AWS Big Data Blog
Category: AWS Glue

Migrate data from Azure Blob Storage to Amazon S3 using AWS Glue
In this post, we use Azure Blob Storage as an example and demonstrate how the new connector works, introduce the connector’s functions, and provide you with key steps to set it up. We provide you with prerequisites, share how to subscribe to this connector in AWS Marketplace, and describe how to create and run AWS Glue for Apache Spark jobs with it. Regarding the Azure Data Lake Storage Gen2 Connector, we highlight any major differences in this post.

Load data incrementally from transactional data lakes to data warehouses
Data lakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure. An open table format such as Apache Hudi, Delta Lake, or Apache Iceberg is widely used to build data lakes […]

How healthcare organizations can analyze and create insights using price transparency data
In recent years, there has been a growing emphasis on price transparency in the healthcare industry. Under the Transparency in Coverage (TCR) rule, hospitals and payors to publish their pricing data in a machine-readable format. With this move, patients can compare prices between different hospitals and make informed healthcare decisions. For more information, refer to […]

Automated data governance with AWS Glue Data Quality, sensitive data detection, and AWS Lake Formation
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake. In this post, we showcase how to use AWS Glue with AWS Glue Data Quality, sensitive data detection transforms, and AWS Lake Formation tag-based access control to automate data governance.

Simplify data transfer: Google BigQuery to Amazon S3 using Amazon AppFlow
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow, a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. In this blog post, you explore the new Google BigQuery connector in Amazon AppFlow and discover how it simplifies the process of transferring data from Google’s data warehouse to Amazon Simple Storage Service (Amazon S3), providing significant benefits for data professionals and organizations, including the democratization of multi-cloud data access.

Automate legacy ETL conversion to AWS Glue using Cognizant Data and Intelligence Toolkit (CDIT) – ETL Conversion Tool
In this post, we describe how Cognizant’s Data & Intelligence Toolkit (CDIT)- ETL Conversion Tool can help you automatically convert legacy ETL code to AWS Glue quickly and effectively. We also describe the main steps involved, the supported features, and their benefits.
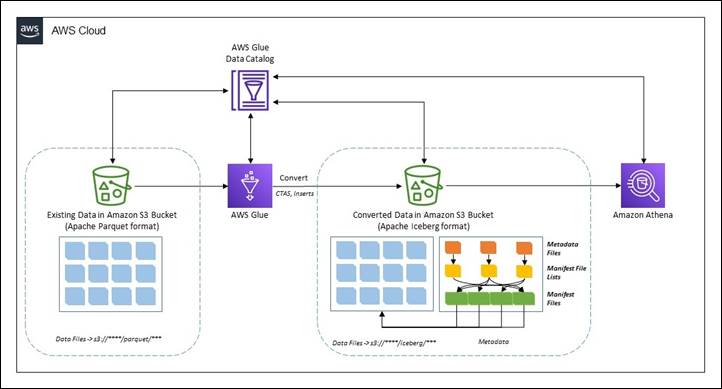
Migrate an existing data lake to a transactional data lake using Apache Iceberg
A data lake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Over the years, data lakes on Amazon Simple Storage […]

Non-JSON ingestion using Amazon Kinesis Data Streams, Amazon MSK, and Amazon Redshift Streaming Ingestion
Organizations are grappling with the ever-expanding spectrum of data formats in today’s data-driven landscape. From Avro’s binary serialization to the efficient and compact structure of Protobuf, the landscape of data formats has expanded far beyond the traditional realms of CSV and JSON. As organizations strive to derive insights from these diverse data streams, the challenge […]

Process and analyze highly nested and large XML files using AWS Glue and Amazon Athena
July 2025: This post was reviewed for accuracy. In today’s digital age, data is at the heart of every organization’s success. One of the most commonly used formats for exchanging data is XML. Analyzing XML files is crucial for several reasons. Firstly, XML files are used in many industries, including finance, healthcare, and government. Analyzing […]

Introducing hybrid access mode for AWS Glue Data Catalog to secure access using AWS Lake Formation and IAM and Amazon S3 policies
To ease the transition of data lake permissions from an IAM and S3 model to Lake Formation, we’re introducing a hybrid access mode for AWS Glue Data Catalog. This feature lets you secure and access the cataloged data using both Lake Formation permissions and IAM and S3 permissions. Hybrid access mode allows data administrators to onboard Lake Formation permissions selectively and incrementally, focusing on one data lake use case at a time. For example, say you have an existing extract, transform and load (ETL) data pipeline that uses the IAM and S3 policies to manage data access. Now you want to allow your data analysts to explore or query the same data using Amazon Athena. You can grant access to the data analysts using Lake Formation permissions, to include fine-grained controls as needed, without changing access for your ETL data pipelines.