AWS Big Data Blog
Category: AWS Glue

Secure generative SQL with Amazon Q
In this post, we discuss the design and security controls in place when using generative SQL and its use in both Amazon SageMaker Unified Studio and Amazon Redshift Query Editor v2.

Scale your AWS Glue for Apache Spark jobs with R type, G.12X, and G.16X workers
This post demonstrates how AWS Glue R type, G.12X, and G.16X workers help you scale up your AWS Glue for Apache Spark jobs.

Introducing Jobs in Amazon SageMaker
This post demonstrates how the new jobs experience works in SageMaker Unified Studio.

Revenue NSW modernises analytics with AWS, enabling unified and scalable data management, processing, and access
Revenue NSW, Australia’s principal revenue management agency, successfully modernized its analytics infrastructure using AWS services. In this blog post, we show how the organization transformed its on-premises data environment into a unified, scalable cloud-based solution using Amazon Redshift, AWS Database Migration Service, Amazon AppFlow, and AWS Glue.
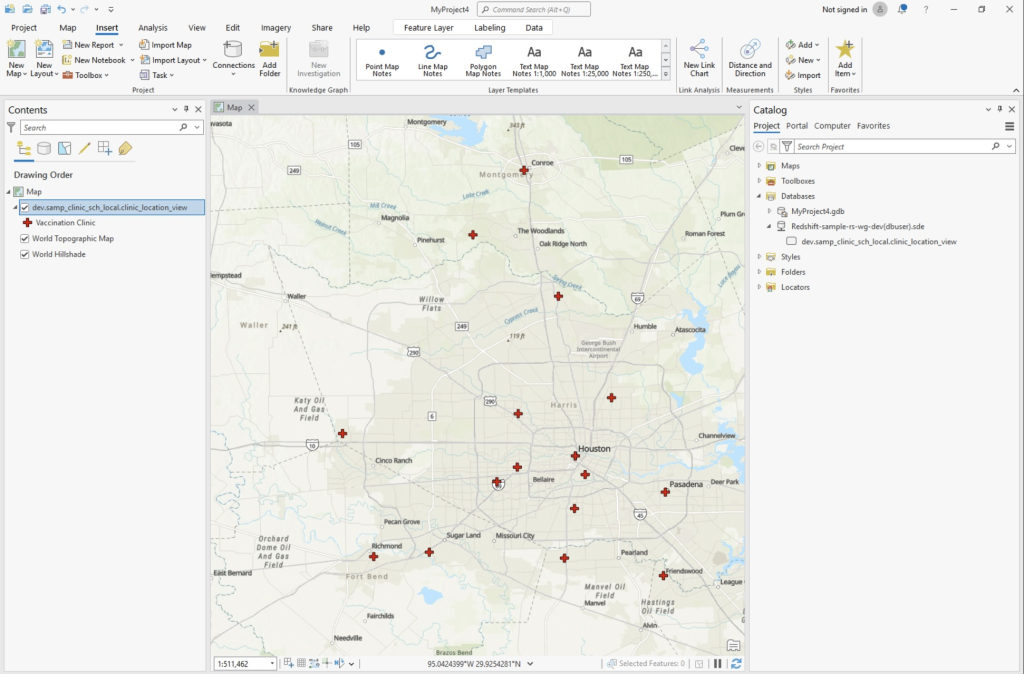
Geospatial data lakes with Amazon Redshift
In this post, we review how to set up Redshift Serverless to use geospatial data contained within a data lake to enhance maps in ArcGIS Pro. This technique helps builders and GIS analysts use available datasets in data lakes and transform it in Amazon Redshift to further enrich the data before presenting it on a map.

How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.

Enforce table level access control on data lake tables using AWS Glue 5.0 with AWS Lake Formation
In this post, we show you how to enforce FTA control on AWS Glue 5.0 through Lake Formation permissions.

Introducing AWS Glue Data Catalog usage metrics for API usage
We’re excited to announce AWS Glue Data Catalog usage metrics. The usage metrics is a new feature that provides native integration with Amazon CloudWatch. In this post, we demonstrate how to access these metrics, provide a step-by-step walkthrough, and set up meaningful alarms.

RocksDB 101: Optimizing stateful streaming in Apache Spark with Amazon EMR and AWS Glue
This post explores RocksDB’s key features and demonstrates its implementation using Spark on Amazon EMR and AWS Glue, providing you with the knowledge you need to scale your real-time data processing capabilities.

Simplify real-time analytics with zero-ETL from Amazon DynamoDB to Amazon SageMaker Lakehouse
At AWS re:Invent 2024, we introduced a no code zero-ETL integration between Amazon DynamoDB and Amazon SageMaker Lakehouse, simplifying how organizations handle data analytics and AI workflows. In this post, we share how to set up this zero-ETL integration from DynamoDB to your SageMaker Lakehouse environment.