AWS Machine Learning Blog
Amazon Personalize can now create up to 50% better recommendations for fast changing catalogs of new products and fresh content
This blog post was last reviewed or updated April, 2022 with database schema updates.
Amazon Personalize now makes it easier to create personalized recommendations for fast-changing catalogs of books, movies, music, news articles, and more, improving recommendations by up to 50% (measured by click-through rate) with just a few clicks in the AWS console. Without needing to change any application code, Amazon Personalize enables customers to include completely new products and fresh content in their usual recommendations, so that the best new products and content is discovered, clicked, purchased, or consumed by end-users an order of magnitude more quickly than other recommendation systems.
Many catalogs are fast moving with new products and fresh content being continuously added, and it is crucial for businesses to help their users discover and engage with these products or content. For example, users on a news website expect to see latest personalized news, users consuming media via video-on-demand services expect to be recommended the latest series and episodes they might like. Meeting these expectations by showcasing new products and content to users helps keep the user experience fresh, and aids in sales either through direct conversion, or through subscriber conversion and retention. However, there are usually way too many new products in fast moving catalogs to make it feasible to showcase each of them to every user. It makes much more sense to personalize the user experience by matching these new products with users, based on their interests and preferences. Personalization of new products is inherently hard due to absence of data about past views, clicks, purchases, and subscriptions for these products. In such a scenario, most recommender systems only make recommendations for products they have sufficient past data about, and ignore the products that are new to the catalog.
With today’s launch, Amazon Personalize can help customers create personalized recommendations for new products and fresh content for their users, in matter of a few clicks. Amazon Personalize does this by recommending new products to users who have positively engaged (clicked, purchased, etc.) with similar products in the past. If users positively engage with the recommended new products, Personalize further recommends them to more users with similar interests. At Amazon, this capability has been in use since many years for creating product recommendations, and has resulted in 21% higher conversions compared to recommendations that do not include new products. This capability is now available in Amazon Personalize at no additional cost as part of its existing deep learning based algorithms that have been perfected over years of development and use at Amazon. It’s a win-win situation for customers, as they can benefit from this new capability at no extra cost, without losing out on the highly relevant recommendations that they already create through Amazon Personalize.
Amazon Personalize makes it easy for customers to develop applications with a wide array of personalization use cases, including real time product recommendations and customized direct marketing. Amazon Personalize brings the same machine learning technology used by Amazon.com to everyone for use in their applications – with no machine learning experience required. Amazon Personalize customers pay for what they use, with no minimum fees or upfront commitment. You can start using Amazon Personalize with a simple three step process, which only takes a few clicks in the AWS console, or a set of simple API calls. First, point Amazon Personalize to user data, catalog data, and activity stream of views, clicks, purchases, etc. in Amazon S3 or upload using a simple API call. Second, with a single click in the console or an API call, train a custom private recommendation model for your data (CreateSolution). Third, retrieve personalized recommendations for any user by creating a campaign, and using the GetRecommendations API.
The rest of this post walks you through this process in greater detail and discusses the recommended best practices.
Adding your data to Personalize
For this post, we create a dataset group with an interaction dataset and item dataset (item metadata). For instructions on creating a dataset group, see Getting Started (Console).
Creating an interaction dataset
To create an interaction dataset, use the following schema and import the file bandits-demo-interactions.csv, which is a synthetic movie rating dataset:
You can now optionally add impression information to Amazon Personalize. Impressions are the list of items that were visible to the user when they interacted with a particular item. The following screenshot shows some interactions with impression data.

The impression is represented as an ordered list of item IDs that are pipe separated. The first row of the data in the preceding screenshot shows that when user_id 1 rated item_id 1270, they had items 1270, 1...9 in that order visible in the UX. The contrast between which items were recommended to the user and which they interacted with helps us generate better recommendations.
Amazon Personalize has two modes to input impression information:
- Explicit impressions – Impressions that you manually record and send to Personalize. The preceding example pertains to explicit impressions.
- Implicit impressions – The list of items recommended for recommendations users receive from Amazon Personalize
Amazon Personalize now returns a RecommendationID for each set of recommendations from the service. If you do not change the order or content of the recommendations when generating you user experience you can reference the impression through the RecommendationID without needing to send a list of ItemIDs (explicit impressions). If you provide both explicit and implicit impressions for an interaction, the explicit impression takes precedence. You can also send both implicit and explicit recommendations via the putEvents API. Please see our documentation for more details.
Creating an item dataset
You follow similar steps to create an item dataset and import your data using bandits-demo-items.csv, which has metadata for each movies. We use an optional reserved keyword CREATION_TIMESTAMP for the item dataset, which helps Amazon Personalize compute the age of the item and adjust recommendations accordingly. When using your own data to model provide the timestamp when the item was first available to your user in this field. We infer the age of an item from the reference point of the latest interaction timestamp in your dataset.
If you don’t provide the CREATION_TIMESTAMP, the model infers this information from the interaction dataset and uses the timestamp of the item’s earliest interaction as its corresponding release date. If an item doesn’t have an interaction, its release date is set as the timestamp of the latest interaction in the training set and it is considered a new item with age 0.
Our dataset for this post has 1,931 movies, of which 191 have a creation timestamp marked as the latest timestamp in the interaction dataset. These newest 191 items are considered cold items and have a label number higher than 1800 in the dataset. The schema of the item dataset is as follows:
Training a model
After the dataset import jobs are complete, you’re ready to train your model.
- On the Solutions tab, choose Create solution.
- Choose the new
aws-user-personalizationrecipe.
This new recipe effectively combines deep learning models (RNNs) with bandits to provide you more accurate user modeling (high relevance) and effective exploration.
- Leave the Solution configuration section at its default values, and choose
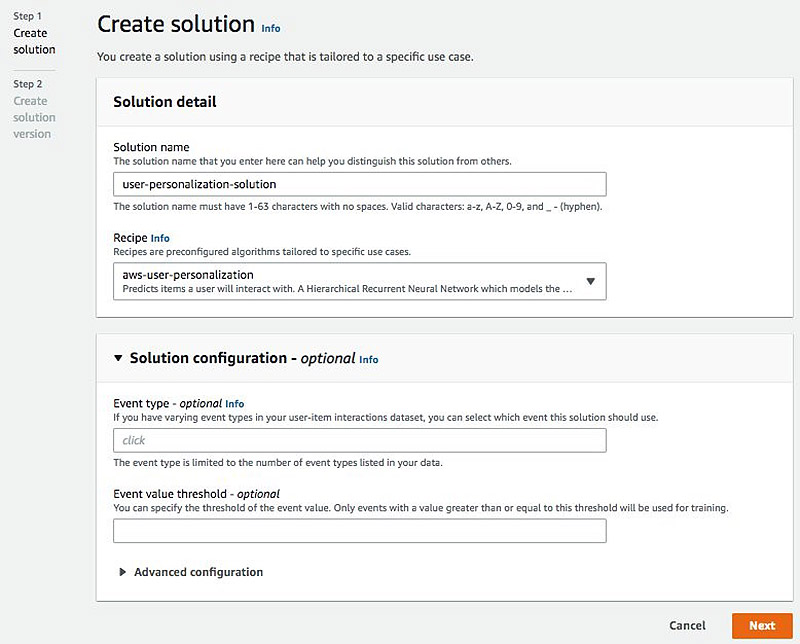
- On the Create solution version page, choose Finish to start training.
When the training is complete, you can navigate to the Solution Version Overview page to see the offline metrics. In certain situations, you might see a slight drop on accuracy metrics (such as mrr or precision@k) and on coverage compared to models trained on the HRNN-Metadata recipe. This is because recommendation made by the new aws-user-personalization recipe isn’t solely based on exploitation, and it may sacrifice short-term interest for the long-term reward. The offline metrics are computed using the default values of parameters (explorationWeight, explorationItemAgeCutoff), which impacts item exploration. You can find more details on these in the following section.
After several rounds of retraining, you should see the accuracy metrics and item coverage increase, and the new aws-user-personalization recipe should outperform the exploitation-based HRNN-Metadata recipe.
Creating a campaign
In Amazon Personalize, you use a campaign to make recommendations for your users. In this step, you create two campaigns using the solution you created in the previous step and demonstrate the impact of different amounts of exploration.
To create a new campaign, complete the following steps:
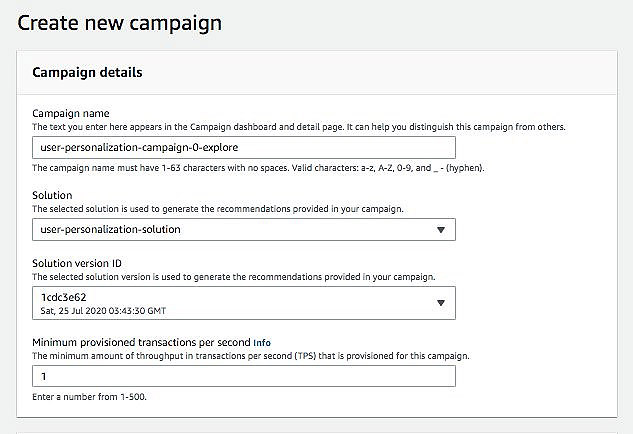
- On the Campaigns tab, choose Create Campaign.
- For Campaign name, enter a name.
- For Solution, choose user-personalization-solution.
- For Solution version ID, choose the solution version that uses the
aws-user-personalizationrecipe.
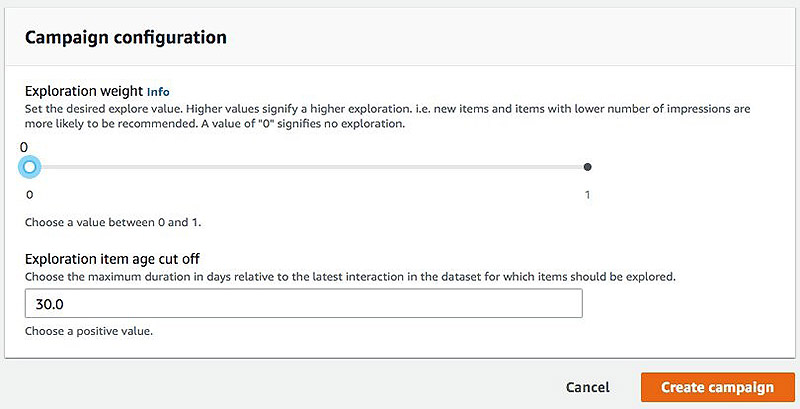
You now have the option of setting additional configuration for the campaign, which allows you to adjust the exploration Amazon Personalize does for the item recommendations and therefore adjust the results. These settings are only available if you’re creating a campaign whose solution version uses the user-personalization recipe. The configuration options are as follows:
- explorationWeight – Higher values for
explorationWeightsignify higher exploration; new items with low impressions are more likely to be recommended. A value of 0 signifies that there is no exploration and results are ranked according to relevance. You can set this parameter in a range of [0,1] and its default value is 0.3. - explorationItemAgeCutoff – This is the maximum duration in days relative to the latest interaction(event) timestamp in the training data. For example, if you set
explorationItemAgeCutoffto 7, the items with an age over or equal to 7 days aren’t considered cold items and there is no exploration on these items. You may still see some items older than or equal to 7 days in the recommendation list because they’re relevant to the user’s interests and are of good quality even without the help of the exploration. The default value for this parameter is 30, and you can set it to any value over 0.
To demonstrate the effect of exploration, we create two campaigns.
- For the first campaign, set Exploration weight to 0.
- Leave Exploration item age cut off at its default of 30.0.
- Choose Create campaign.
Repeat the preceding steps to create a second campaign, but give it a different name and change the exploration weight to 1.
Getting recommendations
After you create or update your campaign, you can get recommended items for a user, similar items for an item, or a reranked list of input items for a user.
- On the Campaigns detail page, enter the user ID for your user personalization campaign.
The following screenshot shows the campaign detail page with results from a GetRecommendations call that include the recommended items and the recommendation ID, which you can use as an implicit impression. The service interprets the recommendation ID in training.
- Enter a user ID that has interactions in the interactions dataset. For this post, we get recommendations for user ID 1.
- On the campaign detail page of the campaign that has an exploration weight of 0, choose the Detail
- For User ID, enter
1. - Choose Get recommendations.
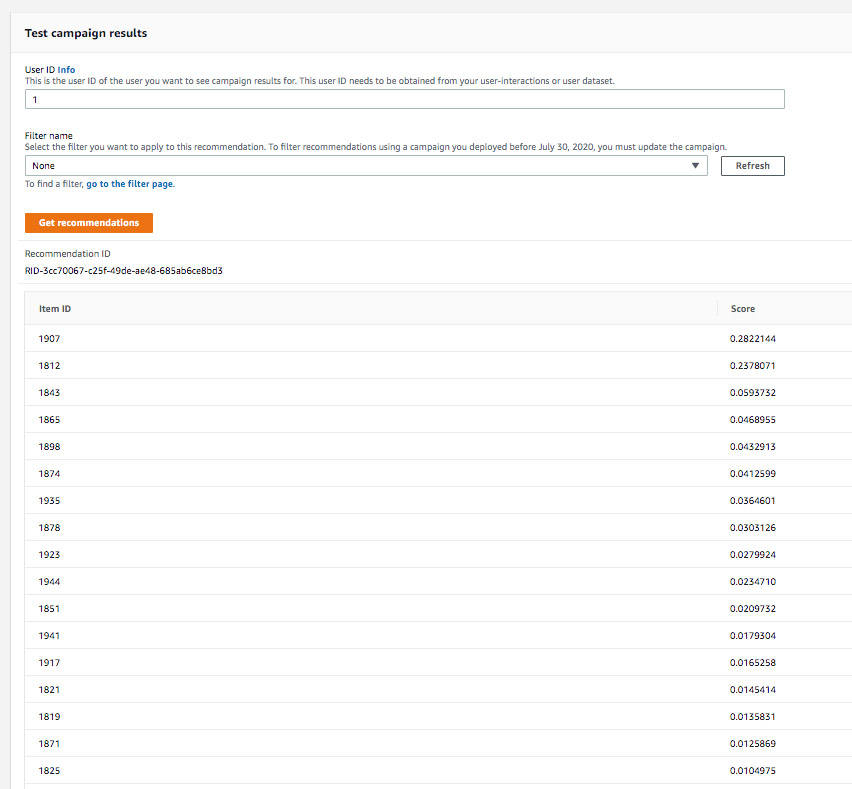
The following image is for campaigns with an exploration weight of 0; we can see that the recommendation items are old items, and users have already seen or rated those movies.

The next image shows recommendation results for the same user but for a campaign where we set the exploration weight to 1. This results in a higher proportion of movies that were recently added and that few users have rated being recommended. Furthermore, the trade-off between the relevance (exploitation) and exploration is adjusted automatically depending on the coldness of the new items and as new feedback from users is leveraged.
Automatic updates
After you create a solution version using ‘Full’ training on ‘aws-user-personalization’ recipe Amazon Personalize will automatically keep the model up to date for you. Amazon Personalize updates the model to include the latest item metadata, new items and adjusts the exploration according to implicit feedback from users. New interactions against explored items hold important feedback on the quality of the item, which are used to continually update exploration on the items. Updates happen automatically every 2 hours and only happen if you provide new item or interactions data since the last update. There is no cost associated with such updates.
You can also choose to update the solutionVersion(model) manually if you want more frequent updates. To do so you can call the createSolutionVersion API with trainingMode set to UPDATE. This updates the model with the latest item information and adjusts the exploration according to implicit feedback from the users. When manually updating you will need to also update the campaign with the new solutionVersion you have created.
The automatic updates or manually triggered updates are not equivalent to training a model. Training is done when you create a new solutionVersion while setting the trainingMode to FULL. You should perform full training less frequently, typically one time every 1–5 days.
Best practices
That wraps our post. As you use the new ‘aws-user-personalization’ recipe please keep the following best practices in mind.
- Periodically perform a full training and rely on automatic updates to keep the model up to date with latest item metadata, new items and adjusts the exploration according to implicit feedback from users between full trainings.
- Provide good item metadata. Even with the exploration, the item metadata is still crucial for recommending relevant cold items. The model learns item properties from two resources: interactions and item metadata, and since the “cold” items don’t have any interactions, the model can only learn from the item metadata before exploration.
- Provide accurate item release date via ‘CREATION_TIMESTAMP’ in the item dataset. This information is used to model the time effect on the item, so that we do not explore on old items.
Conclusion
The new aws-user-personalization recipe from Amazon Personalize effectively mitigates the item cold start problem by also recommending new items with few interactions and learning their properties through user feedback during retraining. For more information about optimizing your user experience with Amazon Personalize, see What Is Amazon Personalize?
About the Authors
 Hao Ding is an Applied Scientist at AWS AI Labs and is working on developing next generation recommender system for Amazon Personalize. His research interests include Recommender System, Deep Learning, and Graph Mining
Hao Ding is an Applied Scientist at AWS AI Labs and is working on developing next generation recommender system for Amazon Personalize. His research interests include Recommender System, Deep Learning, and Graph Mining
 Yen Su is a software development engineer in Amazon Personalize team. After work, she enjoys hiking and exploring new restaurants.
Yen Su is a software development engineer in Amazon Personalize team. After work, she enjoys hiking and exploring new restaurants.
 Vaibhav Sethi is the lead Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys hiking and reading.
Vaibhav Sethi is the lead Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys hiking and reading.