AWS Partner Network (APN) Blog
How Accelerating Data Preparation with Trifacta for Amazon Redshift Drives More Value from Analytics
 |
 |
By David McNamara, Product Marketing Specialist at Trifacta
Onboarding data for operational analytics requires agility in taking disparate sources of data in varying formats and schemas, and then blending, cleaning, and restructuring that data for analysis.
Consultancies, analytics providers, or any organization that has to deal with unfamiliar data faces the challenge of how to understand, structure, and blend new data for the purposes of analytics. The ability to do this more efficiently and at scale is what drives competitive business advantages.
For many data analysts and data scientists, the majority of their work is tied up in this data preparation and cleaning process. At Trifacta, this is the problem we’re exclusively focused on—making all of the prep work before analytics and machine learning faster, more intuitive, and scalable without sacrificing governance and security.
Trifacta enables a diverse set of users with varying skill sets to quickly onboard new customer data by providing a unique user experience driven by visualizations and intelligent guidance—not code. This frees an organization’s resources up to focus on delivering value for analytical work.
Trifacta is an AWS Partner Network (APN) Advanced Technology Partner with AWS Competencies in both Data & Analytics and Machine Learning. If you want to be successful in today’s complex IT environment, and remain that way tomorrow and into the future, teaming up with an AWS Competency Partner like Trifacta is The Next Smart.
In this post, we’ll explore how Trifacta running on Amazon Web Services (AWS) enables Adaptive Analytics to improve the efficiency and scale of their customer data onboarding process into Amazon Redshift. We’re also excited to announce a free trial of Trifacta Wrangler Pro for Amazon Redshift.
Accelerating Data Source Onboarding for Redshift
Adaptive Analytics helps clients gather, integrate, analyze, and visualize their data. They bring a well-defined process to identify key metrics, data behind the metrics and analysis, and visualization based on that process. Adaptive Analytics was named to CIO Review’s list of Top Analytics Solution Providers for 2019.
As Adaptive Analytics has grown their business, they quickly realized they needed faster, more agile data preparation for onboarding customer data. The bottleneck of manually cleaning and structuring customer data was limiting their ability to bring on new clients and how fast they could respond to requests.
Amazon Redshift provides Adaptive Analytics with a modern data warehouse for their analytics platform. Redshift serves the needs of Adaptive’s growing business with scalable storage and compute, fast query performance at a fraction of the cost of a traditional data warehouse, and enterprise level security—without needing administration overhead and ongoing maintenance.
Redshift also enables Adaptive to query the data in Amazon Simple Storage Service (Amazon S3) directly with the Spectrum feature, with no data movement or loading.
Since all of the client data Adaptive Analytics works with is in various structures and formats, their team must extensively explore, normalize, and clean the data before it can be loaded into Redshift for analysis. Trifacta allows the Adaptive team to improve the speed and scale for onboarding customer data by providing a visual and machine learning-guided data preparation platform that anyone on their team can utilize.
“What drew us to Trifacta Wrangler Pro is the user interface,” says Parnell Woodard, Founder of Adaptive Analytics. “Trifacta surfaces data quality issues immediately, and provides visual guidance and automatic suggestions that make assessing and preparing new data quick and agile.”
Trifacta Wrangler Pro is a managed platform that sits atop Amazon Elastic MapReduce (EMR) and connects natively to a user’s Amazon S3 and Redshift environments. Trifacta user authentication is done via native AWS Identity and Access Management (IAM) roles.
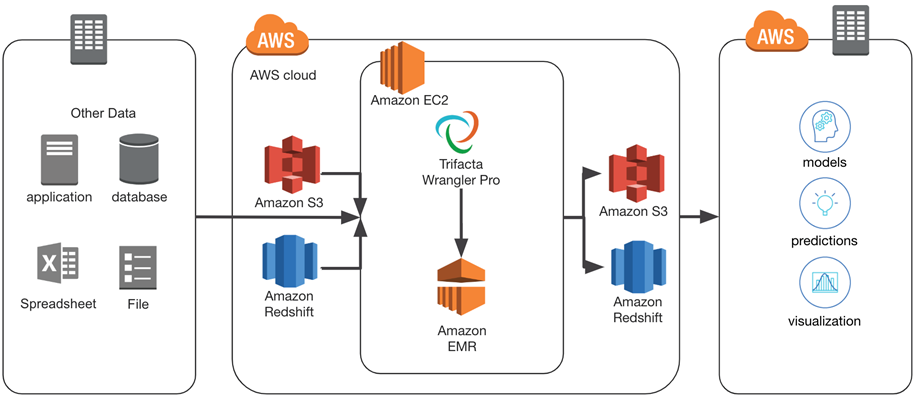
Using Trifacta to Onboard Data for Marketing Analytics
In the example below, we’ll walk you through a marketing analytics use case to highlight how Trifacta helps customers quickly prepare data for their analytics applications. Similar to how Adaptive Analytics needs to prepare customer data with agility and accuracy to deliver value to customers, this example will showcase the ease of blending and preparing disparate sources of data in Trifacta.
We will access and prepare semi-structured Advertising_Clickstream data from Amazon S3, blend it with structured Sales data from Amazon Redshift, and format the data to fit a predefined data model we’ve created to ensure our data is in the optimal format for the downstream analytics we want to perform. We have provided data at the end of this walkthrough if you would like to follow along.
You’ll see how Trifacta is able to natively access data from these two popular AWS platforms and easily profile, clean, and blend the data while providing visual interactivity and feedback throughout. This gives users the confidence that their results are valid, while also building their data pipeline and removing the need for an entirely separate data validation step prior to analysis.
First, a user needs to select their data. They can browse through Amazon S3 and Redshift to access the appropriate data, starting with Advertising_Clickstream data. This data exists in Amazon S3, and a new file of the previous days’ clickstream data is dropped into the Advertising_Clickstream directory daily. Each file contains the timestamp of their creation in the file name. Note that this is mocked data meant to map to an Adaptive Analytics use case.
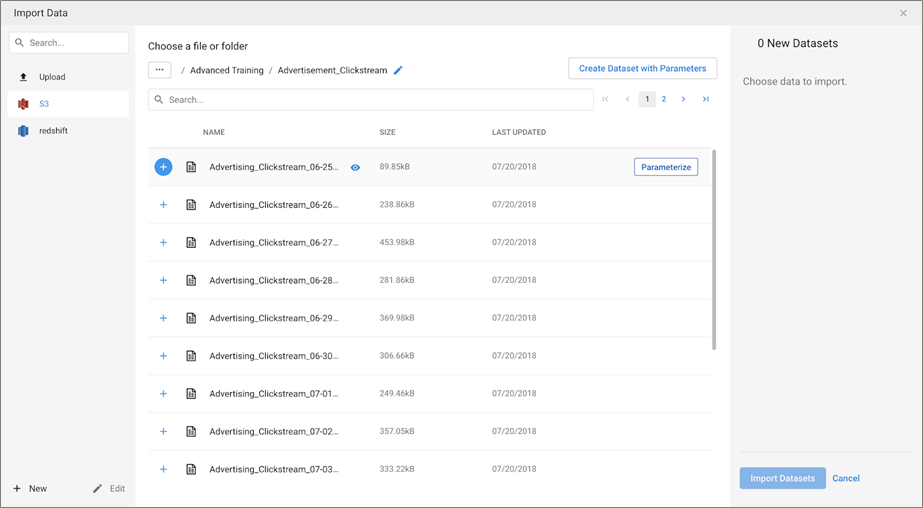
For this example, we’re going to create a parameter that will pick up datasets inside this Advertising_Clickstream directory timestamped between June 1 and July 31, 2018. The ability to parameterize gives me control over the amount of data being processed.
Next, we are going to access my Sales data from Amazon Redshift, and we’ll also select the target output format registered from Redshift. This target represents the ‘Master Output’ format that the transformation process needs to map to for the data model.
Once the data has been selected, we can start preparing it to fit the downstream target output the data must conform to for analysis. The first step to do this is to attach a Target using Trifacta’s RapidTarget feature.

This target, which you can see above the columns in the current dataset, provides a visual guide to aid in the data preparation process to match the format of the target. The colors and shapes each represent information on the match between the current dataset and the target. Red empty boxes represent no current match; green empty boxes represent a match in name and type but not order; and a green arrow represents a match in name, type, and order.
Now that the target has been attached, we’ll blend this Advertising_Clickstream data with the Sales data from Redshift. Trifacta’s Join interface provides guided suggestions to make blending data quick and easy. It has built-in validation checks to ensure my join is of high quality.

As columns are added to the join, the target automatically updates to show matches.

This real-time profiling information gives users confidence that the steps being added are close to the desired target. For data onboarding, especially with new customers, this cuts down exploration time significantly.
Moving across the dataset shows there are some columns in the target that aren’t in the original dataset, such as product_id and domain_url. By selecting the URL column, Trifacta’s built-in machine learning populates some suggestions on the right of the screen, one of which being to create a new column containing the domain. Selecting that provides a preview of that new column.

We can also highlight information within the column URL, and Trifacta populates a suggestion to extract that info, which I need to rename to product_id.
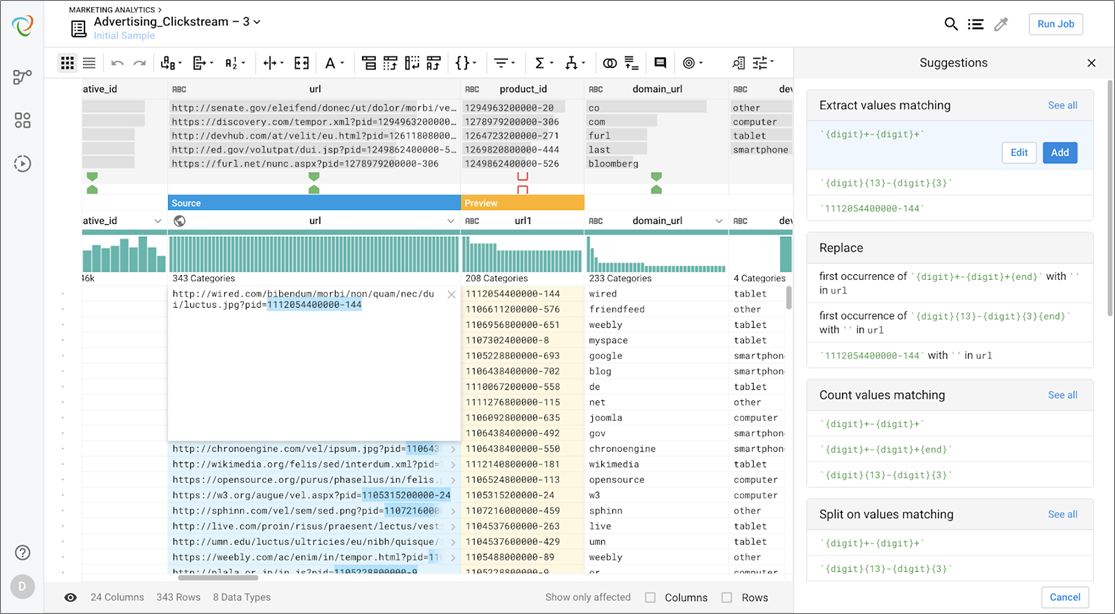
These are tasks that can take quite a bit of time to code using more traditional methods of data preparation. Trifacta’s modern approach of using machine learning and visualizations to give guidance and decision-making authority to the user creates an intuitive experience when working with data. It also provides built-in data quality assurance.
Taking a look at the columns view, it’s apparent that there is still more work to do to map to the downstream target data model.
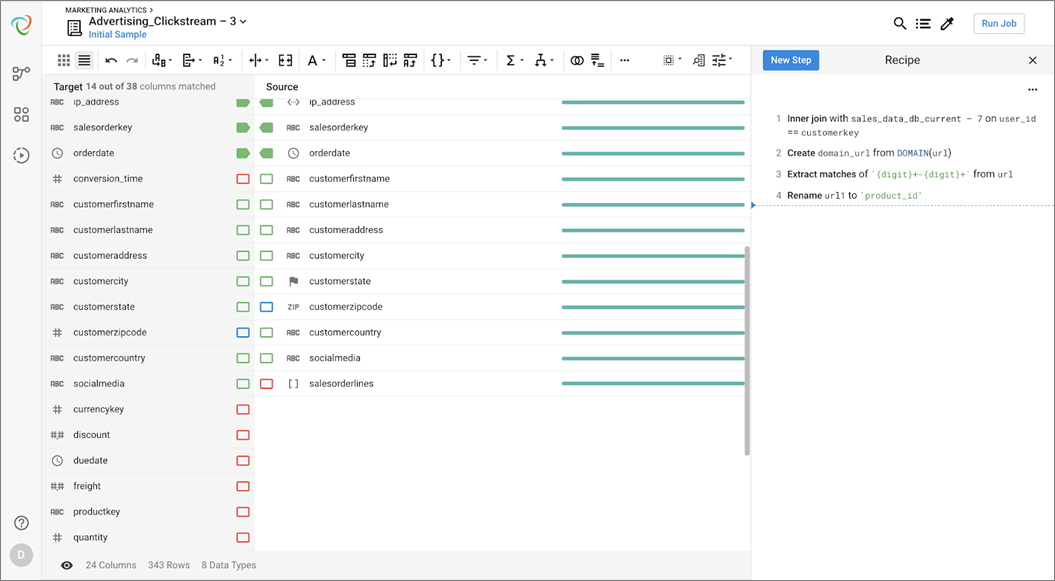
There is information nested in salesorderlines column, which is an array containing json objects as elements that will need to get unnested. First, though, we need to create the conversion_time column to map to the target.
Using the toolbar, I’ll select the datedif function, and making a judgement based on the numbers in the target we’re going to find the number of days that elapsed between ad_click and sale. This is one of the key metrics required for the analysis , and we can use Trifacta’s preview to ensure that the formula is correct.

Lastly, there’s some needed information nested inside this salesorderlines column that is in the target.

We’ll need to flatten this array and then unnest the json objects. To do this, we’ll leverage Trifacta’s intelligence and simply click on the column header. This gives me a suggestion to flatten the array.

Next, we’ll again click the column header and unnest the object into columns. Flattening an array and unnesting a json object is quick and easy, only requiring a couple of clicks.

We’ll do one more step of deleting the salesorderlines column now that all of the information from the object has been extracted to have good alignment with the target.
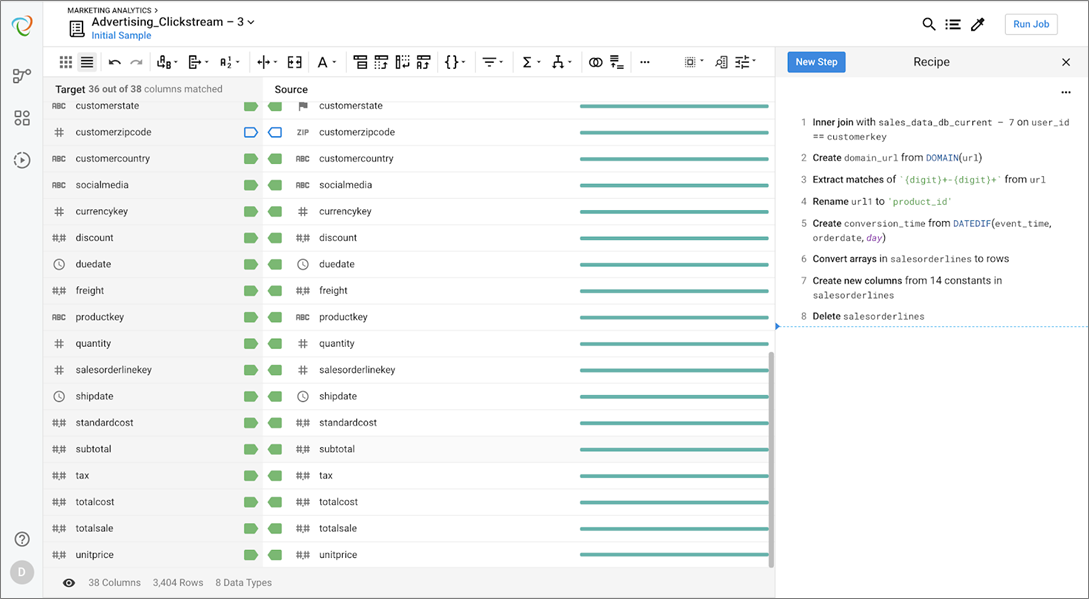
There are two columns that need final data type cleanup, as noted by the blue arrows next to customerzipcode. Once those have been addressed, we are ready to run a job to process the data according to the steps I built and publish back to Redshift where the analysis is performed.

Summary
Trifacta makes it easy to quickly onboard unfamiliar data such as new customer data. The visual guidance and machine learning-driven suggestions ensure users can quickly define the steps required to prepare the data, and provides validation that the data quality meets defined standards.
In this post, we took Advertising_Clickstream data in Amazon S3, blended it with Sales data in Amazon Redshift, and prepared it with the guidance of Trifcata’s RapidTarget feature. This ensured the steps we created to blend, clean, and structure our data got us to an end result consistent with the data we use to feed our dashboards or analytics algorithms.
Traditional methods might use a combination of tools like SQL and code to blend data from databases and file systems. This process, when building for a new customers’ data, involves creating a new set of scripts without any visual guidance. This can lead to a painful iterative process of building the code, visualizing the results, analyzing its accuracy and data quality, and debugging the code to identify where pitfalls may have occurred.
In Trifacta, native connection to Redshift, Amazon S3, and other sources allows users to blend data from disparate sources. The built-in visual guidance ensures users get their data preparation right the first time, eliminating the painful back and forth between code and validation.
Once a recipe is created to prepare data, users can operationalize an entire workflow on a set schedule or whenever data updates.
Trifacta has just released a free trial of Trifacta Wrangler Pro on Amazon Redshift. Give it a try today!
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
|
Trifacta – APN Partner Spotlight
Trifacta is an AWS Competency Partner and an entirely new approach to preparing data. Experience a new way for working with diverse data, empowering analysts to interact with data in ways they never thought possible.
Contact Trifacta | Solution Overview | Free Trial | Buy on Marketplace
*Already worked with Trifacta? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.