% | 670 |
| Canada | 6% | 19% | 502 |
| France | 25% | 25% | 670 |
| Germany | 32% | 35% | 1342 |
| India | 32% | 41% | 1994 |
| Italy | 34% | 46% | 334 |
| Japan | 32% | 26% | 586 |
| New Zealand | 52% | 55% | 84 |
| United Kingdom | 12% | 23% | 993 |
| United States | 23% | 29% | 7086 |
Even though this was a lab test, this was very encouraging that we were headed in the right direction.
Integration
Prior to our cutover, we performed final QA with all of our clients to ensure playback would work. All of the mobile platforms worked properly, but we ran into issues on most smart home speakers. There were tens to hundreds of device types that we had to test.
We spent an exorbitant amount of time working with the device teams to get the issues resolved. The device teams fixed issues and issued Over the Air (OTAs) updates and we waited until they gained sufficient adoption by the user base. Since this would take a good amount of time, we introduced the concept of an “Allow List” in our Licensing Service that would ensure only those devices would be allowed on CloudFront.
| Platform | Challenges | Solution |
| Apple | None | |
| Android/FireOS | None | |
| Web |
|
|
| Alexa |
|
|
| Other Third
Parties |
|
|
Rollout
Actual rollout was done incrementally, gradually cutting over a %age of users over time. Once we reached 50% adoption, we performed an A-B test over several weeks to collect measurements. The measurements did not reflect the data we collected earlier—the average performance was actually worse than our previous CDN!
| %age improvement on CloudFront vs Legacy | ||
| 20 sec segments | 10 sec initial, 20 sec then on | |
| AVG | -5% | 4% |
| P95 | 5% | 10% |
| P100 | 10% | 5% |
We ultimately had to modify our Manifest Generation logic to set the initial segment at 10 seconds to boost playback performance. This brought up the numbers sufficiently to provide the performance benefits we had promised.
Results
Having completed our onboarding onto CloudFront in July 2020, we’ve realized the many theoretical improvements for our customers:
- Significant Worldwide Performance Improvements including:
- ~4% reduction in Time to Play on average, ~6% reduction at P99
- ~11% reduction in Playback Stall Lengths on average, 15% reduction at P99
- Over 18% reduction in Time to Play for our longest titles, resulting in all streams starting in < 4s at P99 regardless of duration or bitrate over WIFI.
- Significant Error Rate Reductions:
- ~52% reduction in errors
- ~45% reduction in playback errors for Audible Suno customers
- Resolves playback issues for over 300 playback sessions per day on Amazon Echo devices.
- Significant Bandwidth Savings: Over 300+ TB per month!
- Expanded support for large files, including support for Higher Quality Audio.
In addition to customer benefits, the onboarding helped Audible Engineering gain complete control of the Playback Infrastructure—helping us to tune performance, reduce error rates, and leverage it for greater tech efficiency for future solutions.
Conclusion
In this blog post, we walked through the motivations, journey, and results of Audible’s migration onto AWS for our Media Streaming solution. We achieved numerous improvements for our existing and new customers, while also improving our ability to add features and control the future experience.
| In August, 2020, we also launched Audible Plus in the US on top of this solution. Audible Plus is our brand new, first of its kind, all you can listen service that includes a catalog of expertly curated originals, podcasts, and audiobooks. It also provides immediate added value to our existing customers who will now have access as part of their current membership; and at a flat monthly fee, a perfect entry point for new customers who want to explore audio storytelling in more depth. |  |
To learn more about media solutions available in AWS, please see the CloudFront overview page, What’s New from Cloudfront, Media Services overview page, and the detailed Lambda@Edge docs.
If you want to learn more about our migration, please see our AWS Tech Talk. Stay tuned to Audible’s Announcements for more updates in the coming months and year!
As new blog posts roll out in this series, we will add links here. Additional blogs:
CloudFront migration series (Part 1) – introduction
CloudFront migration series (Part 3): OLX Europe, The DevOps way

Ronak Patel
Ronak is a Software Dev Engineer III at Audible. He is the architect for Audible’s Content Delivery and Playback systems. Ronak has deep expertise in Media Technology and has worked on a variety of distributed, web, desktop, & mobile applications through his 16 year career.