AWS Partner Network (APN) Blog
Automatically Detect and Protect Sensitive Data in Amazon S3 Using PK Protect Data Store Manager
By Jason Dobbs, CTO – PKWARE
By Tamara Astakhova, Sr. Partner Solutions Architect – AWS
By Anoop Sunke – Contributing Writers
 |
| PKWARE |
 |
PKWARE has been working on finding and protecting sensitive data in a range of data stores over the last 15 years.
PK Protect Data Store Manager (DSM) is PKWARE’s flagship product for data stores that can scan for sensitive elements in structured and unstructured data, and optionally mask or encrypt the data.
On Amazon Web Services (AWS), PK Protect DSM scans and protects sensitive data in Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), Amazon Redshift, and Amazon FSx file system.
In this post, we describe the steps to scan objects in Amazon S3 buckets and protect them with masking or encryption.
PKWARE is an AWS Data and Analytics Competency Partner that provides enterprise software for personal data discovery and protection.
PK Protect DSM Overall Architecture
There are four layers in the deployment architecture, as shown in Figure 1:
- User Interface Layer: Consists of tools used to access PK Protect DSM by the end user. This includes a browser-based user interface (UI) and REST APIs.
. - Server Layer: Includes the PK Protect DSM server, known as the “Controller,” which is attached to a metadata database. On AWS, this can be an Amazon RDS database. The Controller also has other enterprise integrations, such as LDAP, Active Directory, and standard single sign-on (SSO) systems.
. - Intelligent Data Processor Layer: Consists of one or more intelligent data processors (IDPs). There is one IDP per target data store type. For example, if the customer has data in Amazon S3 and Amazon Redshift that need to be scanned and protected, one S3 and one relational database management system (RDBMS) IDP are deployed. The Controller itself does not process any data from the target stores; that’s the job of the IDP. The Controller, therefore, does not contain any sensitive data from the targets.
. - Target DataStore Layer: Consists of the customer’s data stores, both cloud and on-premises. PK Protect DSM supports a wide range of target data stores, and PKWARE is expanding the supported list regularly based on customer demand.
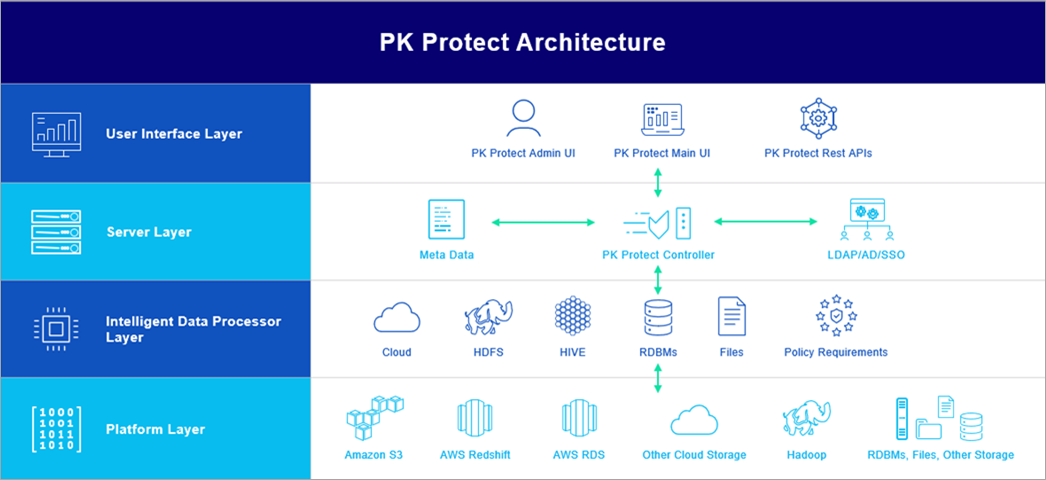
Figure 1 – PK Protect DSM overall architecture.
PK Protect DSM Architecture for Amazon S3 Operations
For Amazon S3 operations, the overall architecture is simplified in Figure 2. Users interact with the PK Protect DSM server via either the browser-based UI or REST APIs.
The PK Protect DSM server sends commands to the S3 IDP for scanning or protecting objects within S3 buckets. The S3 IDP provisions its own compute for the processing.
The resources allocated for the compute are fully configurable by the user of PK Protect DSM. The S3 IDP can reside in the same Amazon Elastic Compute Cloud (Amazon EC2) instance or in a separate EC2 instance from the Controller. Multiple IDPs can be attached to a single Controller.

Figure 2 – PK Protect DSM architecture for Amazon S3 operations.
Sample Dataset
We’ll be using the CustomerDim.csv data set from the AdventureWorks sample database that originated in Microsoft and is used widely for database examples. This dataset, along with others in the AdventureWorks example, can be found in AdventureWorks DimCustomer.csv.
The DimCustomer.csv table contains personal information about customers. Figure 3 shows an overview snapshot of the first few columns of the table.

Figure 3 – Overview snapshot of DimCustomer.csv.
The first few columns from a couple of rows that will be discussed in detail are shown in Figure 4.

Figure 4 – Selected columns and rows for further discussion.
PK Protect DSM Concepts and Flow
Scanning or protecting data via PK Protect DSM requires the creation of a task that operates on the data store. A task requires a policy and details of the target upon which the policy is applied. The following are the relevant key concepts within PK Protect DSM that help set up and execute tasks:
- Policy: A policy in PK Protect DSM consists of a set of sensitive types and protection options for each sensitive type. There are several predefined policies, covering widely applied regulations and industry standards, such as GDPR, PCI, HIPAA, and PII.
. - Sensitive Type: A sensitive type in PK Protect DSM refers to a class of data whose elements have certain identifying properties. There are more than 80 predefined sensitive types in PK Protect DSM. In addition to the predefined types, custom types can be defined to cover the needs of organizations.
. - Protection Option: A protection option in PK Protect DSM refers to masking or encryption options. There are more than 40 masking options, and two major encryption options. Masking is a one-way operation, while encryption can be reversed. Masking options in PK Protect DSM include redaction and tokenization effects. In addition to the predefined protection options, custom protection options can be created and executed.
. - Scan Path or Target Database: In file or object data stores, a scan path refers to the target directory or subset of a bucket that needs to be scanned for sensitive data and optionally, protected. The scan path is recursively scanned, unless certain sub-paths are explicitly exempted from the scan. In databases, the term target database is used to refer to the database that needs to be scanned and/or protected.
. - Task: A task is the unit of execution in PK Protect DSM. Tasks can be detection, protection, or decryption tasks. Tasks execute on a scan path or target database, and depending on the type of operation to be performed (detection, protection, or decryption) apply the policy (or policies) to the target data. In addition to policies, various options can be attached to a task. For example, sampling percentage or incremental versus full scan. Each execution of a task is referred to as a task instance.

Figure 5 – PK Protect DSM usage flow.
Detailed Steps for Amazon S3 Detection and Protection
In this section, we’ll get into the details of creating and executing detection and protection tasks on Amazon S3. The three major steps are Policy Creation, Task Definition, and Task Execution.
Policy Creation
The first step is to determine which policies are applicable in your organization. If one or more of the predefined policies are sufficient, then no further action is needed.
More typically, especially in large organizations, the need is felt to create custom policies, and in many cases, custom sensitive types. For example, a proprietary customer identifier may be needed, as well as additional context to confirm an item is indeed of a particular type.
A condition for the customer identifier might be that their email address is also in the same record. Otherwise, it should not be identified as a customer identifier. A custom sensitive type can be created from the sensitive type manager screen.
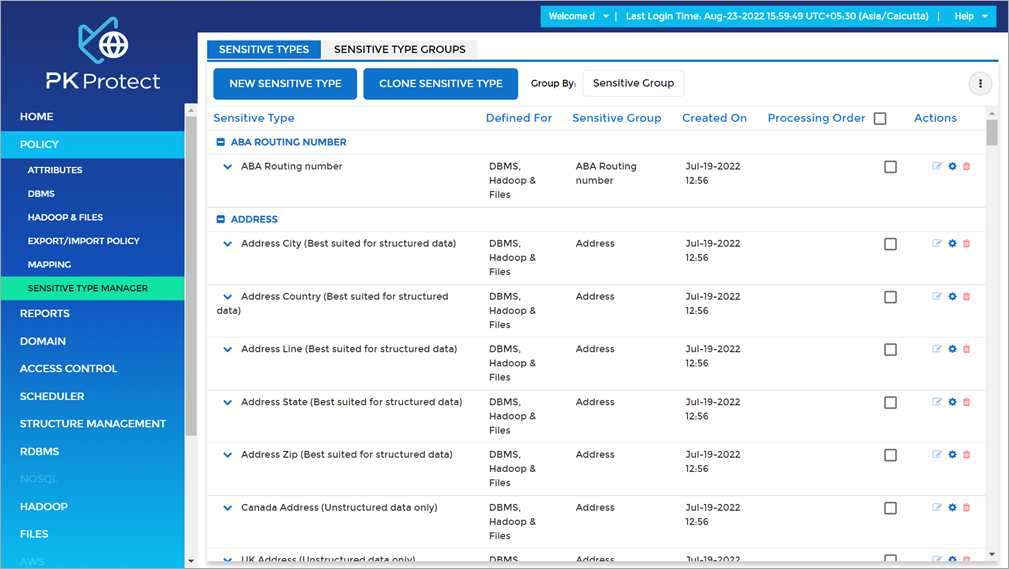
Figure 6 – Sensitive type manager in PK Protect DSM.
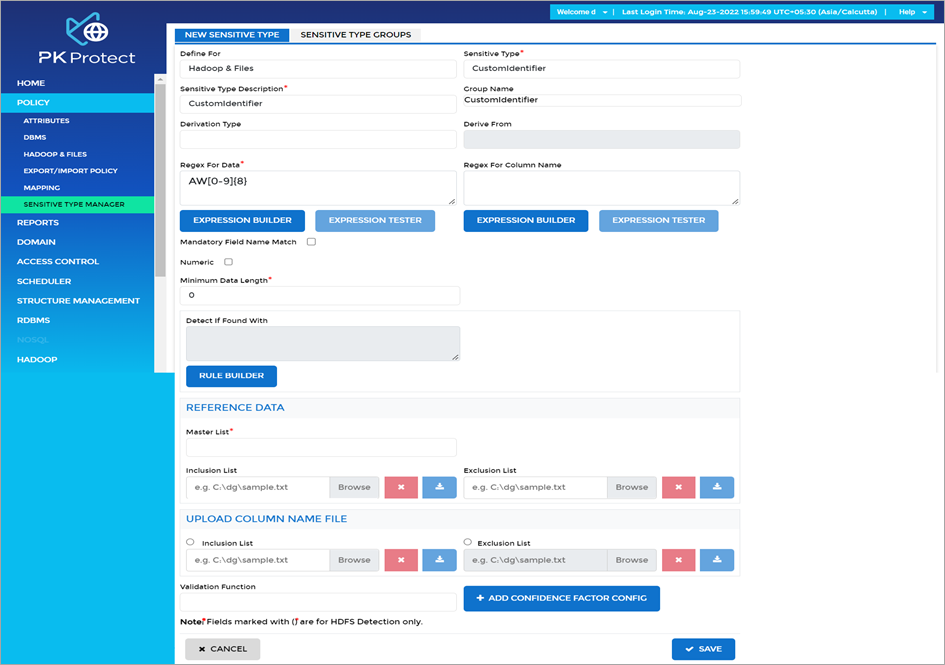
Figure 7 – Creation of custom type in PK Protect DSM.
In Figure 7, we show how the contents of Column 3 of the sample data set DimCustomer.csv can be defined as a sensitive type so that detection and protection can be done. This particular custom type, named CustomIdentifier, starts with the letters “AW” followed by eight numerical digits.
In this case, the logic applied to find elements of this custom type is based only on regular expressions. However, PK Protect DSM supports far more complex methods of specifying custom types, including reference lists, custom validation methods, and machine learning.
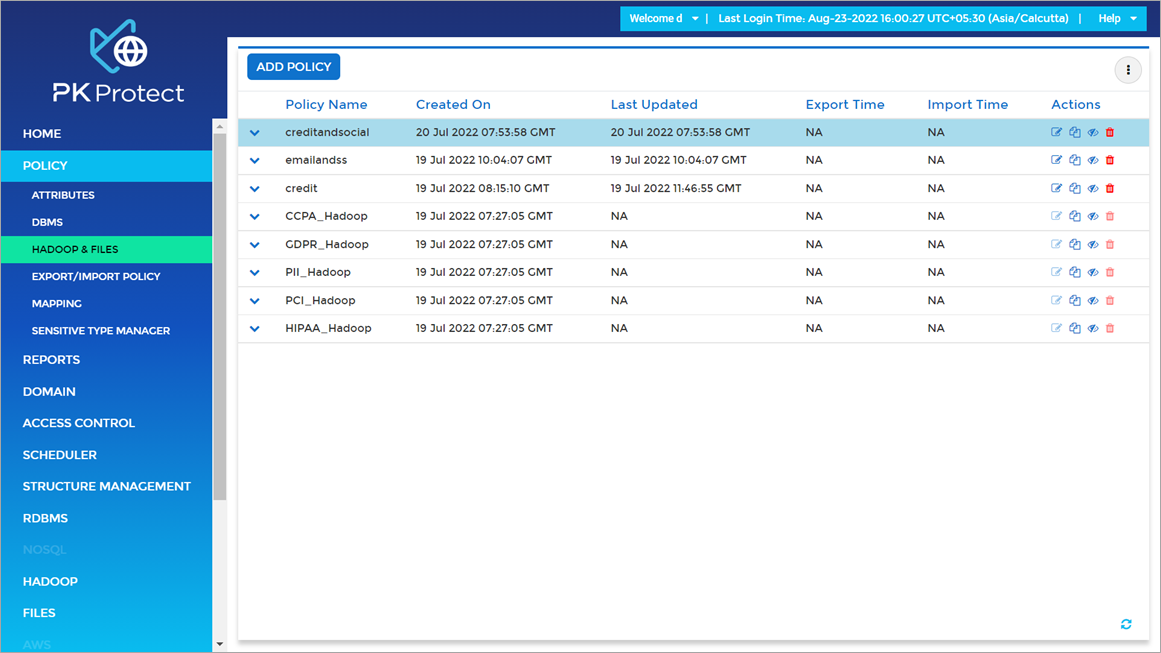
Figure 8 – Policy screen in PK Protect DSM.
Once all custom sensitive types needed are defined, a new policy can be created by clicking the New Policy tab in the Policy Screen, as shown in Figure 8. All types needed in the policy can be included there with optional protection options selected.
Task Definition
Once the set of policies is decided upon, tasks need to be created to scan specific buckets or paths within a bucket. Figure 9 shows the PK Protect DSM browsers that enable point-and-click selection of scan paths.
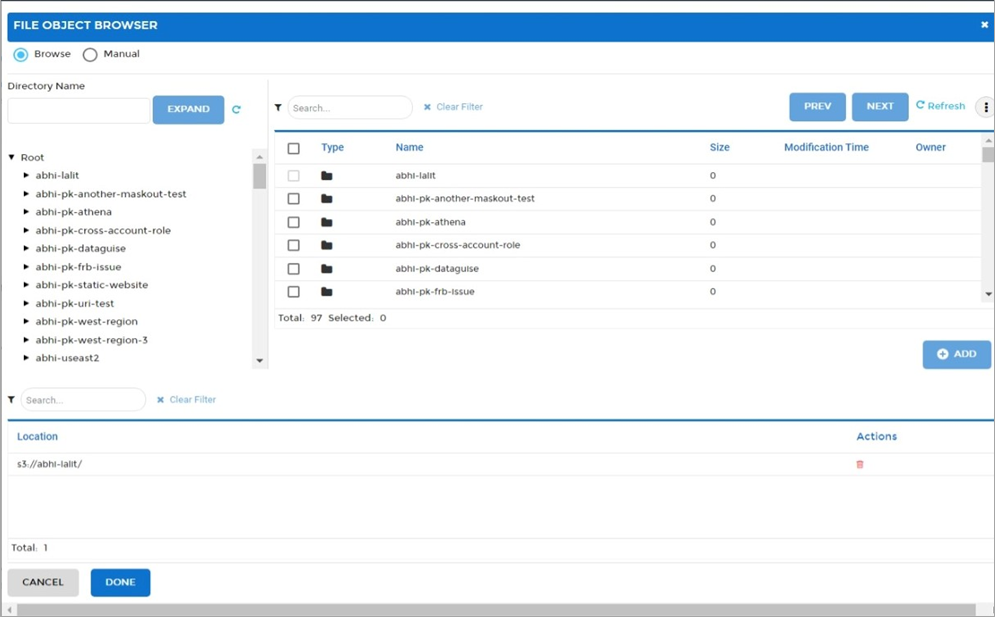
Figure 9 – Browser screen in PK Protect DSM.
As discussed before, each task type has many options. PK Protect DSM offers anywhere between single-digit to 100 percent sampling of the data for detection. Another option, provided for both detection and protection, is incrementality of the scan.
By default, scans are incremental in that previously scanned objects are not scanned again. This can be overridden using the Full Scan option.
Task Execution
Once the task definition is set, the task can be executed any number of times from the Tasks screen.

Figure 10 – Tasks screen in PK Protect DSM.
Completed tasks show the results in the UI, and there are three panes in the results screen. The top pane is a listing of task instances that executed. If one of these instances is selected, the other two panes show information for that task. The Task Instance Overview section in the middle pane shows details about the execution of the task instance selected in the top pane. The Results Overview tab in the bottom pane consists of four graphs.
The first graph shows how many structured versus unstructured objects were found. The second shows how many of the scanned objects were sensitive, and the third shows a breakdown in counts of different sensitive types that were found in this task. The last graph shows a breakdown of the types of objects found during the scan, based on file type.
Clicking the Detailed Results tab of the bottom pane gives a breakdown of the sensitive data information on a per-object basis. The results can be exported to PDF or Excel for further analysis or presentation.
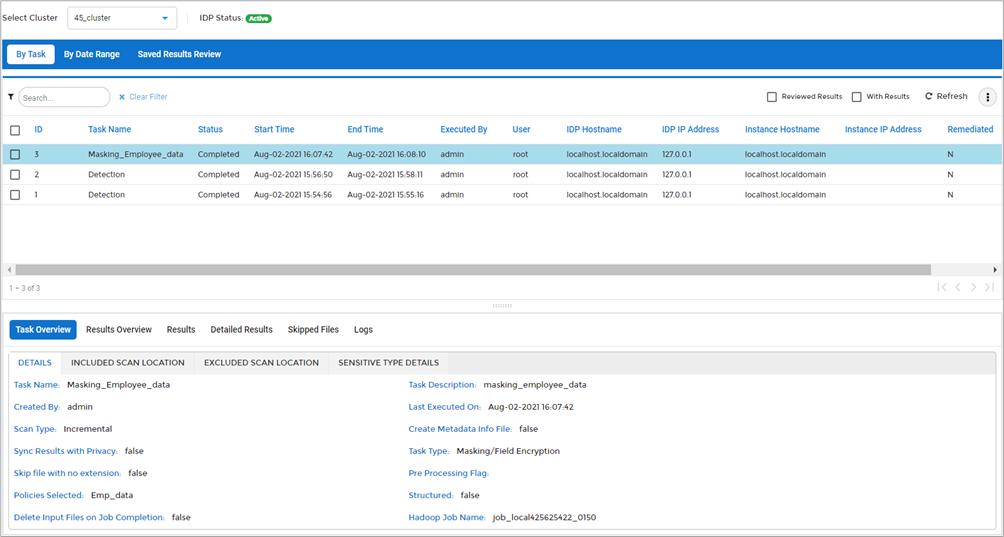
Figure 11 – Task Results screen in PK Protect DSM.
In addition to the summarized results in Figure 11, where aggregate numbers are shown for each sensitive type as part of the pie chart, the Detailed Results tab shows counts of sensitive types found in each Amazon S3 object.

Figure 12 – Detailed results in PK Protect DSM.
Masking and Encryption
A masking or encryption task can be set up similar to the above for detection. The appropriate task type is to be selected, as shown in Figure 13.
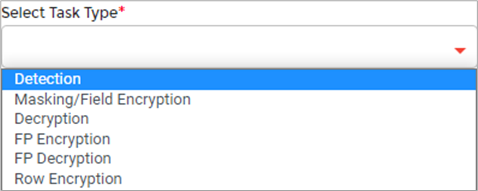
Figure 13 – Task types in PK Protect DSM.
In the case of structured data, masking or encryption can also be done without first running detection. For this, structure definition and import capabilities are provided.
For masking and encryption, a target bucket and path name within the bucket can be designated. Masked and/or encrypted copies of the original objects will be placed in the target bucket/path name. The source data can optionally be deleted as part of these operations.
Discussion of Masked/Encrypted Data
If a masking or encryption operation has been performed, results can be seen in the target bucket and path specified earlier as part of task definition.
Original Data

Masked Data
![]()
Note that Columns 3, 4, 5, 7, and 10 are masked. The masking option chosen, Format-Preserving Masking, retains the alphabetical characters as alphabets and numerics as numerics, but substitutes other values for these.
PK Protect DSM provides more than 35 masking options to achieve various effects and to satisfy various analytics requirements on the masked data.
Encrypted Data
![]()
Here, Column 3 is the only one encrypted. The encrypted strings can be decrypted using PK Protect DSM’s bulk decryption task, or can be decrypted using the PK Protect DSM decryption library. The bulk decryption task creates an object that contains decrypted values for the sensitive types where the executor of the task has rights to decrypt.
The decryption library returns decrypted values dynamically based on the executor’s rights to decrypt. In both cases, the rights to decrypt can be set for various users at the granularity level of sensitive type groups. PK Protect DSM provides integration to enterprise directory systems to import users and apply decryption rights.
Automated Operation via Command Line/REST API
PK Protect DSM also includes command line capability (DGCL) and a REST API to fully automate the above scans and other capabilities provided in the product.
Using the REST API, the command to execute a task is:
where
sessionID – Session ID returned by the login call
controllerIP – IP address where the Controller installed
tomcatPort – port at which Tomcat is listening
s3ClusterName – logical name of the compute (done by one-time set up)
taskID – ID of the task to execute
In the example above, we have described a case where the task is set up from the UI, and executed on a scheduled basis from DGCL or the REST API. It’s also possible to do all the steps from policy creation to task definition purely from DGCL or the REST API.
Conclusion
This post has focused on detecting and protecting sensitive data at the element level in Amazon S3 with PK Protect Data Store Manager (DSM).
PK Protect DSM supports a wide range of targets besides Amazon S3 in both the cloud and on-premises. On AWS, PK Protect DSM supports Amazon Redshift and Amazon RDS detection and protection in addition to S3. Learn more on the PKWARE website.
.

.
PKWARE – APN Partner Spotlight
PKWARE is an AWS Data and Analytics Competency Partner that provides enterprise software for personal data discovery and protection.