AWS Partner Network (APN) Blog
Enabling Customer Attribution Models on AWS with Automated Data Integration
By Charles Wang, Product Evangelist at Fivetran
 |
Every company wants to understand the levers that influence customers’ decisions. Doing so requires a chronology of a customer’s interactions with a company to identify the events and experiences that influence their decision to buy or not.
Attribution models allow companies to guide marketing, sales, and support efforts using data, and then custom tailor every customer’s experience for maximum effect.
In this post, I will discuss how simple data integration can be, how it enables customer analytics, and how customer data can be used to build attribution models to uncover what makes customers tick.mar
Fivetran is an AWS Partner Network (APN) Advanced Technology Partner and data pipeline tool that provides automated data connectors to integrate data into data warehouses such as Amazon Redshift. Fivetran has earned the Amazon Redshift Ready designation.
Combined together, cloud-based data pipeline tools and data warehouses form the infrastructure for integrating and centralizing data from across a company’s operations and activities, enabling business intelligence and analytics activities.
Customer Analytics Requires Data Integration
With the growth of cloud-based services, the average business now uses more than 100 applications. These systems generate an enormous volume of data that contain insights about an organization’s operations and customer interactions.
However, data can be useless to an organization that lacks the capacity to integrate and analyze it. In fact, a majority of commercial data is thought to consist of dark data, which is collected and processed but not used for analysis. To build attribution models, an organization needs to integrate and centralize data from its applications, databases, event trackers, and file systems.
As with many other business operations—e-commerce, customer relationship management, payment processing, and more—there is no need for an organization to build tools for data integration in-house when a software-as-a-service (SaaS) product that accomplishes the same tasks already exists.
Data pipeline tools like Fivetran provide data connectors to integrate data from API endpoints, database logs, event streams, and files. Every data connector is built and maintained by an expert team that understands the idiosyncrasies of the underlying data source, is stress-tested against a range of corner cases, and operates with minimal intervention by the end user.
Connectors bring data from data sources to a data warehouse on a regular sync schedule, and, when managed by a conscientious team, will automatically adapt to schema and API changes.
Similarly, data warehouses like Amazon Redshift allow organizations to maintain a single source of truth in the form of a relational database. Cloud-based data warehouses offer excellent, parallelized performance, the ability to scale computation and storage resources up and down as needed, and the ability to conduct analytics operations using SQL.
An effective data stack—with a data pipeline, data warehouse, and business intelligence tool carefully selected to meet your needs—allows you to focus on what your analysts and executives really care about, which is understanding your customers so that your organization can do its best work.
The following diagram illustrates the stack:
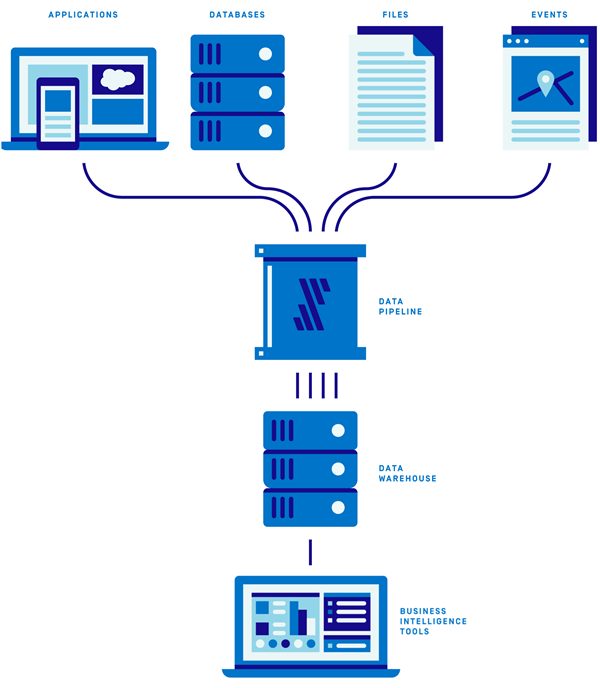
Figure 1 – A data stack consists of data sources, pipeline, data warehouse, and BI tool.
Fivetran, Redshift, and Customer Attribution in the Real World
The design and stationery company Papier relied heavily on paid marketing to drive sales. Shortly before adopting Fivetran, Papier began to use Amazon Redshift as a central repository for ad, transaction, and clickstream data.
Originally, the CTO used custom extract, transform, and load (ETL) scripts and infrastructure code to import data from ad providers and other sources.
This home-brewed approach introduced inaccuracies and inconsistencies to the data, forcing the team to frequently re-sync the data at the cost of substantial downtime. The CTO would personally spend one full working day per week resolving ETL issues.
This time investment proved untenable as Papier continued to grow and add data sources. They needed an automated solution that accommodated a wide range of data sources with a minimum of human intervention and data integrity issues.
Combining Fivetran and Redshift allowed Papier to connect data from ad providers with purchases, enabling them to calculate the lifetime value of customers and grasp the ROA and ROI on advertising campaigns. With this solution, Papier is now able to pursue product roadmaps with far greater strategic depth.
Fivetran and Amazon Redshift provide an off-the-shelf solution to the challenge of putting the relevant records into one environment. Learn more about the Fivetran and Papier case study >>
How to Integrate Data
It’s extremely simple to connect Amazon Redshift with Fivetran and begin integrating data. Before you start, you must have the following:
- Access to your AWS console so you can whitelist Fivetran IP addresses.
- Ability to connect an admin user, or have permissions to create a limited user with CREATE permissions.
- An existing Redshift instance.
Make sure you have the following information handy as well:
- If your Redshift cluster is in an Amazon Virtual Private Cloud (VPC) or an Amazon Elastic Compute Cloud (Amazon EC2) instance.
- Your host and port.
For detailed instructions on authorizing your Redshift cluster to connect with Fivetran, see the documentation.
The workflow for setting up Fivetran is extremely simple:
- Upon starting a Fivetran account, you’ll be prompted to choose an existing data warehouse or spin up a new one. Choose I already have a warehouse.
- You’ll then see a list of data warehouse options. Select Redshift.
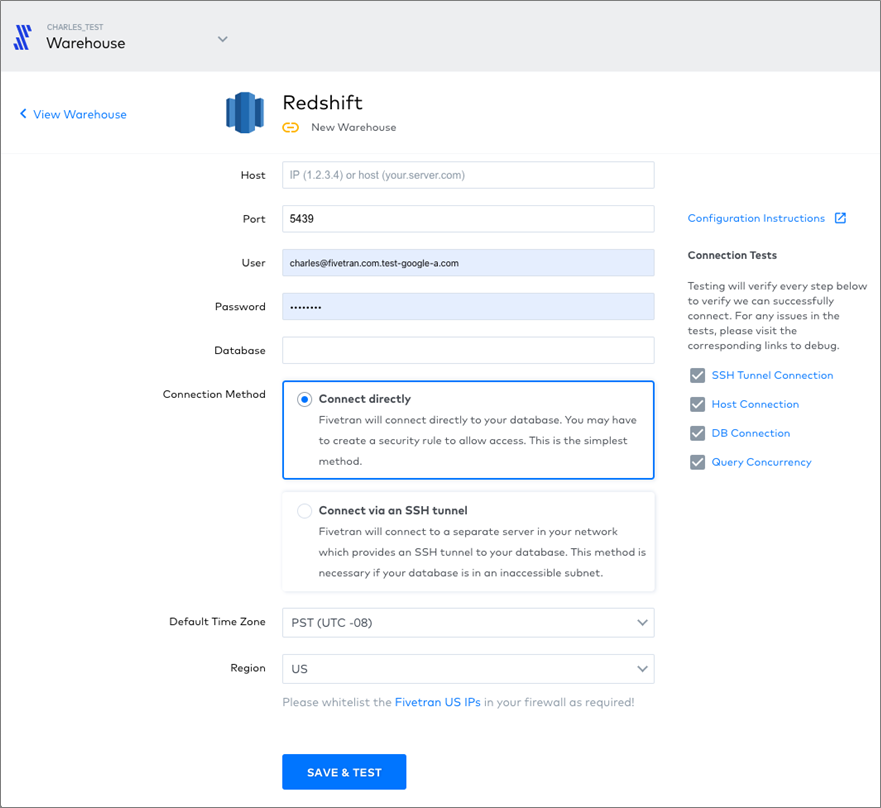
Figure 2 – Setting up Amazon Redshift data warehouse in Fivetran.
- Enter your credentials and choose whether you’ll connect directly or via SSH tunnel. Click Save and Test.
- Now, you will subsequently be able to access the Fivetran dashboard. From here, you can set up new connectors to begin syncing data to your data warehouse. Click + Connector or Create Your First Connector.
- You will be taken to a list of connectors, and you can scroll or filter by text. Click on the desired entry in the list.
To set up the connector, you must enter the credentials to the API, transactional database, event tracker, or file system. Below is an example of the interface for a transactional database connection.

Figure 3 – These fields should be familiar if you regularly work with database connections.
Below is an example of an app connection. Clicking Authorize takes you to the app itself, where you must authorize the connection.
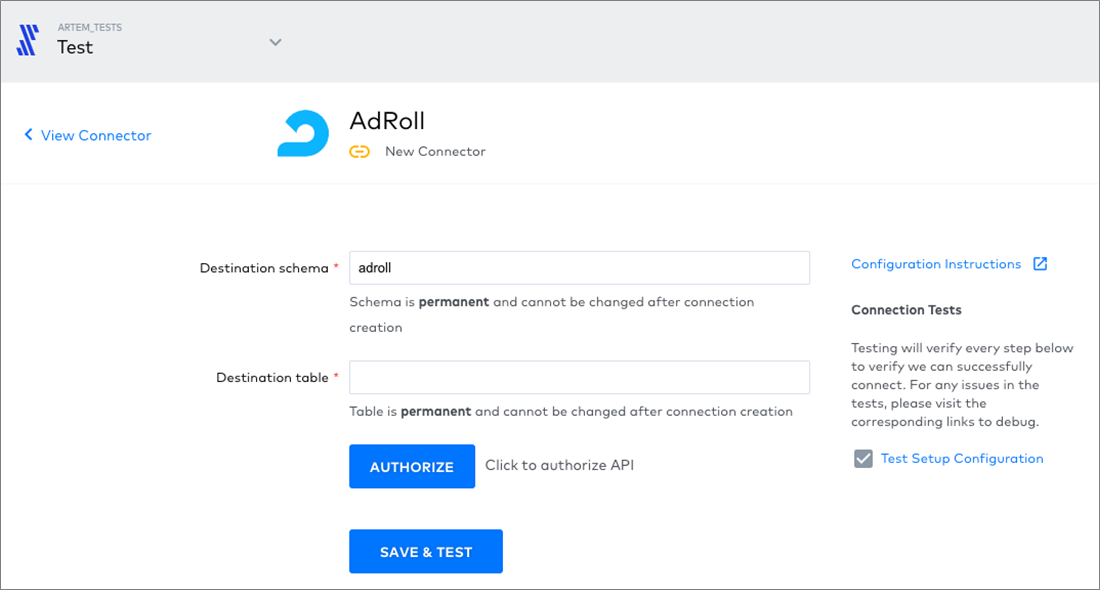
Figure 4 – Carefully select the destination schema and table in the data warehouse.
Next, here’s an example of the interface for an event tracker.
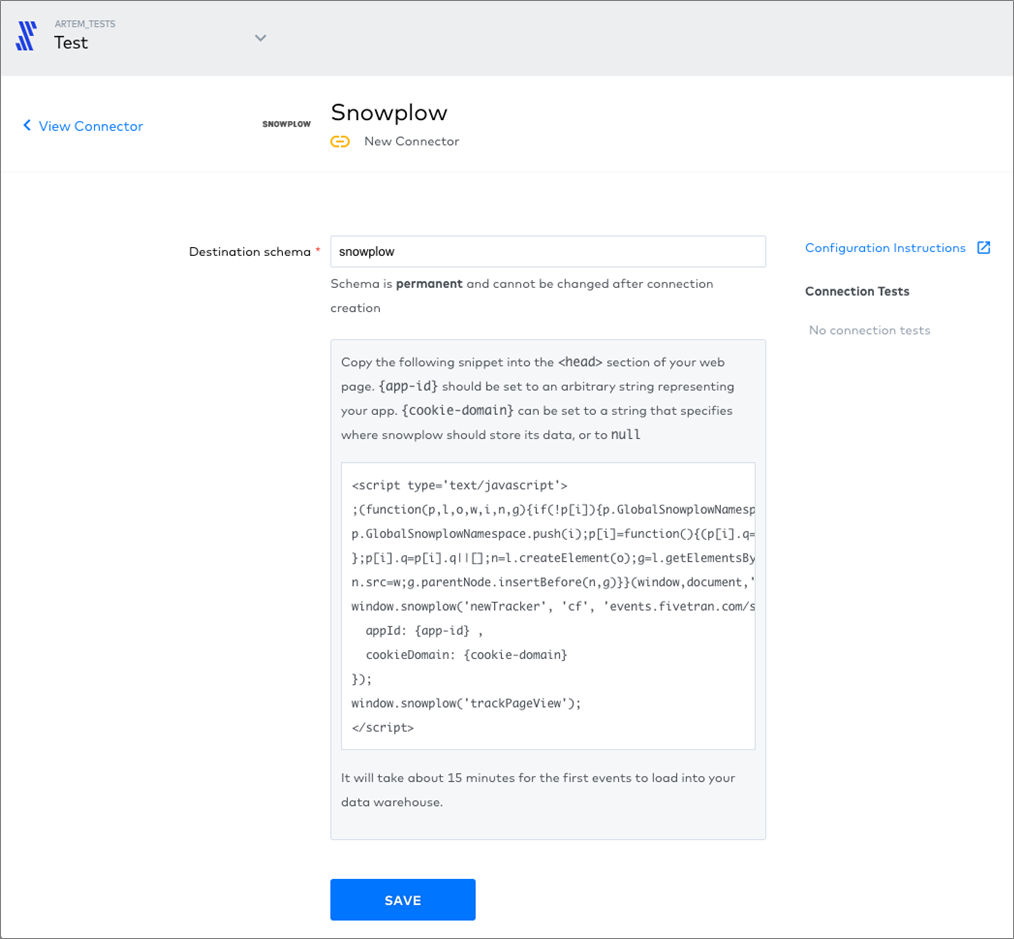
Figure 5 – Specify the destination schema, and then insert the code snippet into your HTML.
In the examples above, we have demonstrated that setting up data integration is a matter of following a relatively simple sequence of steps. But how do you actually build an attribution model?
How to Approach Customer Attribution
Depending on the particulars of an industry, your customers may interact with your company across any of the following platforms:
- Advertising
- Social media
- Website or mobile app event tracking
- Customer relationship management tools
- E-commerce
- Payment processing
Ideally, you should assemble a full chronology of the customer’s journey from the first touch all the way to purchase. This allows you to understand the inflection points that make or break a potential purchase.
Depending on the exact goods and services your organization provides, customers could conceivably have multiple journeys as they make recurring purchases.
A general representation of a customer journey consists of the following steps:
- Discovery: Customers realize they have a want or need.
- Research: Compares vendors and products.
- Engage: Enters your (virtual or brick-and-mortar) storefront, browses, and speaks with your sales staff.
- Purchase: Customer purchases the product or service.
- Retain: Returns to the vendor for future purchases.
Suppose you run an e-commerce store; concretely, a customer journey may look like this:
- Customer learns of a new type of product through their acquaintances and searches for it online.
- A social media site uses cookies from the customer’s search history and surfaces a banner ad for your company, who finds it and clicks it while browsing social media. The interaction is recorded by your social media advertising account.
- Customer arrives at your website via the banner ad and begins reading reviews and browsing your blog out of curiosity. Every page the customer visits on your site is recorded by your event tracking software.
- Customer adds items to their cart and creates an account on your site. Your e-commerce platform records the prospective transactions.
- Customer abandons the cart for a few days as other priorities draw their attention, but is reminded by your email marketing software that their cart has items. The customer clicks on a CTA to complete the order. The email marketing software records this interaction.
- Both the e-commerce platform and online payment processing platform record the transaction when the customer completes the order.
- A week or so later, the customer leaves a review on your company’s social media profile.
Note how the steps above spanned six distinct platforms operated by your company: social media advertising, website event tracking, e-commerce, email marketing, payment processing, and social media.
To build a chronology of this customer’s interactions, you must put the relevant records into one environment and attribute them to the same customer.
How to Identify Customers Across Platforms
Our example in the previous section demonstrates just how complicated the customer flow can be in terms of traversing various platforms. That’s to say nothing of the possibility your customers switch from mobile to desktop devices, or from home networks and coffee shops to office networks over the course of a single day.
There are no perfect solutions, but you can use several identifiers to distinguish between customers, devices, and campaigns across their web-based activities.
- IP addresses are unique at the network level, so all web-connected devices in the home or office might have the same IP address. If you are a B2B company and have engaged the services of a market research company, there’s a chance they can associate an IP address with the name of a company.
- Cookies are tags assigned to a browser session.
- User agents provide information about users’ browser, operating system, and device.
- Email and social media are two ways that users can register with your site, and you can use these accounts as identifiers. You’ll have to determine the trade-off between the convenience, to you, of requiring registration and login, and the convenience to users of using your website without an account.
- UTM extensions can be used to distinguish different sources of traffic. A link to a page from social media may be tagged with character suggest.
Examples of Attribution Models
Once you have assembled a chronology of customers’ interactions with your company, you’ll need to determine which steps in the process mattered most. There are several classic customer attribution models, each assigning different weights to different stages of a customer interaction.
The simplest attribution models are single-touch, and only require you to be certain of the first or last interaction your customer has with your company.
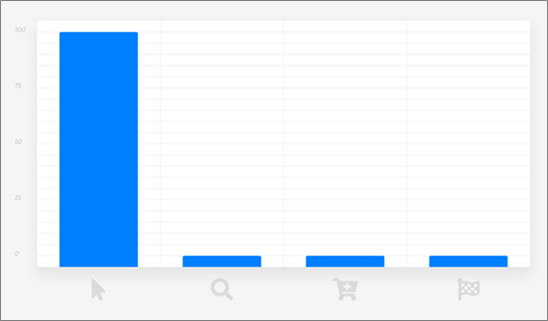
Last-Touch Attribution
Last-touch attribution attributes 100 percent of the credit for a sale to the last interaction between the customer and your company.
This is the default approach used by marketers and the simplest to implement; all you have to know is the last thing the customer did before purchasing.
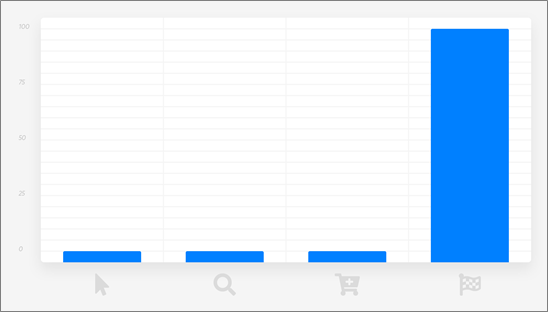
First-Touch Attribution
First-touch attribution attributes 100 percent of the credit for a sale to the first interaction between the customer and your company.
Like last-touch attribution, it’s suitable to cases where your company has low brand recognition or a very short sales cycle.
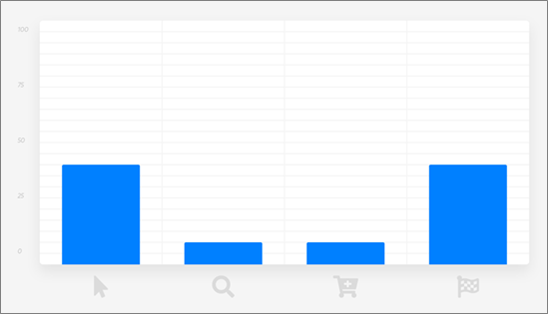
U-Shaped Attribution
U-shaped attribution, also called “position-based,” attributes the lion’s share of credit to the first and last interactions, while dividing the remainder among the other interactions.
This allows the interactions that are generally considered the most important—the first and last—to be strongly considered without ignoring the rest.
Suppose the customer had four recorded interactions with your company. The first and last interactions might each receive 40 percent of the credit, while the two middle interactions receive 10 percent each.
.
It could also be 50/0/0/50 if you don’t care at all about the middle interactions.
.

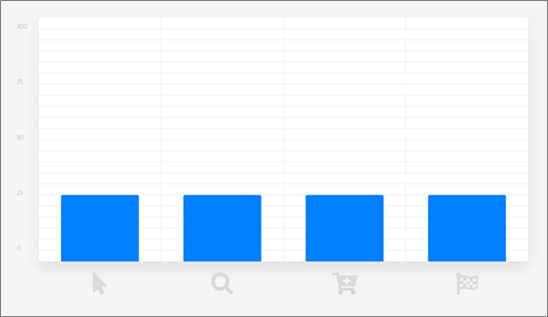
Linear Attribution
Linear attribution is strictly agnostic and assigns equal weight to every interaction. This is a good approach if you don’t have any prior, compelling beliefs about the importance of any particular interaction.
Decay Attribution
Decay attribution gradually assigns more weight the closer an interaction is to the last. It’s best suited to cases where a long-term relationship is built between your company and the customer.
Next Steps
Customer analytics does not end with the models mentioned above. More sophisticated custom models, built off of Markov chains or survival modeling, are a next step. It doesn’t hurt to sanity check quantitative work with the qualitative step of simply asking your customers what they do, either.
With the proliferation of applications, platforms, and devices, and constant growth of data, it’s hard enough to match records across the multitude of data sources and touch points your organization uses when they are already in one place.
Without a data pipeline tool like Fivetran and a data warehouse like Amazon Redshift, the task of integrating data can be insurmountable.
Summary
In this guide, we have explored how analytics depend on a robust data integration solution and offered a practical guide to getting started with data integration and customer attribution.
Customer attribution models require the ability to match entities across multiple data sources. This requires a cloud-based data pipeline tool, and a cloud data warehouse like Amazon Redshift.
You should not build your own data connectors between your data sources and data warehouse. Doing so is complicated and error-prone. You should prefer automation to manual intervention wherever possible. A good data integration solution should require a relatively simple setup procedure.
There are a number of different approaches to modeling customer journeys, identifying customers, and producing customer attribution models. Different approaches are appropriate for different use cases. Pick and choose based on your needs.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Fivetran – APN Partner Spotlight
Fivetran is an Amazon Redshift Ready Partner. Its data pipeline tool provides automated data connectors to integrate data into data warehouses such as Redshift.
Contact Fivetran | Solution Overview | AWS Marketplace
*Already worked with Fivetran? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.