AWS Open Source Blog
Getting started with R on Amazon Web Services
This article is a guest post from David Kretch, Lead Data Scientist at Summit Consulting.
As R workloads grow and become increasingly resource intensive, the ability to move from a local compute environment to scaleable, fully managed cloud services on Amazon Web Services (AWS) becomes extremely valuable for cost, speed, and resiliency reasons. In this two-part series, part one will cover the basics of R and common workload pairings for R on AWS. In part two, “Using R with Amazon Web Services for document analysis”, we’ll take a deeper dive into building an end-to-end document processing application with AWS services.
Background on R
R is a programming language popular with statisticians, scientists, and data analysts. Its large user community has developed thousands of freely available packages, including packages for data manipulation, data visualization, specialized statistical estimation procedures, machine learning, accessing public data APIs like US Census data or Spotify, easily making data-based web apps, and many, many other areas. There are also high-quality free online books and other documentation explaining how to use R effectively.
One of the most popular sets of packages in the R ecosystem is the Tidyverse, a collection of libraries for transforming and using “tidy” data. These are designed to allow users to ingest data in whatever form in which it is received (e.g., from a CSV, an API, etc.) and easily transform it into the shape needed to analyze it, using a declarative “grammar” of data manipulation. The Tidyverse is a good fit for a lot of data analysis tasks, and it plays a big role in the continuing popularity of R.
Another important part of the R ecosystem is the development environment RStudio. RStudio is designed for data science. In addition to providing the editor and debugger, RStudio lets users view in-memory data structures with a built-in data viewer that allows us to sort and filter like a spreadsheet, view any graphs we make, see our database connections, and so on. The company behind the IDE, also named RStudio, sponsors a lot of R development (including the Tidyverse), holds conferences, and provides both free and paid versions of R server software, including software for hosting R applications as web apps.
Use cases for R on AWS
Big data processing
As data analysis trends towards larger datasets, R users—who may be used to running analyses locally on a laptop—often will hit barriers as the result of computing, memory, and cost constraints. By moving workflows to AWS, R users can overcome these barriers. R is often used to estimate complex statistical models that require significant computing power and time (hours or even days) to construct. Using Amazon Elastic Compute Cloud (Amazon EC2) instances tailored to the workload, or containers running on Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), AWS Fargate, or AWS Batch, AWS-managed compute services can help speed up model development.
For big data problems, R can be limited by locally available memory; high-memory instance types help here. R deals with data in-memory by default, so using an instance with more memory can make a problem tractable without having to make changes to code. Many problems are also parallelizable, and with R’s support for parallel processing, modifying code to use R’s parallel processing packages allows users to take advantage of instance types with a large number of cores. Between AWS’ R-type (memory optimized) and C-type (compute optimized) instances, developers can choose an instance type that closely matches their compute and memory workload needs.
Often, data scientists deal with these big problems only part of the time, and running permanent Amazon EC2 instances or containers would not be cost effective. For these types of workloads, AWS Batch is a good fit—it takes care of starting up the instance, running the job, and then shutting the instance down when the job is finished. Because you only pay while the instance is running, you’re not stuck paying for a powerful machine while you’re not actively using it, and you’re not limited by a fixed, static quantity of processing power.
Databases
Databases are a valuable resource for data science teams; they provide a single source of truth for datasets and offer performant reads and writes. We can take advantage of popular databases like PostgreSQL through Amazon Relational Database Service (Amazon RDS), while letting AWS take care of underlying instance and database maintenance. In many cases, R can interact with these services with only small modifications; the Tidyverse packages within R allow you to write your code irrespective of where it’s going to run, and allow you to retarget the code to perform operations on data sourced from the database.
File storage
Lastly, Amazon Simple Storage Service (Amazon S3) allows developers to store raw input files, results, reports, artifacts, and anything else that we wouldn’t want to store directly in a database. Items stored in S3 are accessible online, making sharing resources with collaborators easy, but it also offers fine-grained resource permissions so that access is limited to only those who should have it.
Getting started with AWS in R
To use AWS in R, you can use the Paws AWS software development kit, an R package developed by my colleague Adam Banker and me. Paws is an unofficial SDK, but it covers most of the same functionality as the official SDKs for other languages. You can also use the official Python SDK, boto3, through the botor and reticulate packages, but you also will need to ensure Python is installed on your machine before using them.
Next, let’s discuss how to use AWS through the Paws package.
To install Paws, run the following in R:
To use an AWS service, you create a client and access the service’s operations from that client:
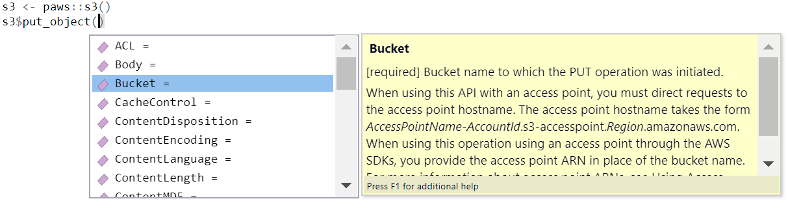
If you’re using RStudio, its tooltips will show you the available services, each service’s operations, and for each operation, documentation about each parameter. Here is an example of the tooltips available for S3’s put_object operation:
When accessing AWS APIs, you must provide credentials and region. Paws will search for credentials and region using the AWS authentication chain:
- Explicitly provided access key, secret key, session token, profile, and/or region
- R environment variables
- Operating system environment variables
- AWS shared credentials and configuration files in
.aws/credentialsand.aws/config - Container AWS Identity and Access Management (IAM) role
- Instance IAM role
For example, if you are running R and Paws on an Amazon EC2 instance or in a container with an attached IAM role, Paws will automatically pick up the IAM role credentials to authenticate AWS API requests; this capability was developed in part with the support of the AWS Open Source program.
You can explicitly set AWS credentials and region for all services by using environment variables, like so:
If you need to provide separate credentials per service, you can do that when you create the client for the given service. For example, if you are using another account’s S3 bucket with temporary security credentials, you can provide those to the S3 client like this:
You can find more detailed information about AWS credentials and configuration for Paws in the Paws credentials documentation. Additionally, follow AWS’s advice about protecting your AWS credentials, including: Don’t embed keys in code, and use different access keys for different applications.
Connecting to databases
You can use databases in R by setting up a connection to the database. Then you can refer to tables in the database as if they were datasets in R. The dplyr package in the Tidyverse and the dbplyr database backend are what provide this functionality.
If you are using a suitably configured RDS database, you can authenticate using a token generated by the Paws build_auth_token function in the RDS service; this is another feature developed with the support of the AWS Open Source program. Using an IAM authentication token allows you to avoid having to store passwords. Once connected, you can then use this database connection as before.
Using these packages, you can easily take advantage of AWS resources and databases running on AWS from within R.
In part 2, “Using R with Amazon Web Services for document analysis“, we’ll show you how to use these to build a data workflow to convert PDFs into data we can use, by taking advantage of services on AWS.

David Kretch
David Kretch is Lead Data Scientist at Summit Consulting, where he builds data analysis systems and software for the firm’s clients among the federal government and private industry. He, alongside Adam Banker, is also coauthor to Paws, an AWS SDK for the R programming language. Adam Banker is a full-stack developer at Smylen and also contributed to this article.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
Feature image via Pixabay.