AWS Database Blog
The role of vector databases in generative AI applications
August, 2024: This post has been updated to reflect advances in technology and new features AWS released, to help you on your generative AI journey.
Generative artificial intelligence (AI) has captured our imagination and is transforming industries with its ability to answer questions, write stories, create art, and generate code. AWS customers are increasingly asking us how they can best take advantage of generative AI in their own businesses. Most have accumulated a wealth of domain-specific data (financial records, health records, genomic data, supply chain, and so on), which provides them with a unique and valuable perspective into their business and broader industry. This proprietary data is the differentiator for your generative AI strategy.
At the same time, many customers are wondering how vector databases fit into their overall data strategy. In this post, we describe the role of vector databases in generative AI applications, and how AWS solutions can help you harness the power of generative AI. At AWS, we believe customers should be able to use the skills and tools they already have to move fast. We are adding vector capabilities to all our database services in the fullness of time, so you can store vector datasets where your data is, simplify your application architecture, and use tried, tested, and familiar tools. In this post, when we say vector database, or vector data store, we simply mean a database with vector capabilities, but it doesn’t have to only provide vector capabilities.
Generative AI applications
At the heart of every generative AI application is a large language model (LLM). An LLM is a machine learning (ML) model trained on a large body of content—such as all the content accessible on the internet. Foundation models (FMs) are LLMs that can perform a wide range of disparate tasks with a high degree of accuracy based on input prompts. To make it straightforward for you to build and scale generative AI applications with FMs, Amazon Bedrock makes models from AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon accessible through an API. If you need more flexibility to build upon FMs, Amazon SageMaker JumpStart provides a variety of pre-trained, open source, and proprietary FMs, such as Stability AI’s Text2Image model, which can generate photorealistic images using a text prompt, or Hugging Face’s Text2Text Flan T-5 model for text generation.
Although a generative AI application relying purely on an FM will have access to broad real-world knowledge, it needs to be customized to produce accurate results on topics that are domain specific or specialized. Because the dataset used to train an FM was collected up to a specific point in time (a knowledge cutoff date), you may also need to customize a generative AI application to provide the FM with more up-to-date information, past the knowledge cutoff date. Otherwise, hallucinations (results that lack accuracy but look correct with confidence) can occur more frequently if the interaction is more specialized or you’re seeking more current information. So how can you customize your generative AI application for domain specificity and up-to-date information?
Adding domain specificity and up-to-date information to generative AI applications
At its core, the FM infers the next token based on a set of input tokens. A token in this case refers to any element with semantic meaning, like a word or phrase in text generation. The more contextually relevant input tokens you provide, the higher the likelihood that the next token inferred is also contextually relevant. Therefore, the prompt used to query the FM should contain the original input tokens, plus as much contextually relevant data as reasonable. Because FMs have limits for the maximum number of input tokens they can accept, and there are typically both performance and cost implications to the size of the input prompt, you need to factor these considerations into the amount of contextually relevant data you can enrich the prompt with. The right balance to strike is something unique to the use case and goals of your generative AI application.
Contextually relevant data typically comes from your internal databases, data lakes, or unstructured data or document stores—the data stores that host your domain-specific data or knowledge. These data stores are generically called knowledge bases. Retrieval Augmented Generation (RAG) is the process for retrieving facts from these knowledge bases to ground LLMs with up-to-date, accurate, and insightful data, supplied in the prompt. With this process, you can enrich the prompt by appending additional domain-specific data from these data stores. You can retrieve data using traditional queries, which is useful for including contextually personalized data into the prompt, like user profile information (we call this situational context). However, vector databases help you engineer your prompts with semantically relevant inputs. In practice, you will typically engineer a prompt with both situational context and semantically similar data.
For generative AI usage, the domain-specific data you plan to use for semantic context must be encoded as a set of elements, each expressed internally as a vector. The vector contains a set of numeric values across a set of dimensions (array of numbers). The following figure illustrates an example of transforming context data into semantic elements and then vectors.
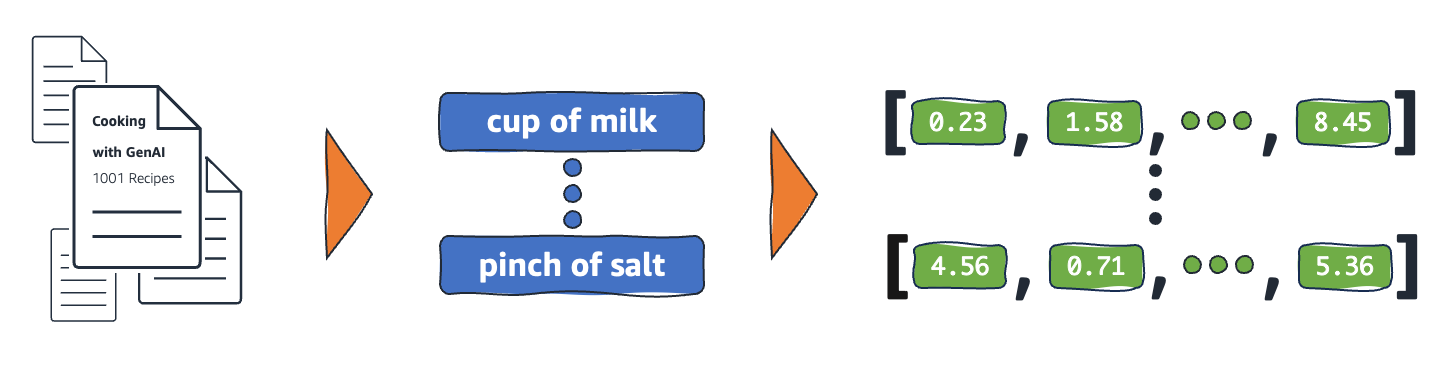
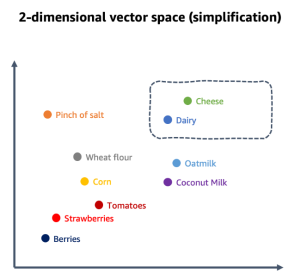
These numeric values are used to map elements in relation to each other in a multi-dimensional vector space. When the vector elements are semantic (they represent a form of meaning), the proximity becomes an indicator for contextual relationship. Used in this way, such vectors are referred to as embeddings, although in the generative AI space, both terms are used interchangeably. For example, the semantic element for “Cheese” may be put in proximity to the semantic element for “Dairy” in a multi-dimensional space representing the data domain context of groceries or cooking. Depending on your specific domain context, a semantic element may be a word, phrase, sentence, paragraph, whole document, image, or something else entirely. You split your domain-specific dataset into meaningful elements that can be related to each other in a process called chunking. For example, the following figure illustrates a simplified vector space for a context on cooking with the chunks being individual words (in practice, chunks containing tens to hundreds of tokens are typical).
As a result, to produce the relevant context for the prompt, you need to query a database and find elements that are closely related to your inputs in the vector space created by the embeddings. This is called semantic search, and also referred to as vector search (although these terms are used interchangeably in the generative AI space, they are not equivalents). A vector database is a system that allows you to store and query vectors at scale, with efficient nearest neighbor query algorithms and appropriate indexes to improve data retrieval. Many commonly used database systems offer these vector capabilities along with the rest of their functionality. One advantage of storing your domain-specific datasets in a database with vector capabilities is that your vectors will be located close to the source data. You can enrich vector data with additional metadata, without having to query external databases, and you can simplify your data processing pipelines.
A straightforward way to get started with semantic search is using Knowledge Bases for Amazon Bedrock. With Knowledge Bases for Amazon Bedrock, you simply store the documents you want to use for semantic context in an Amazon Simple Storage Service (Amazon S3) bucket, select a target vector database, and let Amazon Bedrock handle the process of chunking, generating embeddings, storing them, and querying the database. At the time of writing, Knowledge Bases for Amazon Bedrock supports the vector engine for Amazon OpenSearch Serverless, Amazon Aurora PostgreSQL-Compatible Edition, Pinecone, Redis Cloud (Enterprise), and MongoDB Atlas Database as vector databases.
You can store and query embeddings in a variety of AWS database services, if you prefer to have more control over the chunking, vectorization, indexing, and querying of the datasets you use for context. However, you will need to implement and manage your own data pipelines for chunking and vectorization. AWS database services with vector capabilities include:
- The Aurora PostgreSQL-Compatible relational database, with the pgvector open source vector similarity search extension
- Amazon OpenSearch Service, a distributed search and analytics service, with the k-nearest neighbor (k-NN) plugin, and the vector engine for OpenSearch Serverless
- The Amazon Relational Database Service (Amazon RDS) for PostgreSQL relational database, with the pgvector extension
- Amazon MemoryDB, a Redis open source software compatible, durable, in-memory database service for ultra-fast performance
- Amazon Neptune Analytics, a memory-optimized graph database engine for analytics
- Amazon DocumentDB (with MongoDB compatibility), a fast, scalable, highly available, and fully managed document database service
Embeddings should be stored close to your source data. As a result, where you store your data—as well as familiarity with these database technologies, the scale in terms of vector dimensions, number of embeddings, and performance needs—will determine which option is right for you. But first, let’s understand how RAG works and how you apply vector databases in RAG.
Using vector databases for RAG
You can use embeddings to improve the accuracy of your generative AI application. The following diagram illustrates this data flow.
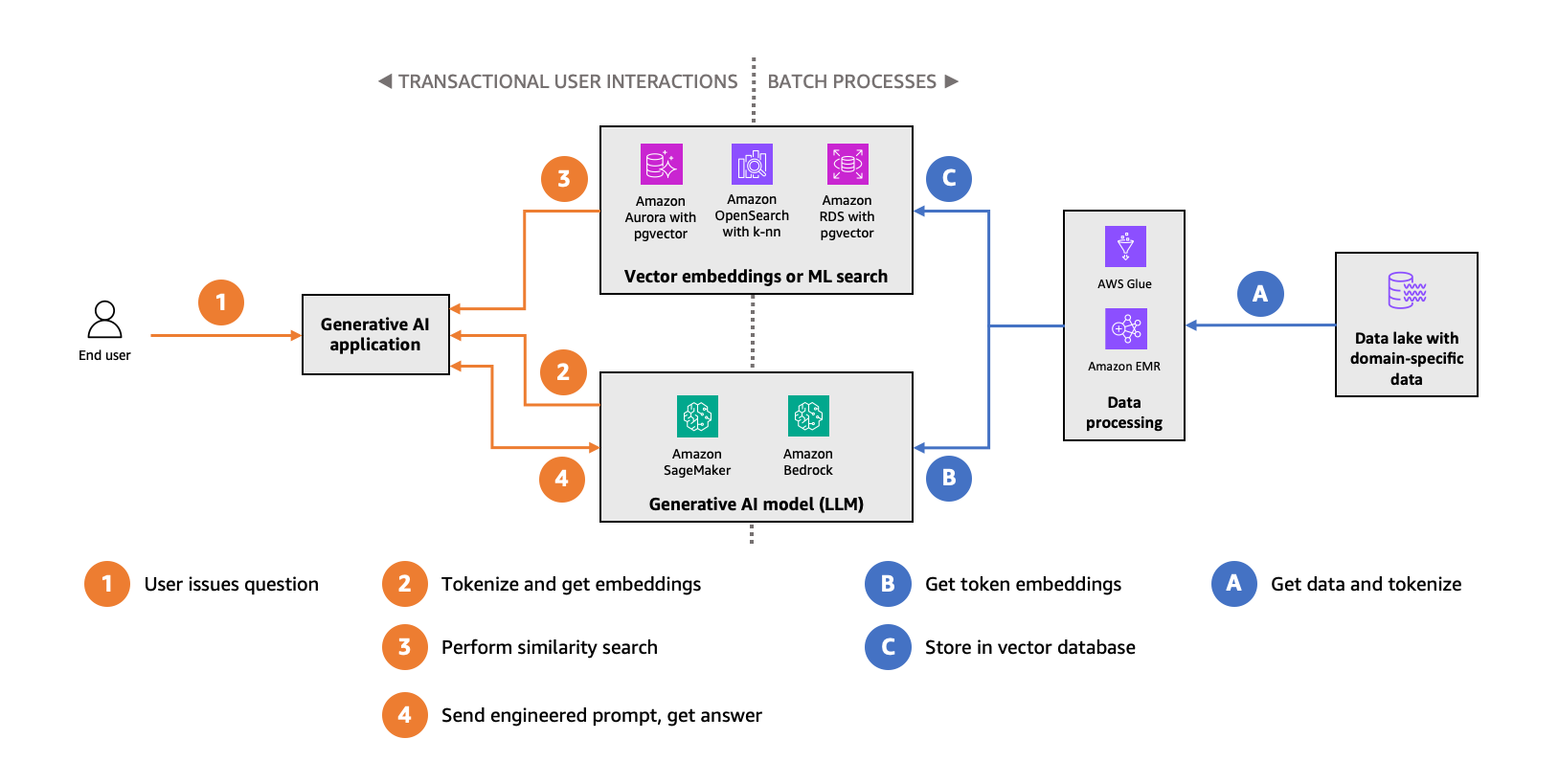
You take your domain-specific dataset (the right side of the preceding figure, depicted in blue), chunk it into semantic elements, and use a specialized LLM optimized specifically for creating embeddings to compute the vectors for the chunks. The Amazon Titan Text Embedding v2 model is a popular choice for Amazon Bedrock customers. Then you store these vectors in a vector database, which will enable you to perform similarity search.
In your generative AI application (left side of the preceding figure, depicted in orange), you take the end-user-provided input, generate a vector for it using the same embeddings model you used earlier, and query the vector database for the nearest neighbors in the vector space for the input elements. The database will provide you with contextually similar semantic embeddings, for which you append the original chunk contents to your engineered prompt. This process will further ground the FM into your domain-specific context, increasing the likelihood that the FM output is accurate and relevant to that context.
Performing similarity searches in your vector database, in the critical path of end-users, uses concurrent read queries. Batch processes to populate the vector database with embeddings and keep up with data changes are mostly data writes. Aspects of this usage pattern along with previously mentioned considerations, like familiarity and scale, determine which AWS database service is right for you.
Vector database considerations
The usage pattern we described also leads to some unique and important considerations for vector databases.
The volume of domain-specific data you want to use and the process you use to split up that data into chunks will determine the number of embeddings your vector database needs to support. As your domain-specific data grows and changes over time, your vector database also has to accommodate that growth. This has impact on indexing efficiency and performance at scale. It’s not uncommon for domain-specific datasets to result in hundreds of millions—even billions—of embeddings. There are many chunking strategies, applicable to a variety of data types, ranging from fixed size to content-aware options. For example, the Natural Language Toolkit (NLTK) provides several content-aware tokenizers you can use. The chunk size you choose also matters, affecting query performance, generation of embeddings, and even inference cost, because many FMs have the number of input and output tokens as a cost metric. Ultimately, the right chunking strategy depends on what you consider the unit of a semantic element in your domain-specific dataset to be—as previously mentioned, it could be a word, phrase, paragraph of text, entire document, or any subdivision of your data that holds independent meaning.
The number of dimensions for the embedding vectors is another important factor to consider. Different FMs produce vectors with different numbers of dimensions. For example, the Amazon Titan Text Embedding v2 model produces vectors with 1,024 dimensions, and Hugging Face Falcon-40B vectors have 8,192 dimensions. The more dimensions a vector has, the richer the context it can represent—up to a point. You will eventually see diminishing returns and increased query latency. This leads to the curse of dimensionality (objects appear sparse and dissimilar). To perform semantic similarity searches, you generally need vectors with dense dimensionality, and you may need to reduce the dimensions of your embeddings for your database to handle such searches efficiently.
Another consideration is whether you need exact similarity search results. Indexing capabilities in vector databases will speed up similarity search considerably, but they will also use an approximate nearest neighbor (ANN) algorithm to produce results. ANN algorithms provide performance and memory efficiencies in exchange for accuracy. They can’t guarantee that they return the exact nearest neighbors every time.
Finally, you need to consider data governance. Your domain-specific datasets likely contain highly sensitive data, such as personal data or intellectual property. With your embeddings close to your existing domain-specific datasets, you can extend your access, quality, and security controls to your vector database, simplifying operations. In many cases, it won’t be feasible to strip away such sensitive data without affecting the semantic meaning of the data, which in turn reduces accuracy. Therefore, it’s important to understand and control the flow of your data through the systems that create, store, and query embeddings.
For a more detailed guide on which vector database to select for your generative AI applications, refer to Key considerations when choosing a database for your generative AI applications.
Using Aurora PostgreSQL-Compatible or Amazon RDS for PostgreSQL with pgvector
You should strongly consider using Aurora PostgreSQL-Compatible with the pgvector extension for your vector store if you are already heavily invested in relational databases, especially PostgreSQL, and have a lot of expertise in that space. Amazon Relational Database Service (Amazon RDS) for PostgreSQL can also be a great choice if you need to use specific community versions of PostgreSQL.
Pgvector, an open source, community-supported PostgreSQL extension, expands PostgreSQL with a vector data type called vector, three query operators for similarity searching (Euclidean, negative inner product, and cosine distance), and both Hierarchical Navigable Small World (HNSW) and IVFFlat (inverted file with stored vectors) indexing mechanism for vectors to perform faster approximate distance searches.
Amazon Aurora Serverless v2, an on-demand, auto scaling configuration that can adjust the compute and memory capacity of your DB instances automatically based on load, is also integrated with Knowledge Bases for Amazon Bedrock. This option can simplify your operations by abstracting away the vectorization process and reducing the need for database capacity management.
You can scale the workload for similarity search queries (reads) horizontally by adding read replicas within Aurora DB clusters, or attaching read replica DB instances to your RDS DB instances. Additionally, Amazon Aurora Machine Learning (Aurora ML) is a feature you can use to make calls to ML models hosted in Amazon Bedrock or Amazon SageMaker through SQL functions. You can use it to make calls to your FMs to generate embeddings directly from your database. You can package these calls into stored procedures or integrate them with other PostgreSQL capabilities, such that the vectorization process is completely abstracted away from the application. With the batching capabilities built into Aurora ML, you may not even need to export the initial dataset from Aurora in order to transform it to create the initial set of vectors.
Using OpenSearch Service with the k-NN plugin and the vector engine for OpenSearch Serverless
OpenSearch Service is a distributed search and analytics suite, based on the OpenSearch open source community project. Due to the distributed nature of the service, it’s a great choice for use cases where your vector indexes need to scale horizontally, allowing you to handle more throughput for storing embeddings and performing similarity searches. It’s also a great choice when you want to have deeper control over the method and algorithms used to perform searches. Search engines are designed for low-latency, high-throughput querying, trading off transactional behavior to achieve that. OpenSearch Service is highly effective if you need to combine semantic similarity search with keyword search use cases into hybrid search.
The k-NN plugin expands OpenSearch, with the custom knn_vector data type, enabling you to store embeddings in OpenSearch indexes. The plugin also provides three methods to perform k-NN similarity searches: Approximate k-NN, Script Score k-NN (exact), and the Painless extensions (exact). OpenSearch includes the Non-Metric Space Library (NMSLIB) and Facebook AI Research’s FAISS library. You can use different search algorithms for distance to find the best one that meets your needs. This plugin is also available in OpenSearch Service. For more information about these features, refer to Amazon OpenSearch Service’s vector database capabilities explained.
The vector engine for OpenSearch Serverless is an on-demand serverless configuration that removes the operational complexities of provisioning, configuring, and tuning OpenSearch domains. It is integrated with Knowledge Bases for Amazon Bedrock so you can implement prompt engineering into your generative AI applications, without needing advanced expertise in ML or vector technology.
The neural search plugin enables the integration of ML language models directly into your OpenSearch workflows. With this plugin, OpenSearch automatically creates vectors for the text provided during ingestion and search. It then seamlessly uses the vectors for search queries. This can simplify similarity search tasks used in RAG.
Using vector search for MemoryDB
MemoryDB is a Redis OSS-compatible, durable, in-memory database service for ultra-fast performance. It delivers the fastest vector search performance at the highest recall among popular vector databases on AWS. You can achieve single-digit millisecond latencies (p99) at the highest levels of recall. MemoryDB is ideal for use cases requiring vector search in real time. It is designed for users familiar with the Redis API (7.0-compatible) who want to durably store embeddings along with a primary database in a Redis-compatible data store.
MemoryDB supports HNSW indexing, and provides configurable Euclidean, cosine, and dot product distance metrics, as well as configurable recall. It scales to clusters with up to 419 GiB of memory.
Using Neptune Analytics
Neptune Analytics is a memory-optimized, analytical graph database engine that complements Amazon Neptune Database, a purpose-built, cloud-centered operational database engine. Using Neptune Analytics for vector search is optimal for GraphRAG use cases and use cases requiring a higher-level understanding of large, highly connected datasets. GraphRAG, implemented using Neptune Analytics, enhances generative AI applications using topological knowledge (such as lineage, provenance, and influence) to provide more accurate outcomes.
With Neptune Analytics, you can combine vector similarity search with graph algorithms and graph traversals in the same query to retrieve context alongside top-K results. Neptune Analytics uses HNSW-based indexing, implements a distance metric based on the L2 norm, and can be up to 80 times faster than existing graph analytical solutions.
Additionally, the Neptune ML feature makes it possible to build, train, and use ML models on large graphs, using graph neural network technology. With this feature, you can generate vector embeddings directly in Neptune.
Using vector search for Amazon DocumentDB
Amazon DocumentDB is a cloud-centered document database, compatible with the MongoDB 3.6, 4.0, and 5.0 API versions, and vector search is available in Amazon DocumentDB 5.0 and onwards. If you want to use MongoDB APIs in your RAG implementation, vector search for Amazon DocumentDB is the right choice.
Amazon DocumentDB provides HNSW and IVFFlat indexing, and multiple distance metrics on the same field. It supports configurable distance metrics (cosine, Euclidean, and dot product) and configurable recall for both HNSW and IVFFlat indexes. You can also run complex hybrid searches through rich aggregation pipelines and native text search.
Amazon DocumentDB integrates natively with Amazon SageMaker Canvas for no-code use cases, and has a zero-ETL integration with OpenSearch Service, which is useful for vector search edge cases where advanced ranking and search features are needed.
Finally, all the database engines with vector capabilities described in this post are well supported in both LangChain and LlamaIndex. LangChain is a popular framework for developing data-aware, agent-style applications based on LLMs; LlamaIndex is a simple and flexible data framework for connecting custom data sources to LLMs, simplifying RAG architectures.
Summary
Embeddings should be stored and managed close to your domain-specific datasets, which reduces your operational burden and cost and enables you to get started faster. You can combine vector queries with additional metadata without using additional, external data sources. Your data is also not static, but changes over time, and storing the embeddings near your source data simplifies your data pipelines for keeping the embeddings up to date.
Aurora PostgreSQL-Compatible, the vector engine for OpenSearch Serverless, OpenSearch Service, Amazon RDS for PostgreSQL, MemoryDB, Neptune Analytics, and Amazon DocumentDB are great choices for your vector database needs, but which solution is right for you will ultimately depend on your use case and priorities. If your database of choice doesn’t have vector capabilities, the options discussed in this post span the spectrum of familiarity with SQL and NoSQL and are straightforward to pick up without a lot of operational overhead. No matter which option you choose, your vector database solution needs to sustain the concurrent throughput dispatched by the application. You should validate your solution at scale with a set of embeddings based on the full dataset you want to use, so the similarity search response latencies meet your expectations.
On a final note, keep in mind technology is evolving rapidly in this space, and although we will make every effort to update our guidance as things change, the recommendations in this post may not be universally applicable.
Get started building generative AI applications on AWS today! Discover the tools and features AWS offers to help you innovate faster, and reinvent customer experiences.
About the authors
 G2 Krishnamoorthy is VP of Analytics, leading AWS data lake services, data integration, Amazon OpenSearch Service, and Amazon QuickSight. Prior to his current role, G2 built and ran the Analytics and ML Platform at Facebook/Meta, and built various parts of the SQL Server database, Azure Analytics, and Azure ML at Microsoft.
G2 Krishnamoorthy is VP of Analytics, leading AWS data lake services, data integration, Amazon OpenSearch Service, and Amazon QuickSight. Prior to his current role, G2 built and ran the Analytics and ML Platform at Facebook/Meta, and built various parts of the SQL Server database, Azure Analytics, and Azure ML at Microsoft.
 Rahul Pathak is VP of Relational Database Engines, leading Amazon Aurora, Amazon Redshift, and Amazon QLDB. Prior to his current role, he was VP of Analytics at AWS, where he worked across the entire AWS database portfolio. He has co-founded two companies, one focused on digital media analytics and the other on IP-geolocation.
Rahul Pathak is VP of Relational Database Engines, leading Amazon Aurora, Amazon Redshift, and Amazon QLDB. Prior to his current role, he was VP of Analytics at AWS, where he worked across the entire AWS database portfolio. He has co-founded two companies, one focused on digital media analytics and the other on IP-geolocation.
 Vlad Vlasceanu is the Worldwide Tech Leader for Databases at AWS. He focuses on accelerating customer adoption of purpose-built databases, and developing prescriptive guidance mechanisms to help customers select the right databases for their workloads. He is also the leader of the database expert community within AWS, where he helps develop Solutions Architects’ database skills and enables them to deliver the best database solutions for their customers.
Vlad Vlasceanu is the Worldwide Tech Leader for Databases at AWS. He focuses on accelerating customer adoption of purpose-built databases, and developing prescriptive guidance mechanisms to help customers select the right databases for their workloads. He is also the leader of the database expert community within AWS, where he helps develop Solutions Architects’ database skills and enables them to deliver the best database solutions for their customers.