AWS Big Data Blog
Category: Intermediate (200)

Developer guidance on how to do local testing with Amazon MSK Serverless
In this post, I present you with guidance on how developers can connect to Amazon MSK Serverless from local environments. The connection is done using an Amazon MSK endpoint through an SSH tunnel and a bastion host. This enables developers to experiment and test locally, without needing to setup a separate Kafka cluster.

Publish and enrich real-time financial data feeds using Amazon MSK and Amazon Managed Service for Apache Flink
In this post, we demonstrate how you can publish an enriched real-time data feed on AWS using Amazon Managed Streaming for Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. You can apply this architecture pattern to various use cases within the capital markets industry; we discuss some of those use cases in this post.

Amazon Redshift data ingestion options
Amazon Redshift, a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. Whether your data resides in operational databases, data lakes, on-premises systems, Amazon Elastic Compute Cloud (Amazon EC2), or other AWS services, Amazon Redshift provides multiple ingestion methods to meet your specific needs. The currently […]

Use the AWS CDK with the Data Solutions Framework to provision and manage Amazon Redshift Serverless
In this post, we demonstrate how to use the AWS CDK and DSF to create a multi-data warehouse platform based on Amazon Redshift Serverless. DSF simplifies the provisioning of Redshift Serverless, initialization and cataloging of data, and data sharing between different data warehouse deployments.

Integrate Tableau and Microsoft Entra ID with Amazon Redshift using AWS IAM Identity Center
This blog post provides a step-by-step guide to integrating IAM Identity Center with Microsoft Entra ID as the IdP and configuring Amazon Redshift as an AWS managed application. Additionally, you’ll learn how to set up the Amazon Redshift driver in Tableau, enabling SSO directly within Tableau Desktop.

Attribute Amazon EMR on EC2 costs to your end-users
In this post, we share a chargeback model that you can use to track and allocate the costs of Spark workloads running on Amazon EMR on EC2 clusters. We describe an approach that assigns Amazon EMR costs to different jobs, teams, or lines of business. You can use this feature to distribute costs across various business units. This can assist you in monitoring the return on investment for your Spark-based workloads.

Copy and mask PII between Amazon RDS databases using visual ETL jobs in AWS Glue Studio
In this post, I’ll walk you through how to copy data from one Amazon Relational Database Service (Amazon RDS) for PostgreSQL database to another, while scrubbing PII along the way using AWS Glue. You will learn how to prepare a multi-account environment to access the databases from AWS Glue, and how to model an ETL data flow that automatically masks PII as part of the transfer process, so that no sensitive information will be copied to the target database in its original form.
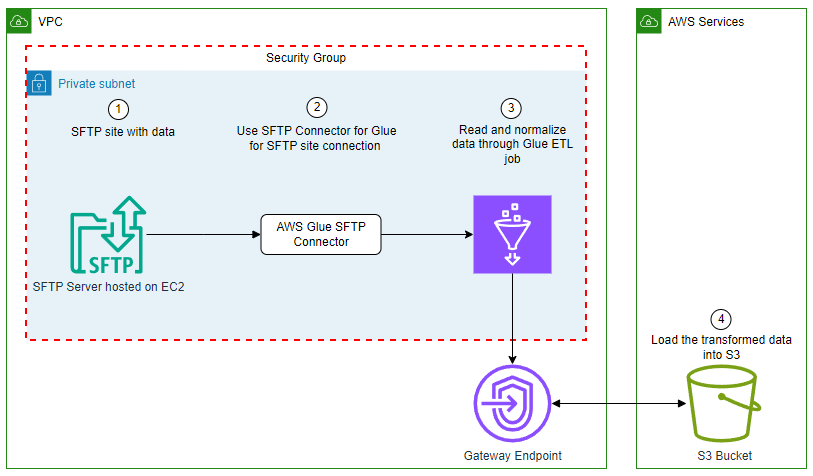
Use AWS Glue to streamline SFTP data processing
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3), further empowering your data analytics and insights.

Automate Amazon Redshift Advisor recommendations with email alerts using an API
Amazon Redshift Advisor offers recommendations about optimizing your Redshift cluster performance and helps you save on operating costs. In this post, we show you how to use the ListRecommendations API to set up email notifications for Advisor recommendations on your Redshift cluster. These recommendations, such as identifying tables that should be vacuumed to sort the data or finding table columns that are candidates for compression, can help improve performance and save costs.

Migrate Amazon Redshift from DC2 to RA3 to accommodate increasing data volumes and analytics demands
As businesses strive to make informed decisions, the amount of data being generated and required for analysis is growing exponentially. This trend is no exception for Dafiti, an ecommerce company that recognizes the importance of using data to drive strategic decision-making processes. With the ever-increasing volume of data available, Dafiti faces the challenge of effectively managing and extracting valuable insights from this vast pool of information to gain a competitive edge and make data-driven decisions that align with company business objectives. The growing need for storage space to maintain data from over 90 sources and the functionality available on the new Amazon Redshift node types, including managed storage, data sharing, and zero-ETL integrations, led us to migrate from DC2 to RA3 nodes. In this post, we share how we handled the migration process and provide further impressions of our experience.