AWS Big Data Blog
Category: AWS Glue

Introducing Apache Hudi support with AWS Glue crawlers
Apache Hudi is an open table format that brings database and data warehouse capabilities to data lakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance. Data engineers use Apache Hudi for streaming workloads as well as to create efficient incremental data pipelines. Hudi provides tables, transactions, efficient […]

Enhance monitoring and debugging for AWS Glue jobs using new job observability metrics
For any modern data-driven company, having smooth data integration pipelines is crucial. These pipelines pull data from various sources, transform it, and load it into destination systems for analytics and reporting. When running properly, it provides timely and trustworthy information. However, without vigilance, the varying data volumes, characteristics, and application behavior can cause data pipelines […]

Introducing AWS Glue serverless Spark UI for better monitoring and troubleshooting
Today, we are pleased to announce serverless Spark UI built into the AWS Glue console. You can now use Spark UI easily as it’s a built-in component of the AWS Glue console, enabling you to access it with a single click when examining the details of any given job run. There’s no infrastructure setup or teardown required. AWS Glue serverless Spark UI is a fully-managed serverless offering and generally starts up in a matter of seconds. Serverless Spark UI makes it significantly faster and easier to get jobs working in production because you have ready access to low level details for your job runs.

Visualize Amazon DynamoDB insights in Amazon QuickSight using the Amazon Athena DynamoDB connector and AWS Glue
May 2025: This post was reviewed for accuracy. Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools. The scalability and flexible data schema of DynamoDB make it well-suited for […]
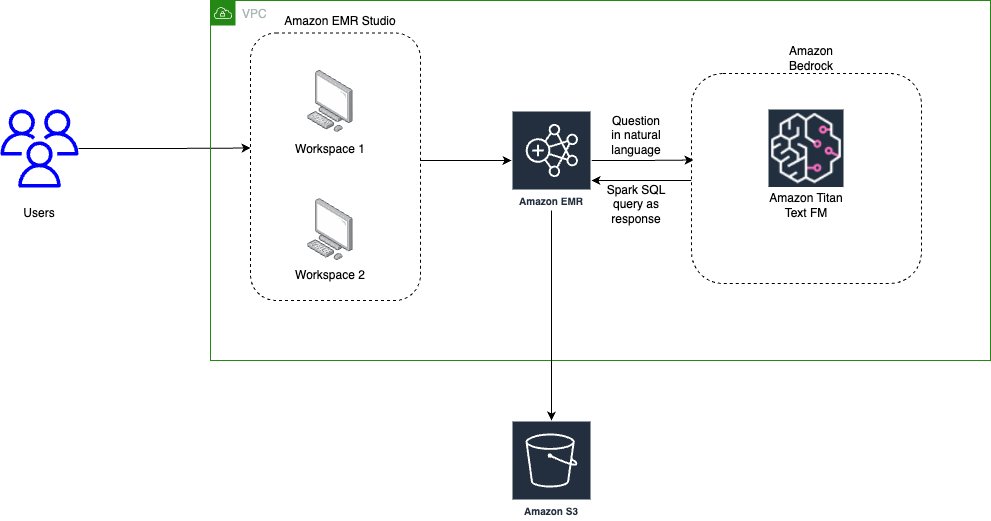
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]

Clean up your Excel and CSV files without writing code using AWS Glue DataBrew
Managing data within an organization is complex. Handling data from outside the organization adds even more complexity. As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. In this blog post, we’ll explore a […]

Deploy Amazon QuickSight dashboards to monitor AWS Glue ETL job metrics and set alarms
No matter the industry or level of maturity within AWS, our customers require better visibility into their AWS Glue usage. Better visibility can lend itself to gains in operational efficiency, informed business decisions, and further transparency into your return on investment (ROI) when using the various features available through AWS Glue. As your company grows, […]

Unlock scalable analytics with AWS Glue and Google BigQuery
Data integration is the foundation of robust data analytics. It encompasses the discovery, preparation, and composition of data from diverse sources. In the modern data landscape, accessing, integrating, and transforming data from diverse sources is a vital process for data-driven decision-making. AWS Glue, a serverless data integration and extract, transform, and load (ETL) service, has […]

Create, train, and deploy Amazon Redshift ML model integrating features from Amazon SageMaker Feature Store
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Data analysts and database developers want to use this data to train machine learning (ML) models, which can then be used to generate insights on new data for use cases such as forecasting […]

Unstructured data management and governance using AWS AI/ML and analytics services
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.