AWS Storage Blog
Using AWS Backup to protect Amazon Aurora databases
Many organizations use databases to support their most mission-critical applications. Having a comprehensive strategy to protect these databases is the underpinning to meeting business service level agreements (SLAs). An optimal strategy includes using both backups and replication to protect databases in the event of a natural disaster, human error, or cyber threat.
Customers can use AWS Backup as a centralized solution to orchestrate their backups for a number of AWS services, including Amazon Aurora databases. Using AWS Backup as the orchestration engine, customers can set policies, monitor their backups, and replicate their backups across accounts or Regions, helping to ensure that they are Well-Architected. AWS Backup comes with additional functionality through the use of AWS Backup vault and AWS Backup Audit Manager. With AWS Backup vaults, customers can create an immutable copy of data that can then be replicated to another account or across Regions in an encrypted format over the AWS internal network.
In this blog, we aim to help you to understand why you should use AWS Backup, as well as the methodologies for incorporating AWS Backup into your Amazon Aurora environment and backup strategy. With AWS Backup, you have the ability to separate your backups from your production data, enhancing security and resiliency. Moreover, with backup vaults, you can also further separate your backup data into different logical constructs, which can be beneficial if you don’t want to manage all of your backup data together.
Use cases
Protecting your database workloads with AWS Backup can be done in a variety of ways, and depending on the methodology, you can achieve varying levels of protection, security, and management capabilities. For example, a simple daily database snapshot that is kept in the same account as the production database copy might be easy to use when a simple rollback is required, but it doesn’t do much to reduce the risk that a malicious attacker or large-scale disaster would introduce. AWS Backup provides this capability, but the blast radius is simply too wide for many customers. Customers use AWS Backup for Amazon Aurora databases to meet a wide variety of use cases, including simplified management via a central tool, operational recovery, and security.
Simplified management
AWS Backup supports a number of AWS services in addition to third-party applications. Customers have the same backup management experience whether they are backing up individual Amazon Simple Storage Service (Amazon S3) buckets or entire VMWare Cloud on AWS environments today. Many organizations opt to also have a centralized backup account in order to narrow the blast radius. This backup account acts as an isolated repository for the backup data of multiple applications. Usually, due to the principle of “least privilege access,” the application owner does not have a need for direct access to their backup data. The backup process is automated and controlled by the backup account.
Operational recovery
Replicating your database to another Region provides a means of disaster or operational recovery. In addition to replicating backups, Aurora also supports built-in replication in the same cluster, which can increase both performance and availability. However, this secondary copy is kept in sync with the primary one, so if an unwanted modification is made, that modification will be replicated to the secondary site. By backing up your databases, you can maintain a historical copy of the data. In addition, using AWS Backup vaults enables customers to create an immutable copy of the data that is stored securely and is enforced by policies configured by the customer.
Security
Integrating AWS Backup with Amazon Aurora enables customers to create immutable copies of their data. These copies can then be replicated to another account or to a different Region for isolation. Additionally, through the use of AWS Backup vaults, customers can enforce security policies for the database backups. This linked blog post is a valuable resource when preparing your AWS Identity and Access Management (IAM) strategy as it relates to using service control policies as guardrails.
Amazon Aurora supports encrypting your database and snapshots with a customer managed key or an AWS managed key. When a source database is encrypted, its snapshots are also encrypted. Aurora cluster snapshots are automatically encrypted with the same encryption key that was used to encrypt the source Amazon Aurora cluster. AWS Backup adds an additional layer of protection by encrypting a snapshot that is to be replicated across Regions using the target Region’s AWS Key Management Service (KMS) key. This is an enhancement to any security strategy since your keys can’t be taken over and reused across Regions.
Because of the central management of backup data, customers have the ability to separate the data protection role and associated IAM permissions from traditional database administration. This also helps organizations to apply the principles of “least privileged access” to their backup data management. Lastly, ransomware is a very real concern for nearly all digital organizations, and AWS Backup can help with securing your AWS environment from ransomware. AWS Backup vault further helps to enhance the overall security posture of your organization against ransomware.
Compliance
The backup account should also be able to control data retention and write-once, ready-many (WORM) requirements. AWS Backup Vault Lock provides this capability and can even make the backup data immutable to backup administrators.
Restore capabilities can be provided to application owners or to separate teams in a self-service and automated fashion. This provides security teams with the ability to separate roles and permissions and delegate duties, limiting the impact of human error. More specific compliance data can be found on the dedicated AWS compliance site for AWS Backup, as well as a growing number of AWS services and the ever-expanding regulatory frameworks.
To shrink the blast radius even further, AWS customers can enhance their backup strategy by replicating backups to a secondary Region, protecting themselves from Regional disasters. In all cases, it’s important to have a well-thought-out strategy with respect to AWS Organizations structure. Best practices for setting up your accounts in AWS Organizations can be found at Best Practices for Organizational Units with AWS Organizations.
Lastly, you can audit and report on the compliance of your backup processes with the AWS Backup Audit Manager. AWS Backup Audit Manager feeds detailed backup data into AWS Audit Manager so that customers can easily create controls and frameworks to gather evidence and present proof of backups.
Recovery point and recovery time objectives
A fundamental component of database recovery is understanding recovery time objectives (RTO) and recovery point objectives (RPO). These critical objectives for disaster recovery (DR) should bring databases online and to a point with minimal or no data loss. RPO is about the loss of data. It indicates the number of minutes or hours an organization can tolerate losing data before a bearable threshold is exceeded. On the other hand, RTO defines how quickly your database will be available soon after an event. Review the Reliability Pillar of the Well-Architected Framework, as it defines RTO and RPO in more detail. In addition, review the AWS blog on Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud for more details on reference architectures to achieve RTO and RPO.
RTO and RPO should include minimal downtime and data loss. However, there are trade-offs to consider. For example, the lower the RTO and RPO, the greater the cost and operational demand. However, a higher RTO and RPO could increase your time to recover and include more data loss. Therefore, you should consider RTO and RPO objectives that are appropriate for your workload and business SLAs.
When determining your backup schedule, you should consider backing up your database periodically and as often as necessary to minimize the consequences of data loss. Amazon Aurora automatically backs up your database volume and retains restore data for the length of the backup retention period. With automatic backups, the retention period is 1 day by default, but the retention period can be customized from 1 to 35 days when you create or modify the Aurora DB cluster. To retain backups for longer, take database snapshots of the data in your cluster volume. A snapshot will allow you to create a new DB cluster if needed.
Getting started
To begin using AWS Backup for the first time, navigate to the AWS Backup service and select Create Backup Plan within your AWS console. You have the option to build a new plan from scratch or create a plan using JSON, and customers should design a plan that best fits their use case. For simplicity in this demonstration, we’ll use a previously created template. Choose Daily-35day-Retention and give your backup plan a name.
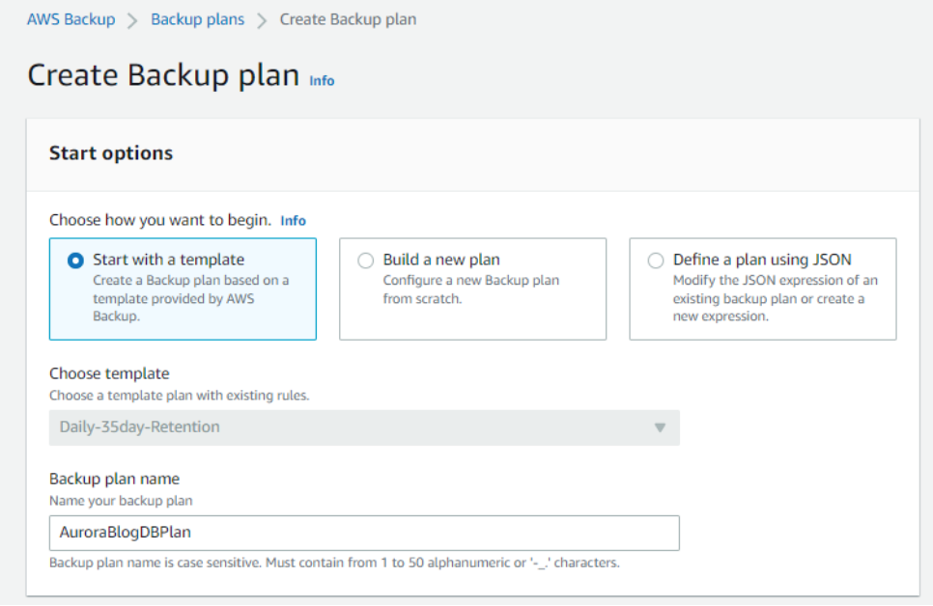
Figure 1: Create Backup plan by starting with a template or building a new plan from scratch.
Next, you can select an existing Backup rule, which allows you to customize the schedule, backup window, and lifecycle policies. Alternatively, you can create a new Backup rule as well as a new Backup vault to go along with it.
If you are creating a new vault, be sure to use the appropriate encryption key.
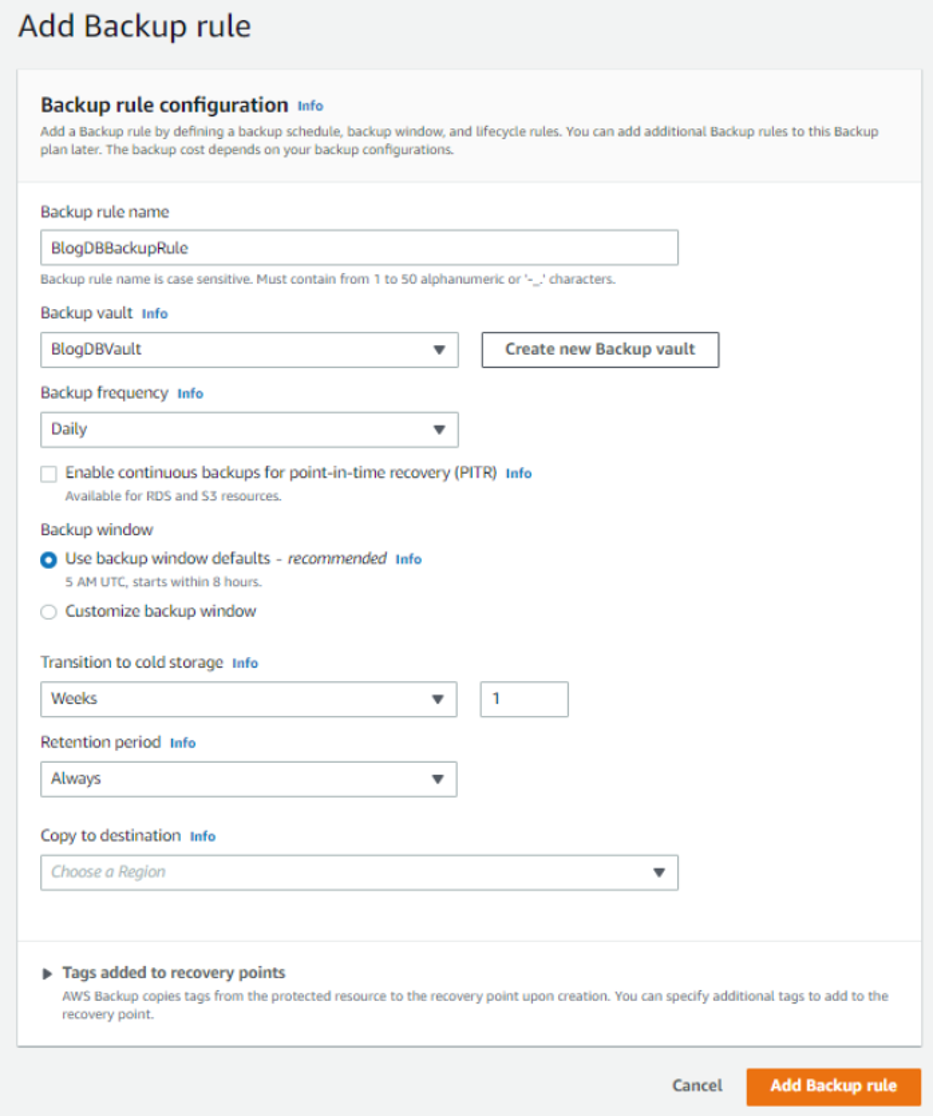
Figure 2: Add Backup rule by defining a backup schedule, backup window, and lifecycle rules.
So far, none of this has been specific to your Aurora cluster, so this Backup plan is reusable for any resources you choose to apply it to in the future. After creating your Backup plan, choose Assign resources in your console. At this stage, you have the ability to choose to assign all compatible resources in your account to your Backup plan in order to provide blanketed protection with the same plan, but for this use case, we will select Aurora specifically and provide our Cluster ID.
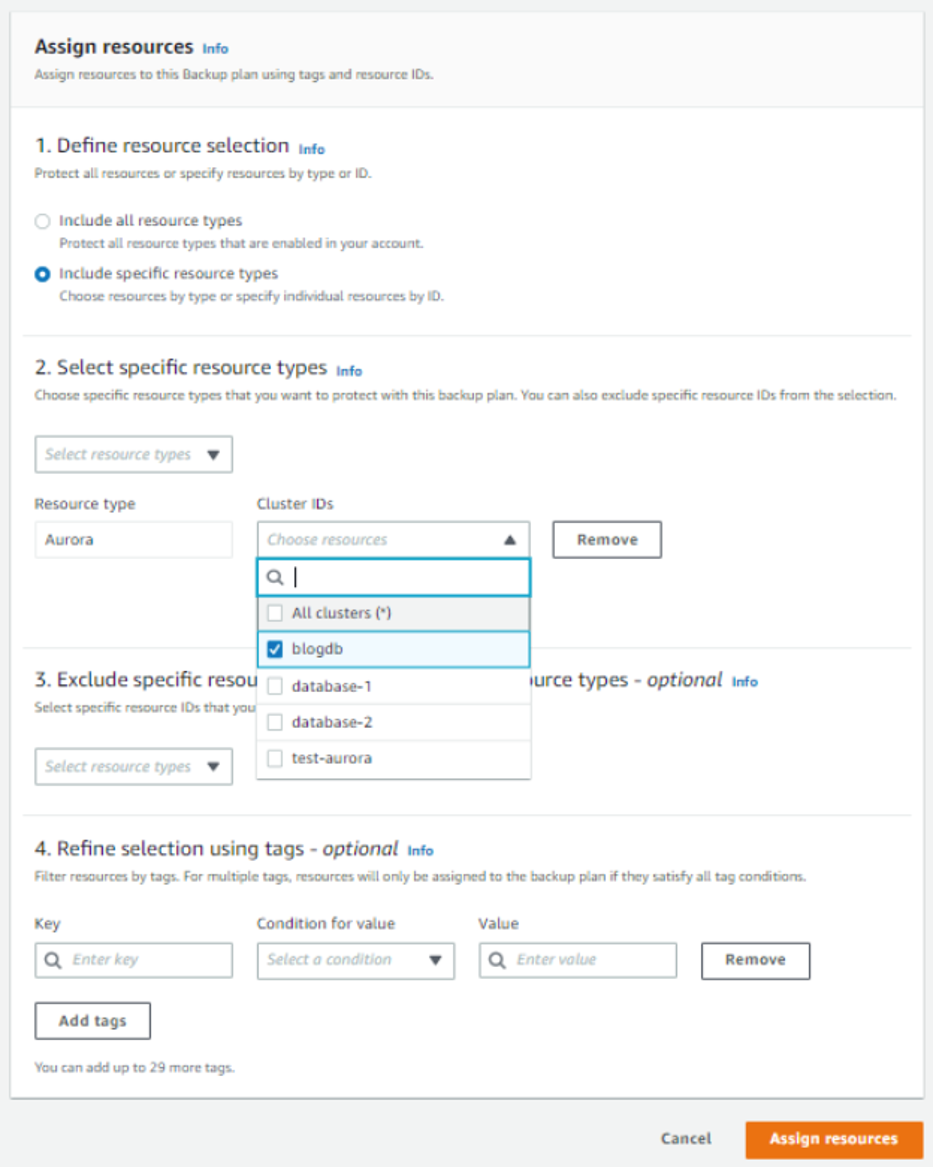
Figure 3: Assign resources to the backup plan.
Finally, confirm your assignment by selecting Assign resources. Back in your AWS Backup dashboard, you should be able to confirm all of these new constructs. Please note that if your new Backup rule causes the default DailyBackups rule to be unnecessary, you may be able to remove or modify that in the Backup plans section within the console.
Key considerations
Aurora supports both PostgreSQL and MySQL engines, and customers should select the appropriate engine based on their unique use cases and skill sets. Aurora is designed to provide greater than 99.99% availability for production databases, using a combination of six replicated copies of DB data across three Availability Zones. From a data protection perspective, customers can obtain all of the same benefits of centralized management that AWS Backup provides, regardless of the engine they choose.
Customers have the ability to create a backup plan using JSON and AWS Backup CLI and can apply similar, reusable principles whether they are backing up data from Aurora or the growing number of other services supported by AWS Backup.
While reporting on backup jobs programmatically, you can use methods like the observer solution to automate the delivery and visualization of backup status. It’s important to note that backups that were created with AWS Backup have names ending in awsbackup:AWS-Backup-job-number. This is useful to differentiate this data from traditional Aurora snapshots. For additional information specific to AWS Backup, see the AWS Backup Developer Guide. AWS Backup for Aurora does not yet provide incremental backup capability, so each backup in your plan will be a full copy.
Lastly, many customers also choose to use AWS Backup Audit Manager to provide automated reporting and audits of their backup environments. This is an additional important factor in maintaining compliance.
Limitations
Compatibility between Aurora and AWS Backup is available currently across all AWS Regions except China, and not all AWS Backup capabilities are supported yet when protecting Aurora clusters currently. Please compare the details in the AWS Backup Developer Guide.
At the time of this blog, Aurora provides the ability to take cross-Region or cross-account backups, but not both. For Aurora snapshots, AWS Backup only supports automating either cross-account or cross-Region copies due to how these services create their encryption keys. A separate blog has been written to show customers how to automate copying snapshots from one AWS account to another account in the same AWS Region and copy the backup to a different Region in the destination account. Amazon EventBridge makes it easy to automate this into a single process. Aurora cluster snapshots are already encrypted automatically using the same encryption key used on the original Aurora cluster. Snapshots of unencrypted Aurora clusters are also unencrypted. This is easy to enforce with tools such as AWS Config. There is no independent management of AWS Backup encryption for Aurora, but it is important to consider your encryption strategy if you will be taking advantage of data sharing across roles and accounts.
When integrating your AWS Backup strategy with the native backup capabilities of Aurora, please consider that initiation of backup jobs from the RDS console can cause conflicts that will result in Backup job expired before completion errors. An easy resolution to this is to increase the backup window length from within AWS Backup.
Cleaning up
To avoid incurring future charges, follow these steps to remove the example resources:
- Delete the source Aurora DB cluster and DB instances if you created them for this post. For instructions, see the Aurora User Guide.
- Delete the backup plans and recovery points. For instructions, see Clean up resources.
Conclusion
In this post, we discussed the most common reasons customers use AWS Backup to protect their Aurora databases. We also walked through how to set up your first backup for your databases and considerations to keep in mind for your database backups. Customers should build a strategy that incorporates both backup and replication to meet a wide array of business service level agreements. Customers can build more resilient architectures which incorporate automation, granular separation of duties, and reproducible policies which can be monitored and audited.
To learn more about AWS Backup, refer to the AWS Backup documentation. If you have feedback about this post, please submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Backup forum or contact AWS Support.