AWS Partner Network (APN) Blog
Create Dynamic Serverless Applications with Neo4j Graph Database and AWS Lambda
By Jennifer Reif, Developer Advocate – Neo4j
By Michael Hunger, Sr. Director User Innovation – Neo4j
By Antony Prasad Thevaraj, Sr. Partner Solutions Architect – AWS
 |
| Neo4j |
 |
The AWS Cloud Development Kit (AWS CDK) is a framework that provides an automated and repeatable way of handling cloud infrastructure. It allows developers to use a variety of programming languages (including Java) to “define reusable cloud components known as constructs” and “compose these together into stacks and apps.”
In this post, we will walk you through using the AWS CDK to build an AWS Lambda function in Java that connects to Neo4j. The framework described here can be used to build dynamic serverless applications where the frontend scales based on system demand. This makes it possible to easily get value from your connected graph data in front end applications.
Neo4j is an AWS Data and Analytics Competency Partner that enables organizations to unlock the business value of connections, influences, and relationships in data.
Benefits of Neo4j
Today’s data environment is complex and vast. Businesses aren’t focused as much on what is getting stored, but how it all connects. Connections in data can provide experiences and products that better match the environment or customers we are working with.
For instance, by understanding a person’s preferences, work, and hobbies, businesses can offer tools to make their job easier, vacations to maximize their downtime, or products to suit their lifestyle. Traditional data stores make relationships in data hard to discover, but a graph database like Neo4j elevates these connections.
Graph databases store relationships alongside the entities themselves, making them equally important. Whether focused on real-time transactional or analytical loads, Neo4j is designed to optimize storage and retrieval of connected data. Applications, visualization tools, and data science capabilities can interact with the database to provide further data insights and help businesses make dynamic, accurate decisions for the business.
Solution Overview
Our goal in this post is to use an AWS Lambda function to connect to Neo4j, run a query against the graph database, and return the results.
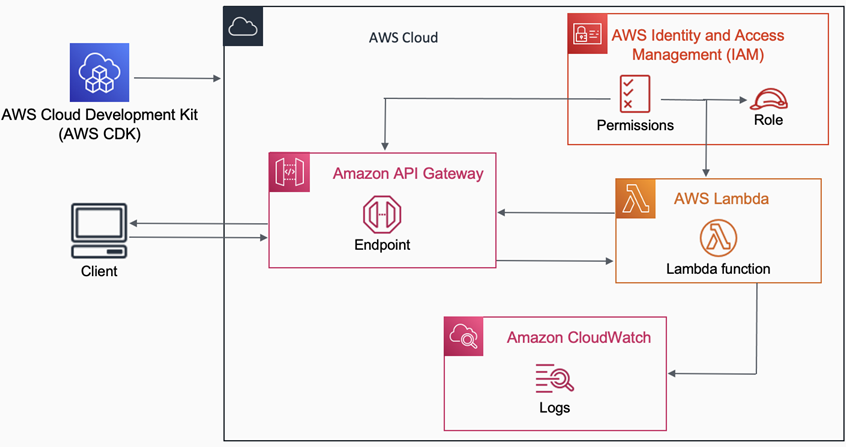
Figure 1 – Architecture deployed by the CloudFormation example.
The AWS CDK will build and run the infrastructure. It handles several of the concerns in the diagram above, such as logging, access controls, and API setup, abstracting much of the labor involved in setting up the AWS CloudFormation stacks.
Prerequisites
As with any technology project, we need a few tools installed. If you are a Java developer, you probably already have a Java Development Kit (JDK) and a preferred integrated development environment (IDE) set up.
Neo4j Database
Using Neo4j’s AuraDB free tier gives you a cloud instance to spin up in a few minutes. Details on setup are available in this blog post (choose the blank database option, and follow the article through the “Create Your First Database” section). Save (or download) the generated password where you can access it later, as it will not be displayed again.
AWS
Previously, the longest part of the setup was the AWS portion, but that is reduced quite a bit with the Cloud Development Kit. However, we’ll still need to install the AWS CDK and dependencies listed in the prerequisites section of the guide.
- Node.js 10.13.0 or later: The Node.js download page is linked in the prerequisites of the AWS CDK getting started guide. If Node.js was installed with a package manager, you can reference the package manager guide. Check your Node.js location and version with which node and node –version.
- Java dependencies: JDK 1.8 or later and Apache Maven 3.5 or later.
- Configure AWS account credentials: You can follow the commands in the related guide section to create an account and get the proper access.
- AWS CDK: Next, install the AWS CDK itself with npm install -g aws-cdk.
Walkthrough
AWS has a Github repository for CDK Java code to help get you started. Much of the infrastructure setup has been bundled into development kit commands, making the process more consistent and less prone to error.
The project’s README file covers the high-level process and structure of the code. It also says we need the CDK and Docker. We already installed the CDK, but if you don’t have Docker you’ll need to install and ensure it is running.
Next, run the code using three commands. The first command puts you in the infrastructure directory, while cdk synth synthesizes or packages the functions and infrastructure, and cdk deploy deploys the stack to AWS.
cd infrastructure
cdk synth

Figure 2 – Output of first two commands.
After running the first two commands, you will see the output shown above. With a successful build complete, the next step is to deploy. To do so, run the command:
cdk deploy
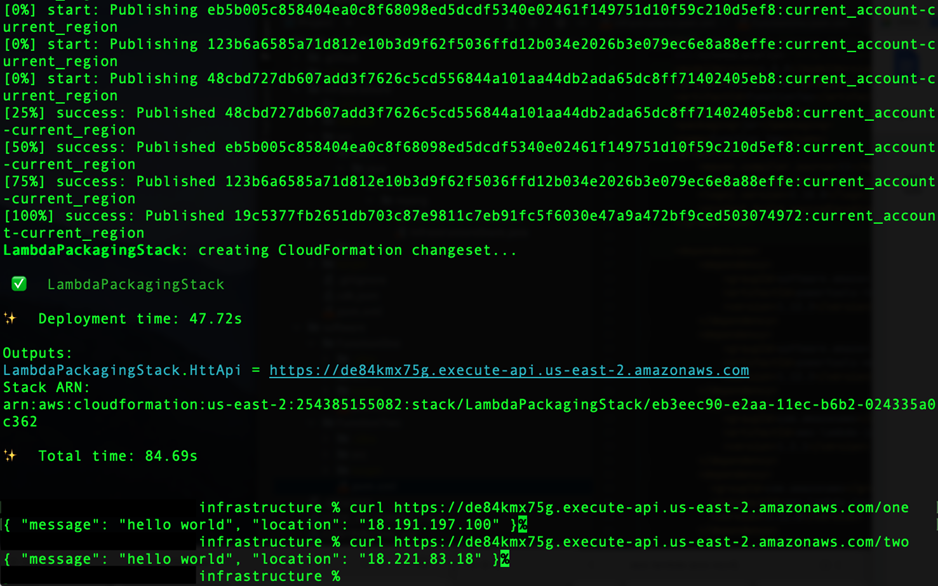
Figure 3 – Output of deploy command.
Note that your shell terminal may ask to deploy security changes. Type y and press Enter.
To verify everything deployed, find the AWS Lambda service from the AWS Management Console and click on it. You should see a list similar to the one below (you should see two starting with LambdaPackagingStack-Function#).

Figure 4 – AWS Lambda console, showing our deployed function.
Now, we can test the functions by copying/pasting the LambdaPackagingStack.HttpApi URL toward the bottom of your cdk deploy output and adding the name of the function we are calling (/one or /two). IP address requests and results can differ.
curl <yourLambdaPackagingStackHttpApi>/one
curl <yourLambdaPackagingStackHttpApi>/two
Infrastructure Code Walkthrough
Let’s review the code. The /infrastructure/src/main/java/com/myorg folder contains two classes: InfrastructureApp.java and InfrastructureStack.java. The app class only has a main method that creates a stack, so let’s take a look at the stack class.
Line 37 creates an object using the parent class’ constructor. Next, we define a list of packaging instructions. Then, we set up build options for a Docker container and mount the Maven directory (avoid downloading dependencies each time). The next blocks do the packaging and testing.
After that, set up an API for accessing and executing our functions. Add a separate route (endpoint) for each function, and then create an output object to display when we call an endpoint.
Adding New Function Infrastructure
We want to copy the template provided for Neo4j. The completed infrastructure code is available in this code repository, which will build and deploy a new function. Before we write the function code itself, let’s take a look at the existing code for the other functions.
Function Code Walkthrough
Under the software folder, we can look at FunctionOne or FunctionTwo, as they contain the same code.
Dependencies for each are in the respective pom.xml files, but we’ll skip to the core code in the App.java file. First, it implements a RequestHandler<> map that sends a request and gets a response. Next, we have the handleRequest() method. Within the method, we define headers for our response and set up a response object.
The next block uses a “try…catch” statement to retrieve the page contents from a URL. The code then creates a formatted output message with hello world and page contents (IP address of the URL). The last statement in theory returns the response status code and body, and the catch section surfaces errors.
The getPageContents() method moves the URL input to an object, then applies a “try…catch” to get the URL contents (.openStream method) and return the IP address.
Creating a New Function
We can copy either of the function folders and paste it as a new folder called FunctionThree. Note that you will need to refactor a few things to the new FunctionThree.
Your project structure should look like below:

Figure 5 – Project structure.
Next, to connect to Neo4j, copy/paste bits of the Neo4j AuraDB console sample code for various languages and frameworks.
The example AuraDB code hard codes database credentials (lines 78-81), creates a driver variable (line 15), and creates a driver object (line 19). Hard coding credentials isn’t best practice, so we’ll utilize environment variables to pass the values into the function. We were unable to create a driver object at the class level. There should be a way to do it, but for now we’ll put it inside the handler.
We also need to add a couple of dependencies to our pom.xml for the neo4j-java-driver to connect to Neo4j and the gson library to serialize/deserialize JSON data.
Next, we can move to our query. Since we are working in Java, we loaded the Java versions and diffs into the graph to query. Statements to load this data are available in this graph-demo-datasets repository.

Figure 6 – Viewing the graph in Neo4j browser.
Note that you can run CALL apoc.meta.graph() after the data is loaded in your instance to see the data model above.
Next, let’s write our query. We’ll search for and return a JavaVersion node by passing in a query parameter to our API endpoint. We can attach the version we want to the end of our URL and inspect the parameter from the function.
On line 46, we define a variable that will hold the version we are passing in as a URL query parameter. Check if the input contains a non-null version query string parameter, and then assign the query parameter value to the variable.
The next block defines the read query that we want to run in Neo4j. We want to find JavaVersion nodes where the version property equals the parameter (URL’s query string parameter value) and return the version, its status, the general availability date, and end-of-life date. The next line sets our URL parameter to a variable that will be passed into the query at runtime.
Last but not least, we need to connect to Neo4j and execute the query, starting with a “try…catch” statement. We create a database driver session, and then define a record that calls a session’s readTransaction() method. A result calls the transaction’s run() method, passing in the query string and the parameter for the version, and returning a single result to the record variable.
The output variable definition is adjusted a bit, so that we return the record as a map and convert it to standard JSON using the gson.toJson() method. The last bit of the try section returns the response with the status code and body.
In the catch, we catch any Neo4jExceptions for our query. Since we aren’t inspecting URL page contents, we can remove the pageContents() method.
To test, run the cdk synth and cdk deploy commands again from the Infrastructure folder. Output to both commands should look similar to our earlier test, with extra output for our new FunctionThree. Process may ask you to deploy security changes again.
One last step is to add the environment variables to FunctionThree in the AWS console. To do that, navigate to the AWS Lambda service and choose LambdaPackagingStack-FunctionThree<hash>.
Under the overview section, choose the Configuration tab, then Environment variables from the left menu, and click the Edit button on the right. Fill in the variables with your database credentials. Once saved, you should see something like below.

Figure 7 – Configuring the Neo4j connection in the AWS Lambda console.
Back at the command line, we can run our newest function (FunctionThree).
curl “<yourLambdaPackagingStackHttpApi>/three?version=17”
You can test with any Java language version. If there are errors, you can go to the Amazon CloudWatch logs and check what went wrong.
Conclusion
In this post, we used the AWS Cloud Development Kit (AWS CDK) to run an AWS Lambda function written in Java that connects to Neo4j. This code is available as a repository on Github, and you can check out Neo4j on AWS Marketplace.
.

.
Neo4j – AWS Partner Spotlight
Neo4j is an AWS Data and Analytics Competency Partner that enables organizations to unlock the business value of connections, influences, and relationships in data.