AWS Big Data Blog
Category: Analytics
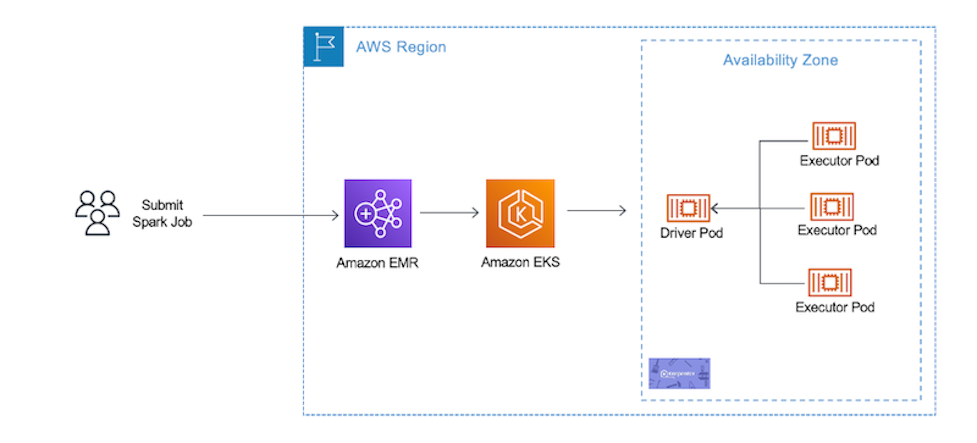
Design patterns to manage Amazon EMR on EKS workloads for Apache Spark
Amazon EMR on Amazon EKS enables you to submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (Amazon EKS) without provisioning clusters. With EMR on EKS, you can consolidate analytical workloads with your other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management. Kubernetes uses namespaces to provide isolation between […]

Best practices to optimize cost and performance for AWS Glue streaming ETL jobs
AWS Glue streaming extract, transform, and load (ETL) jobs allow you to process and enrich vast amounts of incoming data from systems such as Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), or any other Apache Kafka cluster. It uses the Spark Structured Streaming framework to perform data processing in near-real […]
Manage data transformations with dbt in Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. Amazon Redshift enables you to use your data to acquire new insights for your business and customers while keeping costs low. Together with price-performance, […]
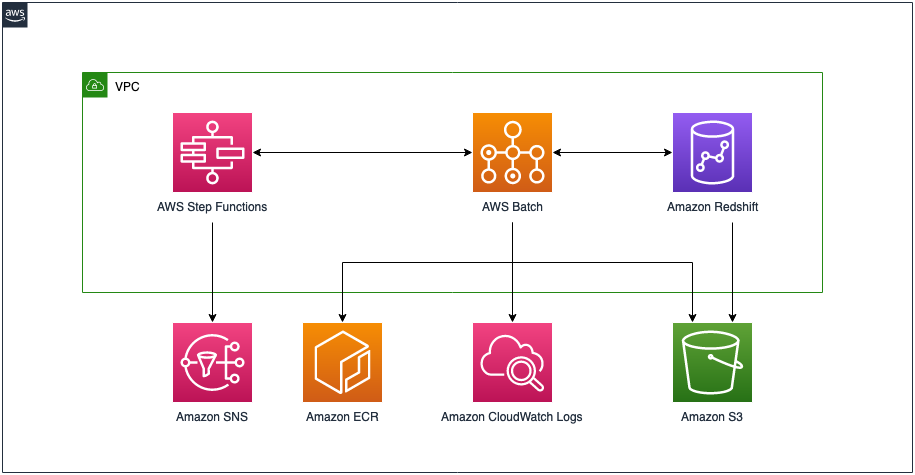
Develop an Amazon Redshift ETL serverless framework using RSQL, AWS Batch, and AWS Step Functions
Amazon Redshift RSQL is a command-line client for interacting with Amazon Redshift clusters and databases. You can connect to an Amazon Redshift cluster, describe database objects, query data, and view query results in various output formats. You can use enhanced control flow commands to replace existing extract, transform, load (ETL) and automation scripts. This post […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Use SQL queries to define Amazon Redshift datasets in AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. In the post Data preparation using Amazon Redshift with AWS Glue DataBrew, we saw how to create an AWS Glue DataBrew job using a JDBC connection for Amazon Redshift. In this post, we show you how to create a DataBrew profile job and a recipe job using […]

Schedule email reports and configure threshold based-email alerts using Amazon QuickSight
Amazon QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to the people you work with, wherever they are. You can build dashboards using combinations of data in the cloud, on premises, in other software as a service (SaaS) apps, and in flat files. Although users can always […]
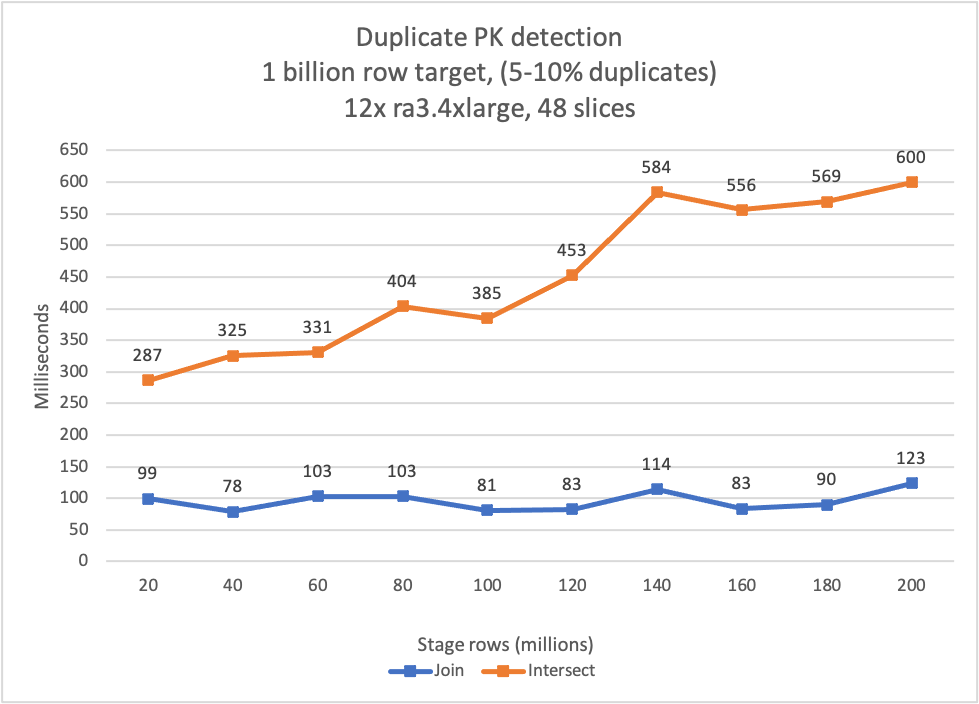
Accelerate your data warehouse migration to Amazon Redshift – Part 6
This is the sixth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift. Check out all the previous posts in this series: […]

Scale Amazon QuickSight embedded analytics with new API-based domain allow listing
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards, and share these with tens of thousands of users, either within QuickSight itself or embedded in apps and portals. QuickSight Enterprise Edition recently introduced the ability to dynamically allow list the domains where […]

Create a most-recent view of your data lake using Amazon Redshift Serverless
Building a robust data lake is very beneficial because it enables organizations have a holistic view of their business and empowers data-driven decisions. The curated layer of a data lake is able to hydrate multiple homogeneous data products, unlocking limitless capabilities to address current and future requirements. However, some concepts of how data lakes work […]