AWS Big Data Blog
Category: Amazon EMR

Copy large datasets from Google Cloud Storage to Amazon S3 using Amazon EMR
Data migration between GCS and Amazon S3 is possible by utilizing Hadoop’s native support for S3 object storage and using a Google-provided Hadoop connector for GCS. This post demonstrates how to configure an EMR cluster for DistCp and S3DistCP, goes over the settings and parameters for both tools, performs a copy of a test 9.4 TB dataset, and compares the performance of the copy.
Accelerate large-scale data migration validation using PyDeequ
March 2023: You can now use AWS Glue Data Quality to measure and manage the quality of your data. AWS Glue Data Quality is built on DeeQu and it offers a simplified user experience for customers who want to this open-source package. Refer to the blog and documentation for additional details. Many enterprises are migrating their […]
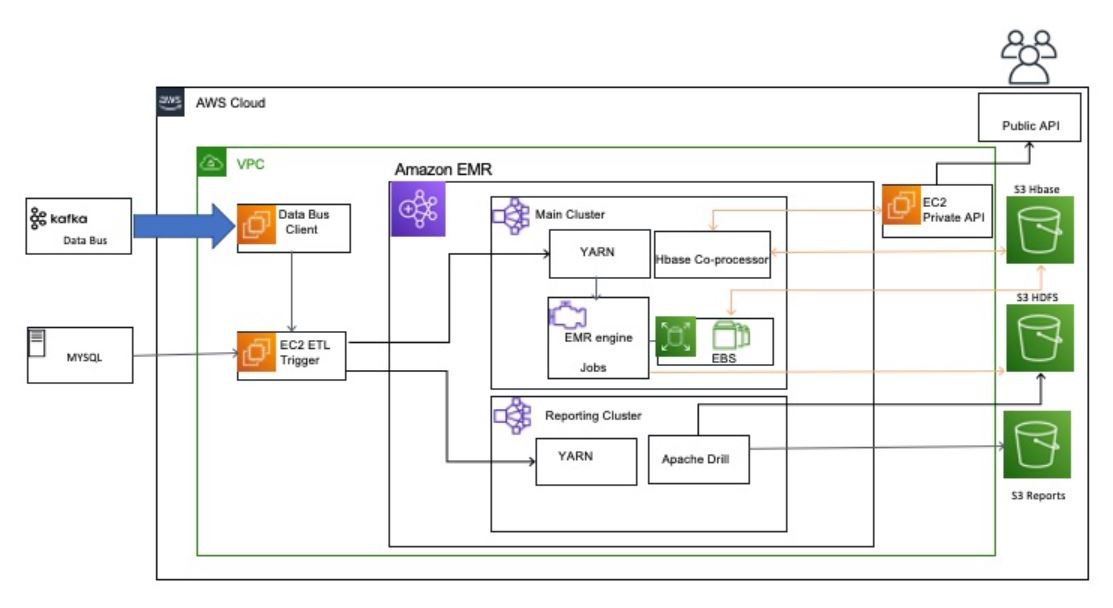
How Viasat scaled their big data applications by migrating to Amazon EMR
This post is co-written with Manoj Gundawar from Viasat. Viasat is a satellite internet service provider based in Carlsbad, CA, with operations across the United States and worldwide. Viasat’s ambition is to be the first truly global, scalable, broadband service provider with a mission to deliver connections that can change the world. Viasat operates across […]
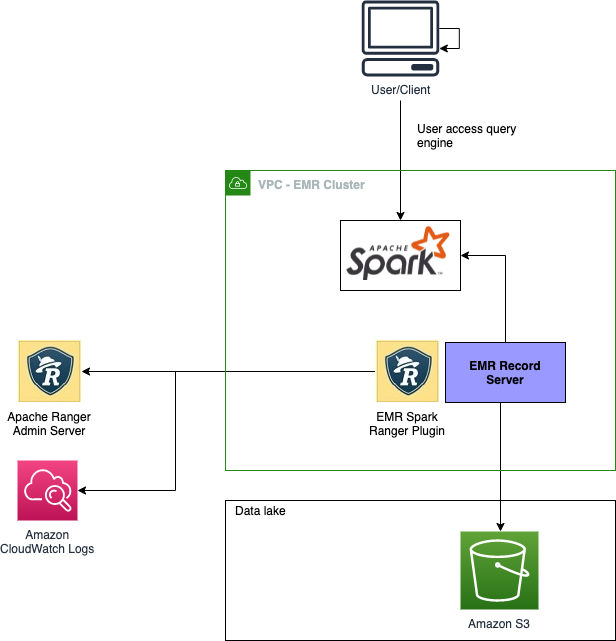
Authorize SparkSQL data manipulation on Amazon EMR using Apache Ranger
This post was last updated July 2022. With Amazon EMR 6.7, all Apache Spark DDL’s are now supported, except for CREATE VIEW. For details, see the section under “limitations”. NOTE: You will need to redeploy Spark service definition (link) on your Apache Ranger server. Instructions on how to redeploy can be found here. With Amazon […]
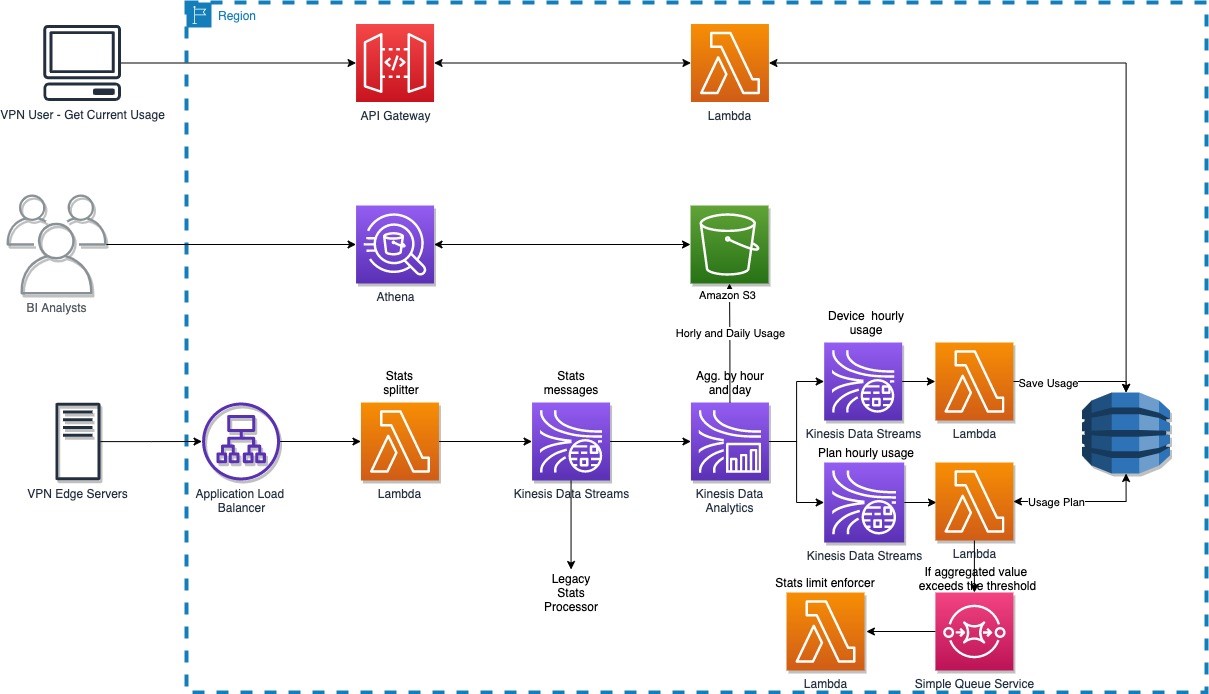
How NortonLifelock built a serverless architecture for real-time analysis of their VPN usage metrics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post presents a reference architecture and optimization strategies for building serverless data analytics solutions on AWS using Amazon Kinesis Data Analytics. In addition, this post shows […]
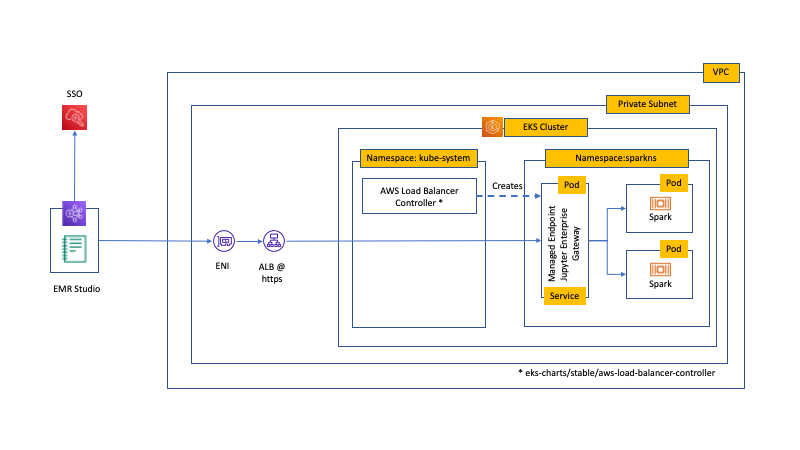
Configure Amazon EMR Studio and Amazon EKS to run notebooks with Amazon EMR on EKS
Amazon EMR on Amazon EKS provides a deployment option for Amazon EMR that allows you to run analytics workloads on Amazon Elastic Kubernetes Service (Amazon EKS). This is an attractive option because it allows you to run applications on a common pool of resources without having to provision infrastructure. In addition, you can use Amazon […]

Reduce costs and increase resource utilization of Apache Spark jobs on Kubernetes with Amazon EMR on Amazon EKS
Amazon EMR on Amazon EKS is a deployment option for Amazon EMR that allows you to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS). If you run open-source Apache Spark on Amazon EKS, you can now use Amazon EMR to automate provisioning and management, and run Apache Spark up to three times faster. […]

Run and debug Apache Spark applications on AWS with Amazon EMR on Amazon EKS
Customers today want to focus more on their core business model and less on the underlying infrastructure and operational burden. As customers migrate to the AWS Cloud, they’re realizing the benefits of being able to innovate faster on their own applications by relying on AWS to handle big data platforms, operations, and automation. Many of […]

Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS
Increasingly, a business’s success depends on its agility in transforming data into actionable insights, which requires efficient and automated data processes. In the previous post – Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, we described a common productivity issue in a modern data architecture. To address the challenge, we demonstrated how to utilize a declarative approach as the key enabler to improve efficiency, which resulted in a faster time to value for businesses. Generally speaking, managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with open-source or in-house build frameworks to achieve the same productivity goal.

Visualize data using Apache Spark running on Amazon EMR with Amazon QuickSight
Organizations often need to process large volumes of data before serving to business stakeholders. In this blog, we will learn how to leverage Amazon EMR to process data using Apache Spark, the go-to platform for in-memory analytics of large data volume, and connect business intelligence (BI) tool Amazon QuickSight to serve data to end-users. QuickSight […]