AWS Big Data Blog
Category: Analytics
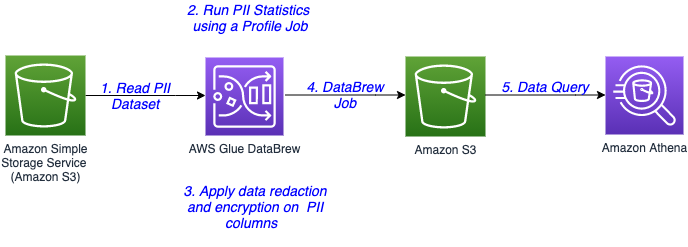
Introducing PII data identification and handling using AWS Glue DataBrew
AWS Glue DataBrew, a visual data preparation tool, now allows users to identify and handle sensitive data by applying advanced transformations like redaction, replacement, encryption, and decryption on their personally identifiable information (PII) data, and other types of data they deem sensitive. With exponential growth of data, companies are handling huge volumes and a wide […]

Attendee guide for the AWS Analytics track at AWS re:Invent 2021
AWS re:Invent is a learning conference hosted by Amazon Web Services (AWS) for the global cloud computing community. We’re super excited to join you at the 10th annual re:Invent to share the latest from AWS leaders and discover more ways to learn and build. Let’s celebrate this milestone, which will be offered in person in […]

Send personalized email reports with Amazon QuickSight
Amazon QuickSight now supports personalization of email reports by user, which allows you to send customized snapshots of data in either PDF or image formats. This allows you to create a single dashboard that you can configure to load with different defaults for each user, providing a customized view of the dashboard in both email […]

Improve Amazon Athena query performance using AWS Glue Data Catalog partition indexes
The AWS Glue Data Catalog provides partition indexes to accelerate queries on highly partitioned tables. In the post Improve query performance using AWS Glue partition indexes, we demonstrated how partition indexes reduce the time it takes to fetch partition information during the planning phase of queries run on Amazon EMR, Amazon Redshift Spectrum, and AWS […]

Accelo uses Amazon QuickSight to accelerate time to value in delivering embedded analytics to professional services businesses
This is a guest post by Accelo. In their own words, “Accelo is the leading cloud-based platform for managing client work, from prospect to payment, for professional services companies. Each month, tens of thousands of Accelo users across 43 countries create more than 3 million activities, log 1.2 million hours of work, and generate over […]

Design and build a Data Vault model in Amazon Redshift from a transactional database
This blog post was updated in June, 2022 to update the entity relationship diagram. Building a highly performant data model for an enterprise data warehouse (EDW) has historically involved significant design, development, administration, and operational effort. Furthermore, the data model must be agile and adaptable to change while handling the largest volumes of data efficiently. […]

Federate Amazon Redshift access with SecureAuth single sign-on
Amazon Redshift is the leading cloud data warehouse that delivers up to 3x better price performance compared to other cloud data warehouses by using massively parallel query execution, columnar storage on high-performance disks, and results caching. You can confidently run mission-critical workloads, even in highly regulated industries, because Amazon Redshift comes with out-of-the-box security and […]
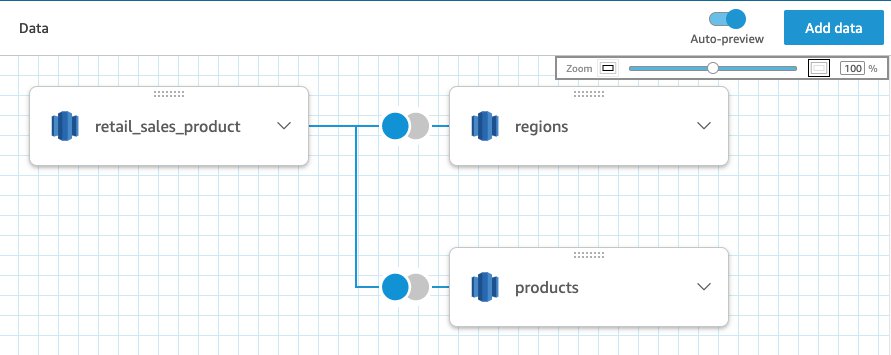
Create larger SPICE datasets and refresh data faster in Amazon QuickSight with new SPICE features
Amazon QuickSight is a scalable business intelligence (BI) service built for the cloud, which allows insights to be shared with all users in the organization. QuickSight offers SPICE, an in-memory, cloud-native data store that allows end-users to interactively explore data. SPICE provides consistently fast query performance and automatically scales for high concurrency. With SPICE, you […]

Use the Amazon Redshift SQLAlchemy dialect to interact with Amazon Redshift
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that enables you to analyze your data at scale. You can interact with an Amazon Redshift database in several different ways. One method is using an object-relational mapping (ORM) framework. ORM is widely used by developers as an abstraction layer upon the […]
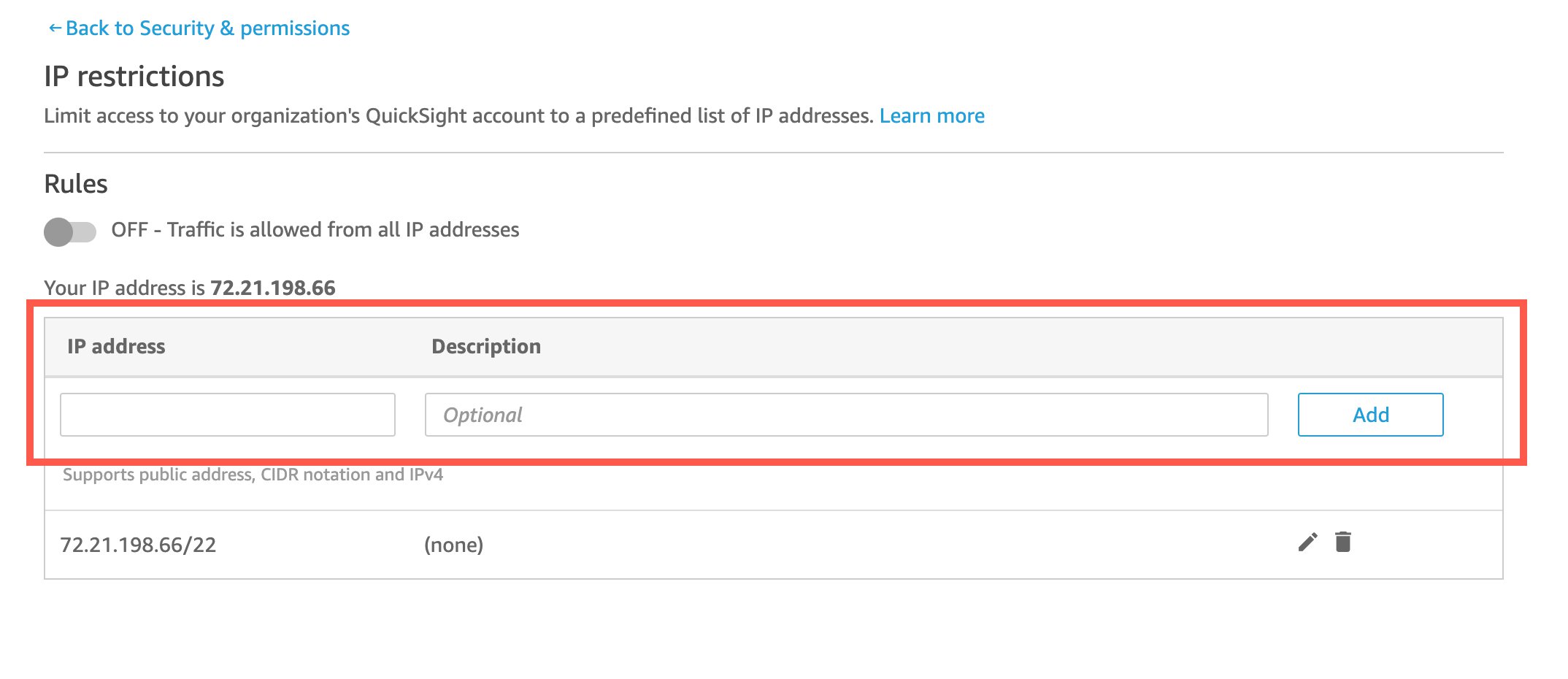
Use IP restrictions to control access to Amazon QuickSight
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards, and share these with tens of thousands of users, either within the QuickSight interface, or embedded in software as a service (SaaS) applications or web portals. Unlike many of the other solutions in […]