AWS Big Data Blog
Category: Expert (400)

How EchoStar ingests terabytes of data daily across its 5G Open RAN network in near real-time using Amazon Redshift Serverless Streaming Ingestion
EchoStar, a connectivity company providing television entertainment, wireless communications, and award-winning technology to residential and business customers throughout the US, deployed the first standalone, cloud-native Open RAN 5G network on AWS public cloud. This post provides an overview of real-time data analysis with Amazon Redshift and how EchoStar uses it to ingest hundreds of megabytes per second. As data sources and volumes grew across its network, EchoStar migrated from a single Redshift Serverless workgroup to a multi-warehouse architecture with live data sharing.

Build multimodal search with Amazon OpenSearch Service
Multimodal search enables both text and image search capabilities, transforming how users access data through search applications. Consider building an online fashion retail store: you can enhance the users’ search experience with a visually appealing application that customers can use to not only search using text but they can also upload an image depicting a […]

Detect and handle data skew on AWS Glue
October 2024: This post was reviewed and updated for accuracy. AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell or Spark). Data skew occurs when the data being […]

Best practices to implement near-real-time analytics using Amazon Redshift Streaming Ingestion with Amazon MSK
Amazon Redshift is a fully managed, scalable cloud data warehouse that accelerates your time to insights with fast, straightforward, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud data warehouse. You can run […]

Use AWS Glue ETL to perform merge, partition evolution, and schema evolution on Apache Iceberg
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. However, altering schema and table partitions in traditional data lakes can be a disruptive and time-consuming task, requiring renaming or recreating entire tables and reprocessing large datasets. […]
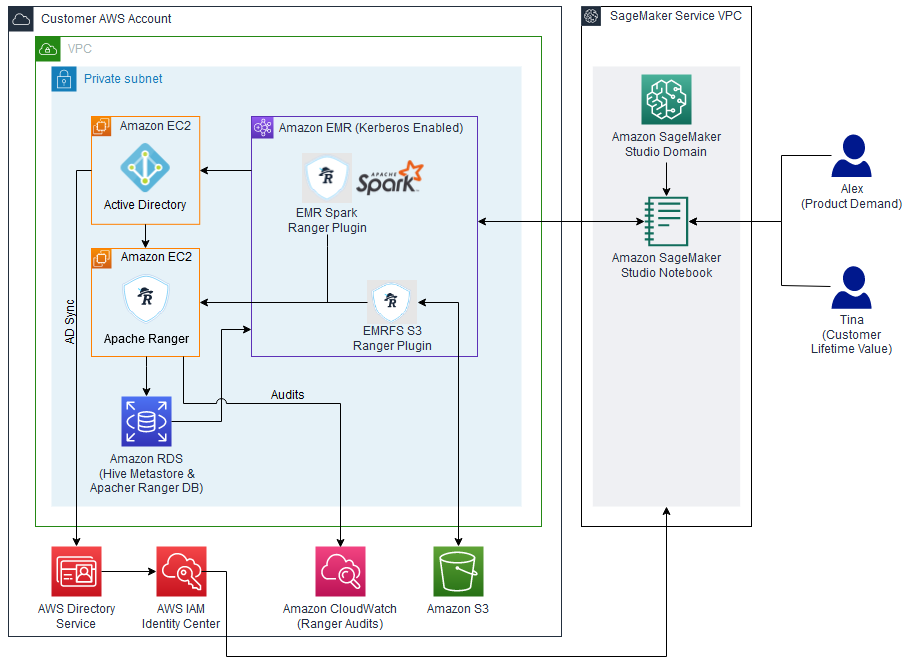
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.

Resolve private DNS hostnames for Amazon MSK Connect
Amazon MSK Connect is a feature of Amazon Managed Streaming for Apache Kafka (Amazon MSK) that offers a fully managed Apache Kafka Connect environment on AWS. With MSK Connect, you can deploy fully managed connectors built for Kafka Connect that move data into or pull data from popular data stores like Amazon S3 and Amazon […]

Enhance your security posture by storing Amazon Redshift admin credentials without human intervention using AWS Secrets Manager integration
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. Today, tens of thousands of AWS customers—from Fortune 500 companies, startups, and everything in between—use Amazon Redshift to run mission-critical business intelligence (BI) dashboards, […]

Explore real-world use cases for Amazon CodeWhisperer powered by AWS Glue Studio notebooks
Many customers are interested in boosting productivity in their software development lifecycle by using generative AI. Recently, AWS announced the general availability of Amazon CodeWhisperer, an AI coding companion that uses foundational models under the hood to improve software developer productivity. With Amazon CodeWhisperer, you can quickly accept the top suggestion, view more suggestions, or […]

Multi-tenancy Apache Kafka clusters in Amazon MSK with IAM access control and Kafka Quotas – Part 1
With Amazon Managed Streaming for Apache Kafka (Amazon MSK), you can build and run applications that use Apache Kafka to process streaming data. To process streaming data, organizations either use multiple Kafka clusters based on their application groupings, usage scenarios, compliance requirements, and other factors, or a dedicated Kafka cluster for the entire organization. It […]