AWS Big Data Blog
Category: Amazon Kinesis

Build a big data Lambda architecture for batch and real-time analytics using Amazon Redshift
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. With real-time information about customers, products, and applications in hand, organizations can take action as events happen in their business application. For example, you can prevent financial fraud, deliver personalized offers, and […]

Use Amazon Kinesis Data Firehose to extract data insights with Coralogix
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest blog post co-written by Tal Knopf at Coralogix. Digital data is expanding exponentially, and the existing limitations to store and analyze it are constantly being challenged and overcome. […]

Query your data streams interactively using Kinesis Data Analytics Studio and Python
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Kinesis Data Analytics Studio makes it easy for customers to analyze streaming data in real time, as well as build stream processing applications powered by Apache […]

Introducing Protocol buffers (protobuf) schema support in AWS Glue Schema Registry
September 2025: This post was reviewed for accuracy. AWS Glue Schema Registry now supports Protocol buffers (protobuf) schemas in addition to JSON and Avro schemas. This allows application teams to use protobuf schemas to govern the evolution of streaming data and centrally control data quality from data streams to data lake. AWS Glue Schema Registry […]

Use Amazon CodeGuru Profiler to monitor and optimize performance in Amazon Kinesis Data Analytics applications for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Kinesis Data Analytics makes it easy to transform and analyze streaming data and gain actionable insights in real time with Apache Flink. Apache Flink is an […]

Make data available for analysis in seconds with Upsolver low-code data pipelines, Amazon Redshift Streaming Ingestion, and Amazon Redshift Serverless
Amazon Redshift is the most widely used cloud data warehouse. Amazon Redshift makes it easy and cost-effective to perform analytics on vast amounts of data. Amazon Redshift launched Streaming Ingestion for Amazon Kinesis Data Streams, which enables you to load data into Amazon Redshift with low latency and without having to stage the data in […]

Audit AWS service events with Amazon EventBridge and Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon EventBridge is a serverless event bus that makes it easy to build event-driven applications at scale using events generated from your applications, integrated software as a service (SaaS) applications, and AWS […]

How Cynamics built a high-scale, near-real-time, streaming AI inference system using AWS
This post is co-authored by Dr. Yehezkel Aviv, Co-Founder and CTO of Cynamics and Sapir Kraus, Head of Engineering at Cynamics. Cynamics provides a new paradigm of cybersecurity — predicting attacks long before they hit by collecting small network samples (less than 1%), inferring from them how the full network (100%) behaves, and predicting threats […]
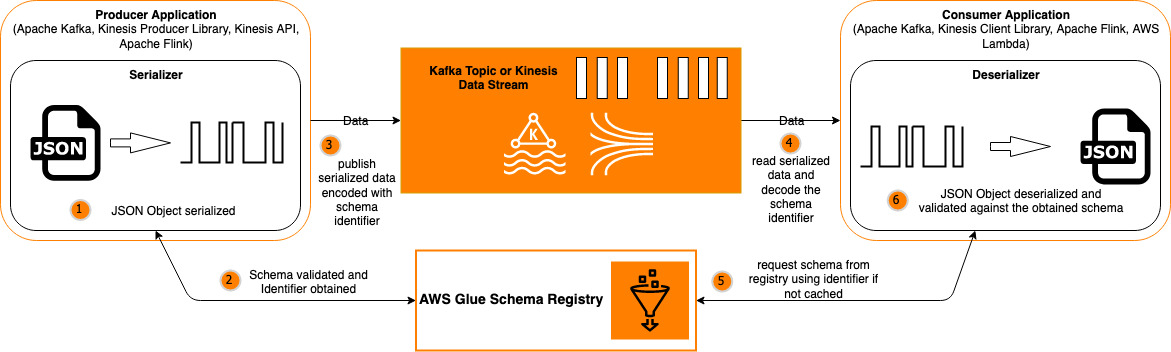
Evolve JSON Schemas in Amazon MSK and Amazon Kinesis Data Streams with the AWS Glue Schema Registry
Data is being produced, streamed, and consumed at an immense rate, and that rate is projected to grow exponentially in the future. In particular, JSON is the most widely used data format across streaming technologies and workloads. As applications, websites, and machines increasingly adopt data streaming technologies such as Apache Kafka and Amazon Kinesis Data […]

Gain insights into your Amazon Kinesis Data Firehose delivery stream using Amazon CloudWatch
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. The volume of data being generated globally is growing at an ever-increasing pace. Data is generated to support an increasing number of use cases, such as IoT, advertisement, gaming, security monitoring, machine […]