AWS Big Data Blog
Category: AWS Glue

Explore visualizations with AWS Glue interactive sessions
AWS Glue interactive sessions offer a powerful way to iteratively explore datasets and fine-tune transformations using Jupyter-compatible notebooks. Interactive sessions enable you to work with a choice of popular integrated development environments (IDEs) in your local environment or with AWS Glue or Amazon SageMaker Studio notebooks on the AWS Management Console, all while seamlessly harnessing […]

Introducing enhanced support for tagging, cross-account access, and network security in AWS Glue interactive sessions
AWS Glue interactive sessions allow you to run interactive AWS Glue workloads on demand, which enables rapid development by issuing blocks of code on a cluster and getting prompt results. This technology is enabled by the use of notebook IDEs, such as the AWS Glue Studio notebook, Amazon SageMaker Studio, or your own Jupyter notebooks. […]
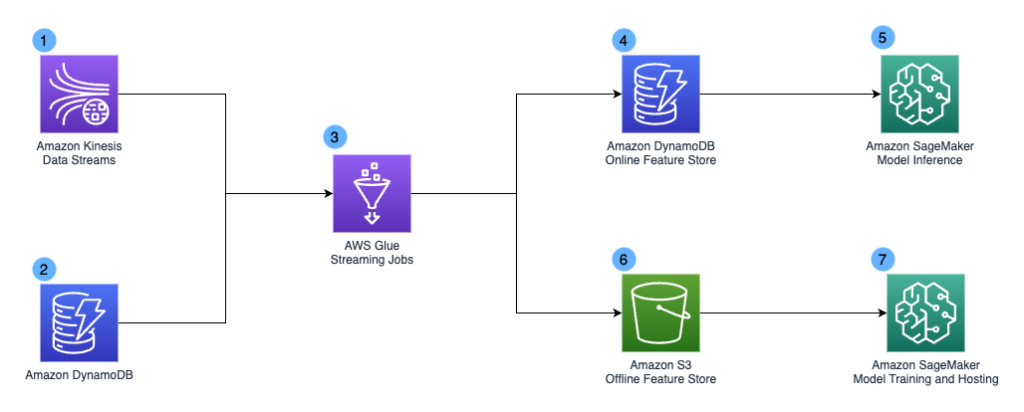
How Chime Financial uses AWS to build a serverless stream analytics platform and defeat fraudsters
This is a guest post by Khandu Shinde, Staff Software Engineer and Edward Paget, Senior Software Engineering at Chime Financial. Chime is a financial technology company founded on the premise that basic banking services should be helpful, easy, and free. Chime partners with national banks to design member first financial products. This creates a more […]

Explore real-world use cases for Amazon CodeWhisperer powered by AWS Glue Studio notebooks
Many customers are interested in boosting productivity in their software development lifecycle by using generative AI. Recently, AWS announced the general availability of Amazon CodeWhisperer, an AI coding companion that uses foundational models under the hood to improve software developer productivity. With Amazon CodeWhisperer, you can quickly accept the top suggestion, view more suggestions, or […]

Simplify operational data processing in data lakes using AWS Glue and Apache Hudi
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started). In AWS ProServe-led customer engagements, the use cases we work on usually come with technical complexity and scalability requirements. In this post, we discuss a common use case in relation to operational data processing and the solution we built using Apache Hudi and AWS Glue.

Securely process near-real-time data from Amazon MSK Serverless using an AWS Glue streaming ETL job with IAM authentication
Streaming data has become an indispensable resource for organizations worldwide because it offers real-time insights that are crucial for data analytics. The escalating velocity and magnitude of collected data has created a demand for real-time analytics. This data originates from diverse sources, including social media, sensors, logs, and clickstreams, among others. With streaming data, organizations […]

Extracting key insights from Amazon S3 access logs with AWS Glue for Ray
This blog post presents an architecture solution that allows customers to extract key insights from Amazon S3 access logs at scale. We will partition and format the server access logs with Amazon Web Services (AWS) Glue, a serverless data integration service, to generate a catalog for access logs and create dashboards for insights.

Query your Iceberg tables in data lake using Amazon Redshift
Amazon Redshift supports querying a wide variety of data formats, such as CSV, JSON, Parquet, and ORC, and table formats like Apache Hudi and Delta. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map. With this capability, Amazon Redshift extends your petabyte-scale data warehouse to an exabyte-scale data lake on Amazon S3 in a cost-effective manner. Apache Iceberg is the latest table format that is supported by Amazon Redshift. In this post, we show you how to query Iceberg tables using Amazon Redshift, and explore Iceberg support and options.

Automate the archive and purge data process for Amazon RDS for PostgreSQL using pg_partman, Amazon S3, and AWS Glue
The post Archive and Purge Data for Amazon RDS for PostgreSQL and Amazon Aurora with PostgreSQL Compatibility using pg_partman and Amazon S3 proposes data archival as a critical part of data management and shows how to efficiently use PostgreSQL’s native range partition to partition current (hot) data with pg_partman and archive historical (cold) data in […]

Introducing AWS Glue crawler and create table support for Apache Iceberg format
Apache Iceberg is an open table format for large datasets in Amazon Simple Storage Service (Amazon S3) and provides fast query performance over large tables, atomic commits, concurrent writes, and SQL-compatible table evolution. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time […]