AWS Big Data Blog
Category: Analytics

Query cross-account AWS Glue Data Catalogs using Amazon Athena
Many AWS customers rely on a multi-account strategy to scale their organization and better manage their data lake across different projects or lines of business. The AWS Glue Data Catalog contains references to data used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. Using a centralized Data Catalog […]

Ibotta builds a self-service data lake with AWS Glue
This is a guest post co-written by Erik Franco at Ibotta. Ibotta is a free cash back rewards and payments app that gives consumers real cash for everyday purchases when they shop and pay through the app. Ibotta provides thousands of ways for consumers to earn cash on their purchases by partnering with more than […]
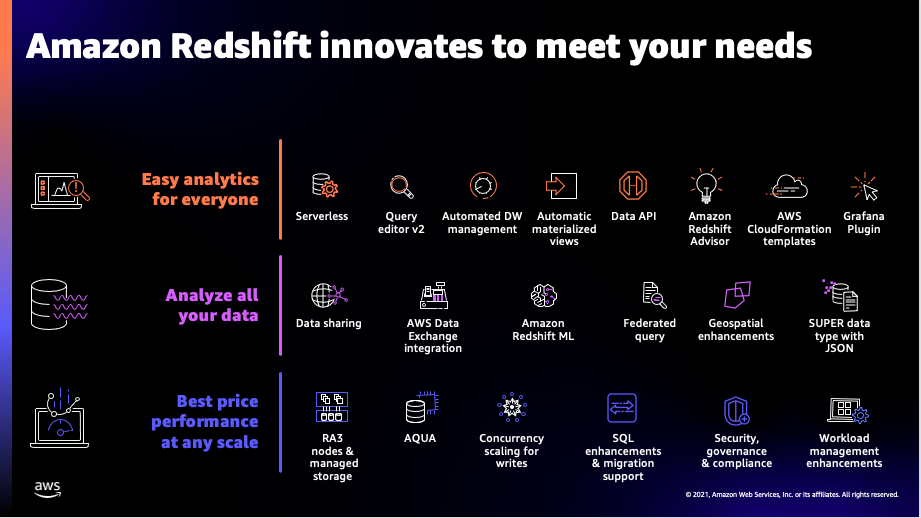
What’s new in Amazon Redshift – 2021, a year in review
Amazon Redshift is the cloud data warehouse of choice for tens of thousands of customers who use it to analyze exabytes of data to gain business insights. Customers have asked for more capabilities in Redshift to make it easier, faster, and secure to store, process, and analyze all of their data. We announced Redshift in 2012 […]

Introducing new features for Amazon Redshift COPY: Part 1
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of […]

How Goldman Sachs built persona tagging using Apache Flink on Amazon EMR
The Global Investment Research (GIR) division at Goldman Sachs is responsible for providing research and insights to the firm’s clients in the equity, fixed income, currency, and commodities markets. One of the long-standing goals of the GIR team is to deliver a personalized experience and relevant research content to their research users. Previously, in order to customize […]
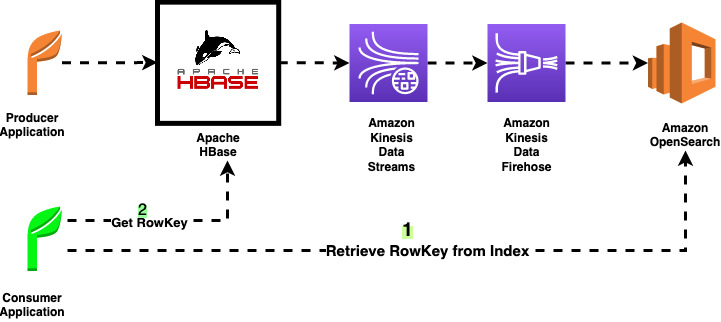
Stream Apache HBase edits for real-time analytics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Apache HBase is a non-relational database. To use the data, applications need to query the database to pull the data and changes from tables. In this post, […]

Unify log aggregation and analytics across compute platforms
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Our customers want to make sure their users have the best experience running their application on AWS. To make this happen, you need to monitor and fix software problems as quickly as […]

Set advanced settings with the Amazon OpenSearch Service Dashboards API
Amazon OpenSearch Service is a fully managed service that you can use to deploy and operate OpenSearch clusters cost-effectively at scale in the AWS Cloud. The service makes it easy for you to perform interactive log analytics, real-time application monitoring, website search, and more by offering the latest versions of OpenSearch, support for 19 versions […]
Use the default IAM role in Amazon Redshift to simplify accessing other AWS services
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse, and can expand to petabyte scale. Today, tens of thousands of AWS […]

ConexED uses Amazon QuickSight to empower its institutional partners by unifying and curating powerful insights using engagement data
This post was co-written with Michael Gorham, Co-Founder and CTO of ConexED. ConexED is one of the country’s fastest-growing EdTech companies designed specifically for education to enhance the student experience and elevate student success. Founded as a startup in 2008 to remove obstacles that hinder student persistence and access to student services, ConexED provides advisors, […]