AWS News Blog
Introducing CloudFront Functions – Run Your Code at the Edge with Low Latency at Any Scale

|
With Amazon CloudFront, you can securely deliver data, videos, applications, and APIs to your customers globally with low latency and high transfer speeds. To offer a customized experience and the lowest possible latency, many modern applications execute some form of logic at the edge. The use cases for applying logic at the edge can be grouped together in two main categories:
- First are the complex, compute-heavy operations that are executed when objects are not in the cache. We launched Lambda@Edge in 2017 to offer a fully programmable, serverless edge computing environment for implementing a wide variety of complex customizations. Lambda@Edge functions are executed in a regional edge cache (usually in the AWS region closest to the CloudFront edge location reached by the client). For example, when you’re streaming video or audio, you can use Lambda@Edge to create and serve the right segments on-the-fly reducing the need for origin scalability. Another common use case is to use Lambda@Edge and Amazon DynamoDB to translate shortened, user-friendly URLs to full URL landing pages.
- The second category of use cases are simple HTTP(s) request/response manipulations that can be executed by very short-lived functions. For these use cases, you need a flexible programming experience with the performance, scale, and cost-effectiveness that enable you to execute them on every request.
To help you with this second category of use cases, I am happy to announce the availability of CloudFront Functions, a new serverless scripting platform that allows you to run lightweight JavaScript code at the 218+ CloudFront edge locations at approximately 1/6th the price of Lambda@Edge.

CloudFront Functions are ideal for lightweight processing of web requests, for example:
- Cache-key manipulations and normalization: Transform HTTP request attributes (such as URL, headers, cookies, and query strings) to construct the cache-key, which is the unique identifier for objects in cache and is used to determine whether an object is already cached. For example, you could cache based on a header that contains the end user’s device type, creating two different versions of the content for mobile and desktop users. By transforming the request attributes, you can also normalize multiple requests to a single cache-key entry and significantly improve your cache-hit ratio.
- URL rewrites and redirects: Generate a response to redirect requests to a different URL. For example, redirect a non-authenticated user from a restricted page to a login form. URL rewrites can also be used for A/B testing.
- HTTP header manipulation: View, add, modify, or delete any of the request/response headers. For instance, add HTTP Strict Transport Security (HSTS) headers to your response, or copy the client IP address into a new HTTP header so that it is forwarded to the origin with the request.
- Access authorization: Implement access control and authorization for the content delivered through CloudFront by creating and validating user-generated tokens, such as HMAC tokens or JSON web tokens (JWT), to allow/deny requests.
To give you the performance and scale that modern applications require, CloudFront Functions uses a new process-based isolation model instead of virtual machine (VM)-based isolation as used by AWS Lambda and Lambda@Edge. To do that, we had to enforce some restrictions, such as avoiding network and file system access. Also, functions run for less than one millisecond. In this way, they can handle millions of requests per second while giving you great performance on every function execution. Functions add almost no perceptible impact to overall content delivery network (CDN) performance.
Similar to Lambda@Edge, CloudFront Functions runs your code in response to events generated by CloudFront. More specifically, CloudFront Functions can be triggered after CloudFront receives a request from a viewer (viewer request) and before CloudFront forwards the response to the viewer (viewer response).
Lambda@Edge can also be triggered before CloudFront forwards the request to the origin (origin request) and after CloudFront receives the response from the origin (origin response). You can use CloudFront Functions and Lambda@Edge together, depending on whether you need to manipulate content before, or after, being cached.

If you need some of the capabilities of Lambda@Edge that are not available with CloudFront Functions, such as network access or a longer execution time, you can still use Lambda@Edge before and after content is cached by CloudFront.

To help you understand the difference between CloudFront Functions and Lambda@Edge, here’s a quick comparison:
| CloudFront Functions | Lambda@Edge | |
| Runtime support | JavaScript
(ECMAScript 5.1 compliant) |
Node.js, Python |
| Execution location | 218+ CloudFront
Edge Locations |
13 CloudFront
Regional Edge Caches |
| CloudFront triggers supported | Viewer request
Viewer response |
Viewer request
Viewer response Origin request Origin response |
| Maximum execution time | Less than 1 millisecond | 5 seconds (viewer triggers)
30 seconds (origin triggers) |
| Maximum memory | 2MB | 128MB (viewer triggers)
10GB (origin triggers) |
| Total package size | 10 KB | 1 MB (viewer triggers)
50 MB (origin triggers) |
| Network access | No | Yes |
| File system access | No | Yes |
| Access to the request body | No | Yes |
| Pricing | Free tier available;
charged per request |
No free tier; charged per request
and function duration |
Let’s see how this works in practice.
Using CloudFront Functions From the Console
I want to customize the content of my website depending on the country of origin of the viewers. To do so, I use a CloudFront distribution that I created using an S3 bucket as origin. Then, I create a cache policy to include the CloudFront-Viewer-Country header (that contains the two-letter country code of the viewer’s country) in the cache key. CloudFront Functions can see CloudFront-generated headers (like the CloudFront geolocation or device detection headers) only if they are included in an origin policy or cache key policy.
In the CloudFront console, I select Functions on the left bar and then Create function. I give the function a name and Continue.

From here, I can follow the lifecycle of my function with these steps:
- Build the function by providing the code.
- Test the function with a sample payload.
- Publish the function from the development stage to the live stage.
- Associate the function with one or more CloudFront distributions.

1. In the Build tab, I can access two stages for each function: a Development stage for tests, and a Live stage that can be used by one or more CloudFront distributions. With the development stage selected, I type the code of my function and Save:
function handler(event) {
var request = event.request;
var supported_countries = ['de', 'it', 'fr'];
if (request.uri.substr(3,1) != '/') {
var headers = request.headers;
var newUri;
if (headers['cloudfront-viewer-country']) {
var countryCode = headers['cloudfront-viewer-country'].value.toLowerCase();
if (supported_countries.includes(countryCode)) {
newUri = '/' + countryCode + request.uri;
}
}
if (newUri === undefined) {
var defaultCountryCode = 'en';
newUri = '/' + defaultCountryCode + request.uri;
}
var response = {
statusCode: 302,
statusDescription: 'Found',
headers: {
"location": { "value": newUri }
}
}
return response;
}
return request;
}The function looks at the content of the CloudFront-Viewer-Country header set by CloudFront. If it contains one of the supported countries, and the URL does not already contain a country prefix, it adds the country at the beginning of the URL path. Otherwise, it lets the request pass through without changes.
2. In the Test tab, I select the event type (Viewer Request), the Stage (Development, for now) and a sample event.

Below, I can customize the Input event by selecting the HTTP method, and then editing the path of the URL, and optionally the client IP to use. I can also add custom headers, cookies, or query strings. In my case, I leave all the default values and add the CloudFront-Viewer-Country header with the value of FR (for France). Optionally, instead of using the visual editor, I can customize the input event by editing the JSON payload that is passed to the function.

I click on the Test button and look at the Output. As expected, the request is being redirected (HTTP status code 302). In the Response headers, I see that the location where the request is being redirected starts with /fr/ to provide custom content for viewers based in France. If something doesn’t go as expected in my tests, I can look at the Function Logs. I can also use console.log() in my code to add more debugging information.

In the Output, just above the HTTP status, I see the Compute utilization for this execution. Compute utilization is a number between 0 and 100 that indicates the amount of time that the function took to run as a percentage of the maximum allowed time. In my case, a compute utilization of 21 means that the function completed in 21% of the maximum allowed time.
3. I run more tests using different configurations of URL and headers, then I move to the Publish tab to copy the function from the development stage to the live stage. Now, the function is ready to be associated with an existing distribution.

4. In the Associate tab, I select the Distribution, the Event type (Viewer Request or Viewer Response) and the Cache behavior (I only have the Default (*) cache behavior for my distribution). I click Add association and confirm in the dialog.
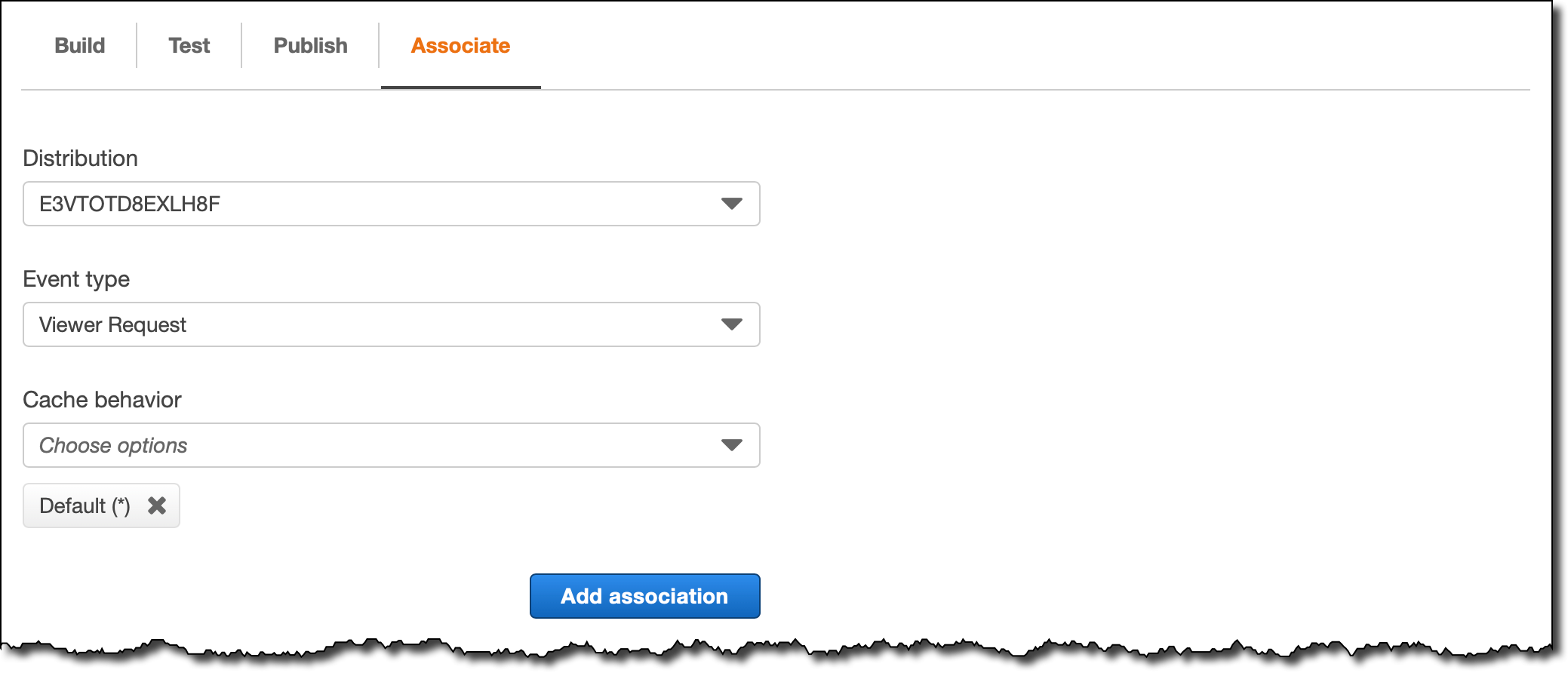
Now, I see the function association at the bottom of the Associate tab.
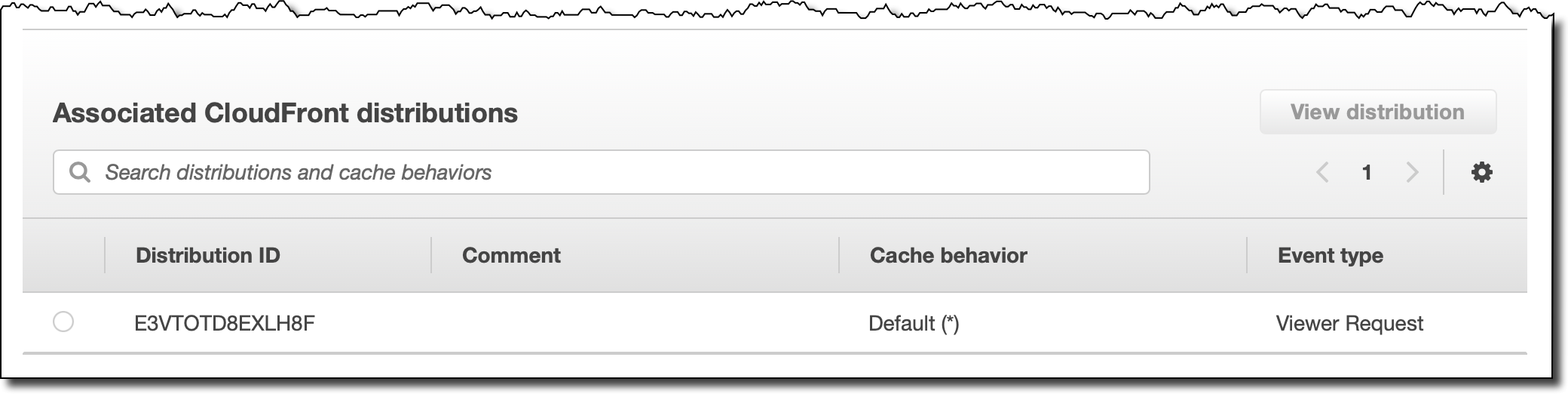
To test this configuration from two different locations, I start two Amazon Elastic Compute Cloud (Amazon EC2) instances, one in the US East (N. Virginia) Region and one in the Europe (Paris) Region. I connect using SSH and use cURL to get an object from the CloudFront distribution. Previously, I have uploaded two objects to the S3 bucket that is used as the origin for the distribution: one, for customers based in France, using the fr/ prefix, and one, for customers not in a supported country, using the en/ prefix.
I list the two objects using the AWS Command Line Interface (AWS CLI):
In the EC2 instance in the US East (N. Virginia) Region, I run this command to download the object:
Then I run the same command in the Europe (Paris) Region:
As expected, I am getting different results from the same URL. I am using the -L option so that cURL is following the redirect it receives. In this way, each command is executing two HTTP requests: the first request receives the HTTP redirect from the CloudFront function, the second request follows the redirect and is not modified by the function because it contains a custom path in the URL (/en/ or /fr/).
To see the actual location of the redirect and all HTTP response headers, I use cURL with the -i option. These are the response headers for the EC2 instance running in the US; the function is executed at an edge location in Virginia:
And these are the response headers for the EC2 instance running in France; this time, the function is executed in an edge location near Paris:
Availability and Pricing
CloudFront Functions is available today and you can use it with new and existing distributions. You can use CloudFront Functions with the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS SDKs, and AWS CloudFormation. With CloudFront Functions, you pay by the number of invocations. You can get started with CloudFront Functions for free as part of the AWS Free Usage Tier. For more information, please see the CloudFront pricing page.
AWS for the Edge
Amazon CloudFront and AWS edge networking capabilities are part of the AWS for the Edge portfolio. AWS edge services improve performance by moving compute, data processing, and storage closer to end-user devices. This includes deploying AWS managed services, APIs, and tools to locations outside AWS data centers, and even onto customer-owned infrastructure and devices.
AWS offers you a consistent experience and portfolio of capabilities from the edge to the cloud. Using AWS, you have access to the broadest and deepest capabilities for edge use cases, like edge networking, hybrid architectures, connected devices, 5G, and multi-access edge computing.
Start using CloudFront Functions today to add custom logic at the edge for your applications.
— Danilo