AWS Big Data Blog
Announcing Amazon Redshift federated querying to Amazon Aurora MySQL and Amazon RDS for MySQL
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in April 2020, we announced general availability for federated querying to Amazon Aurora PostgreSQL and Amazon Relational Database Service (Amazon RDS) for PostgreSQL to enable you to query data across your operational databases, your data warehouse, and your data lake to gain faster and deeper insights not possible otherwise.
Today, we’re launching a new feature of Amazon Redshift federated query to Amazon Aurora MySQL and Amazon RDS for MySQL to help you expand your operational databases in the MySQL family. With this lake house architecture expansion to support more operational data stores, you can query and combine data more easily in real time and store data in open file formats in your Amazon Simple Storage Service (Amazon S3) data lake. Your data can then be more available to other analytics and machine learning (ML) tools, rather than siloed in disparate data stores.
In this post, we share information about how to get started with this new federated query feature to MySQL.
Prerequisites
To try this new feature, create a new Amazon Redshift cluster in a sql_preview maintenance track and Aurora MySQL instance and load sample TPC data into both data stores. To make sure both Aurora MySQL DB instances can accept connections from the Amazon Redshift cluster, you should make sure that both your Amazon Redshift cluster and Aurora MySQL instances are in the same Amazon Virtual Private Cloud (Amazon VPC) and subnet group. This way, you can add the security group for the Amazon Redshift cluster to the inbound rules of the security group for the Aurora MySQL DB instance.
If your Amazon Redshift cluster and Aurora MySQL instances are in the different VPC, you can set up VPC peering or other networking to allow Amazon Redshift to make connections to your Aurora MySQL instances. For more information about VPC networking, see Working with a DB instance in a VPC.
Configuring AWS Secrets Manager for remote database credentials
Amazon Redshift needs database credentials to issue a federated query to a MySQL database. AWS Secrets Manager provides a centralized service to manage secrets and can be used to store your MySQL database credentials. Because Amazon Redshift retrieves and uses these credentials, they are transient, not stored in any generated code, and discarded after the query runs.
Storing credentials in Secrets Manager takes only a few minutes. To store a new secret, complete the following steps:
- On the Secrets Manager console, choose Secrets.
- Choose Store a new secret.
- For Select secret type, select Credentials for RDS database.
- For User name, enter a name.
- For Password, enter a password.
- For Select the encryption key, choose DefaultEncryptionkey.
- For Select which RDS database this secret will access, choose your database.
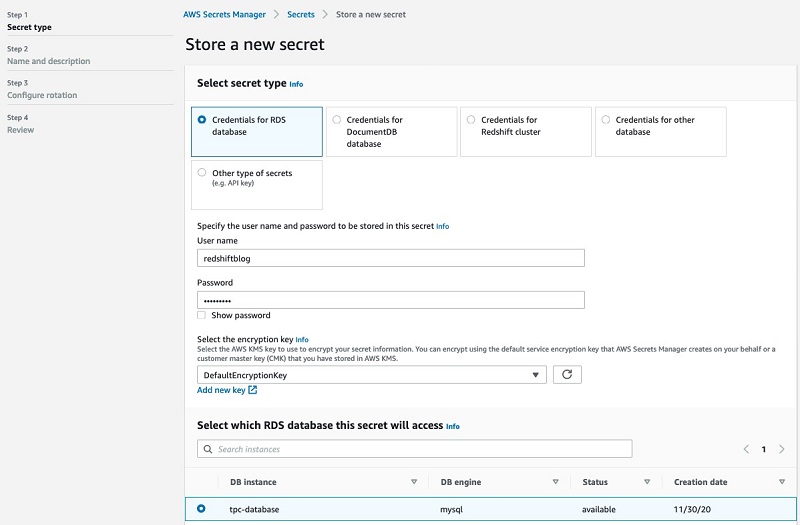
- Optionally, copy programmatic code for accessing your secret using your preferred programming languages (which is not needed for this post).
- Choose Next.
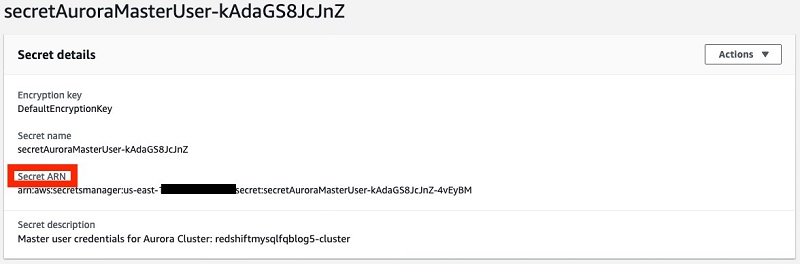
After you create the secret, you can retrieve the secret ARN by choosing the secret on the Secrets Manager console. The secret ARN is needed in the subsequent step.
Setting up IAM role
You can now pull everything together by embedding the secret ARN into an AWS Identity and Access Management (IAM) policy, naming the policy, and attaching it to an IAM role. See the following code:
Finally, attach the same IAM role to your Amazon Redshift cluster.
- On the Amazon Redshift console, choose Clusters.
- Choose your cluster.
- On the Actions drop-down menu, choose Manage IAM roles.

- Choose and add the IAM role you just created.
Setting up external schema
The final step is to create an external schema to connect to your Aurora MySQL instance. The following example code creates the external schema statement that you need to run on your Amazon Redshift cluster to complete this step:
Use the following parameters:
- URI – Aurora MySQL cluster endpoint
- IAM_Role – IAM role created from the previous step
- Secret_ARN – Secret ARN
After you set up the external schema, you’re ready to run some queries to test different use cases.
Querying live operational data
You can now query real-time operational data in your Aurora MySQL instance from Amazon Redshift. Note that isolation level is read committed for MySQL. See the following code:
Querying mysqlfq.web_sales in Amazon Redshift routes the request to MySQL tpc database and web_sales table. If you examine the query plan, you can see the query runs at the MySQL instance as shown by the step Remote MySQL Seq Scan:
Simplifying ELT and ETL
You can also extract operational data directly from your Aurora MySQL instance and load it into Amazon Redshift. See the following code:
The preceding code uses CTAS to create and load incremental data from your operational MySQL instance into a staging table in Amazon Redshift. You can then perform transformation and merge operations from the staging table to the target table. For more information, see Updating and inserting new data.
Combining operational data with data from your data warehouse and data lake
You can combine live operational data from your Aurora MySQL instance with data from your Amazon Redshift data warehouse and S3 data lake by creating a late binding view.
To access your S3 data lake historical data via Amazon Redshift Spectrum, create an external table:
You can then run queries on the view to gain insight on data across the three sources:
You should the following three records as output:
If you examine the query plan, you can see that the predicates are pushed down to your MySQL instance to run:
Available Now
Amazon Redshift federated querying to Aurora MySQL and Amazon RDS for MySQL is now available for public preview with Amazon Redshift release version 1.0.21591 or later. Refer to the AWS Region Table for Amazon Redshift availability and to check the version of your clusters.
About the Authors

BP Yau is an Analytics Specialist Solutions Architect at AWS. His role is to help customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next-generation big data analytics platform using AWS technologies.

Zhouyi Yang is a Software Development Engineer for the Amazon Redshift Query Processing team. He’s passionate about gaining new knowledge about large databases and has worked on SQL language features such as federated query and IAM role privilege control. In his spare time, he enjoys swimming, tennis, and reading.

Entong Shen is a Senior Software Development Engineer for Amazon Redshift. He has been working on MPP databases for over 8 years and has focused on query optimization, statistics, and SQL language features such as stored procedures and federated query. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.