AWS Storage Blog
Accelerating GPT large language model training with AWS services
GPT, or Generative Pre-trained Transformer, is a language model that has shown remarkable progress in various vertical industries. This technology has been used to generate human-like text in fields such as finance, healthcare, legal, marketing, and many others.
In finance, GPT is being used to analyze financial data, generate reports, and assist with decision-making. In healthcare, GPT is being used for natural language processing, medical diagnosis, and drug discovery. In legal, GPT is being used for contract analysis, legal research, and eDiscovery. In marketing, GPT is being used to generate personalized content, optimize ad campaigns, and analyze consumer behavior.
Training large language models is a resource-intensive task that requires powerful computing resources with fast data access. As language models continue to grow in size and complexity, cloud-based compute and storage infrastructure has become increasingly necessary to meet the demands of model training and development.
In this blog post, we’ll explore AWS services that can accelerate GPT model development. We will review a reference architecture, and the AWS value proposition for customers interested in training large language models in their perspective vertical industries.
AWS Services used for GPT deployment
Customers can use several AWS services to train and evaluate their GPT models, including Amazon SageMaker, Amazon Elastic Compute Cloud (EC2), Amazon FSx for Lustre, and Amazon S3.
Amazon SageMaker is a key component for GPT training processes. SageMaker is a fully-managed service that provides developers and data scientists with the ability to build, train, and deploy machine learning models quickly and easily. With SageMaker Model Parallelism (SMP) library, customers are able to create and manage large-scale training jobs for their models, and scale those jobs across multiple GPUs and instances as needed to meet the demands of their workload.
Amazon EC2 P4d instances are specifically designed for machine learning workloads that require high-performance computing. Amazon EC2 P4d instances are comprised of the highest performance compute, networking, and storage in the cloud enabling customers to run their most complex multi-node ML training jobs.
A global financial data provider recently trained their GPT model on a total of 64 x P4d.24xlarge instances on AWS, each instance has 8 NVIDIA 40GB A100 GPUs with NVIDIA NVSwitch intra-node connections (600 GB/s) and NVIDIA GPUDirect using AWS Elastic Fabric Adapter (EFA). The deployed AWS configuration provides a total of 512 40GB A100 GPUs. The following is a reference architecture of the AWS deployed solution.
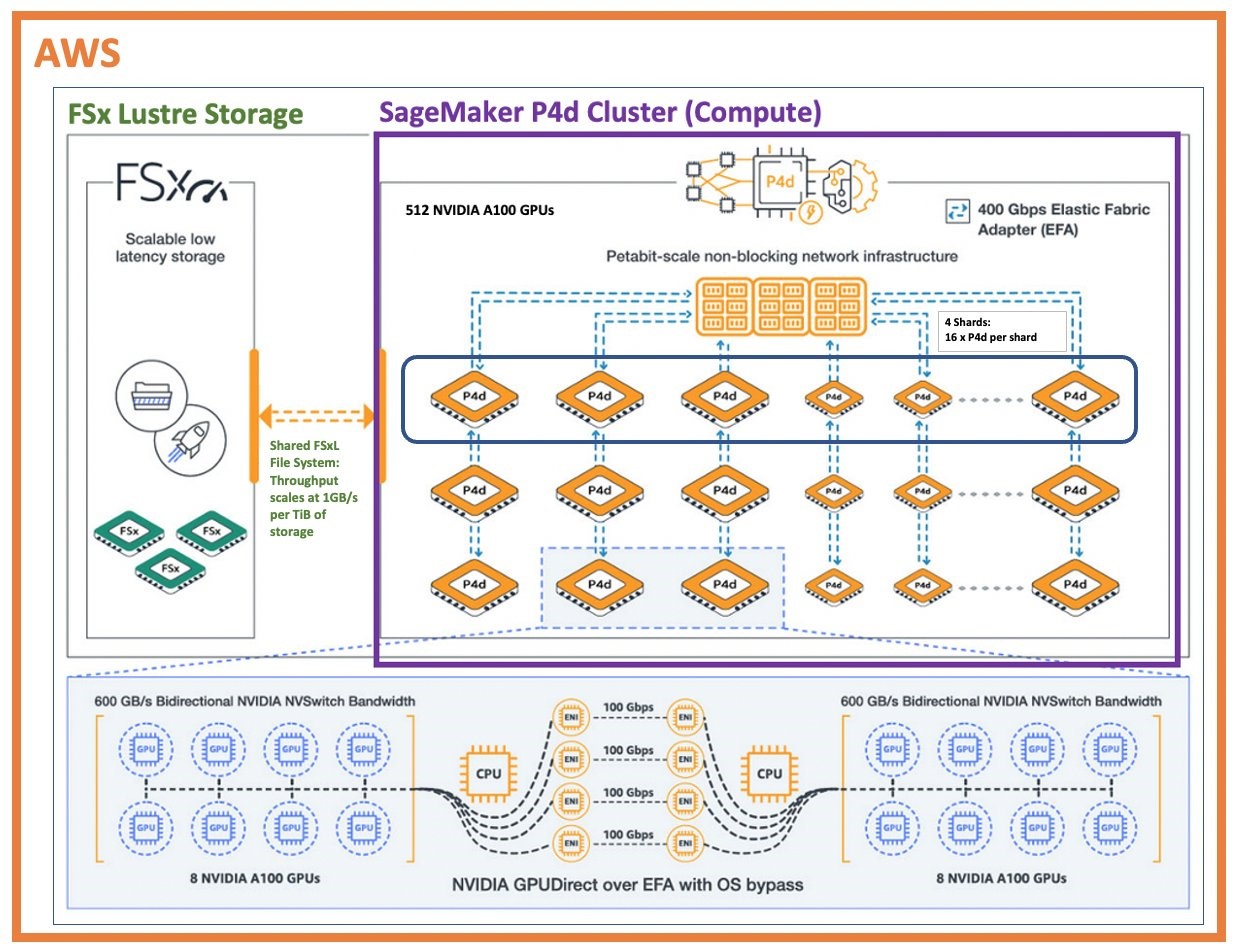
Figure 1 – AWS FSx for Lustre/SageMaker/Ec2 P4D cluster reference architecture for GPT model development
Elastic Fabric Adapter (EFA) is a high-performance network interface for Amazon EC2 instances that enables low-latency, high-throughput, and high-message-rate communication between instances. EFA delivers up to 400 Gbps of network throughput and sub-microsecond latencies, making it ideal for tightly-coupled distributed ML applications. Amazon FSx for Lustre is a fully-managed file system that provides sub-millisecond access to petabyte-scale data sets. It delivers up to 1000 MB/s read and write throughput per TiB of storage. Amazon FSx for Lustre provides fast data access during model training.
The combination of P4d instances with 400 Gbps EFA network bandwidth, Amazon FSx for Lustre high throughput and low latency access to data, and the use of Amazon SageMaker are key AWS services for accelerating GPT model development.
Performance results on AWS
The training of large language models is computationally intensive and requires significant hardware resources to achieve state-of-the-art results. A GPT model from a large data provider was trained on the above AWS reference architecture for 5 days using a sequence length of 2048 tokens and achieved a peak throughput of 24,000 tokens per second. Each token typically represents a word, so a sequence length of 2048 tokens means that the model can process a text input of up to 2048 words in length.
To put some perspective on this, say we want to process financial articles with this model, and let’s say the average financial article is 750 words. Given the peak throughput of 24,000 tokens per second, we can calculate the number of tokens processed per minute:
24,000 tokens/second * 60 seconds/minute = 1,440,000 tokens/minute
Since we assume one token is equivalent to one word, we can estimate the number of financial articles processed per minute:
1,440,000 tokens/minute / 750 words/article = 1,920 financial articles/minute
With these assumptions, the model can process approximately 1,920 financial articles per minute, which is impressive. This is a significant improvement over previous language models, which often needed weeks or even months of training time and achieved lower peak throughputs. For example, the GPT-2 model, which was released in 2019, required 8 days to train using a sequence length of 1024 tokens and achieved a peak throughput of 13,700 tokens per second.
The ability to train large language models more quickly and with higher throughput has important implications for natural language processing tasks. It allows researchers and practitioners to experiment with larger models and more complex architectures, which can lead to improvements in a wide range of applications such as language translation, text summarization, and question answering.
In addition to the peak throughput of 24,000 tokens per second achieved during training, the GPT model also achieved impressive results on a range of language modeling benchmarks.
On the LAMBADA language modeling benchmark, which tests a model’s ability to predict the last word in a sentence given the rest of the sentence, the GPT model achieved a perplexity of 9.49. This is the lowest perplexity score reported to date on this benchmark and demonstrates the model’s ability to capture complex dependencies between words in natural language.
On the WikiText-103 benchmark, which evaluates a model’s ability to predict the next word in a sequence, the GPT model achieved a perplexity of 16.3, which is again the lowest reported perplexity on this benchmark.
The model was also evaluated on the Stanford Question Answering Dataset (SQuAD), which requires the model to read a passage of text and answer a set of questions based on the content of the passage. The GPT model on AWS achieved an F1 score of 87.8 on this benchmark, which is a good F1 score on SQuAD.
These impressive results demonstrate the benefits of using AWS advanced hardware and software infrastructure to train large language models, and highlight the potential of these models to improve a wide range of natural language processing tasks.
The potential of deep learning solutions for vertical industries
AWS has the infrastructure and services to deliver impressive performance results and can provide customers the ability to process large datasets. Many vertical industries generate enormous amounts of data including financial services, healthcare, legal, marketing, and many others. Much of this data is in the form of natural language: news articles, analyst reports, court cases, medical research, and regulatory filings are some examples, by training or using models trained on this data, customers can extract valuable insights faster and programmatically.
With the growing availability of cloud-based deep learning solutions like Amazon SageMaker and powerful EC2 P4d instances and FSx for Lustre storage service, customers in different vertical industries have an opportunity to develop or leverage state-of-the-art language models for their own applications. These models could be used to analyze articles, customer feedback, market trends, and other unstructured data sources to provide insights and recommendations to a variety of consumers, investors, and analysts.
The growing interest in GPT highlights the potential for further advancements in large language models. As models continue to improve, they have the potential to revolutionize the way customers process and analyze vast amounts of data, leading to more informed business decisions and better risk management.
Closing comments
AWS offers a range of specialized compute instances like the EC2 P3 and P4 instances that are optimized for deep learning workloads. These instances are equipped with powerful GPUs and high-speed interconnects, which enable faster training of complex models. AWS also offers a number of storage options like Amazon FSx for Lustre and Amazon S3 that are ideal for storing and processing large datasets and Amazon SageMaker that provides a high-level interface for training models and automatically scales the underlying infrastructure based on the size of the dataset.
The performance results shown here demonstrate the incredible potential of deep learning solutions for various industries. AWS’s infrastructure, services, and deep learning tools make it much easier for customers to run and deploy their natural language processing workloads. As the technology continues to improve, the possibilities for innovation in various vertical industries are truly limitless.
Learn more about machine learning with AWS
- Scaling Large Language Model (LLM) training with Amazon EC2 Trn1 UltraClusters
- Training a 1 Trillion Parameter Model with PyTorch Fully Sharded Data Parallel on AWS
- Transfer Learning with Amazon SageMaker and FSx for Lustre
- How Latent Space used the Amazon SageMaker model parallelism library to push the frontiers of large-scale transformers