AWS Big Data Blog
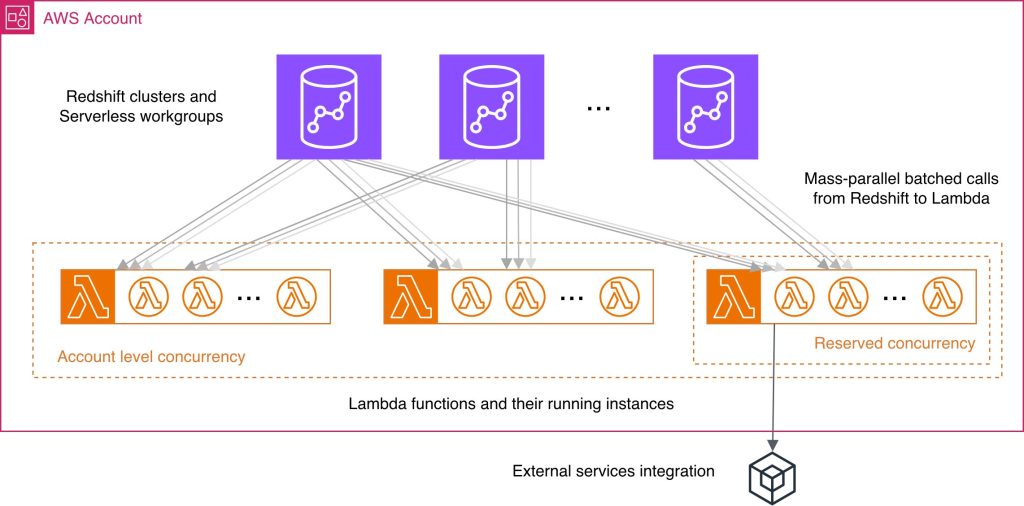
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.
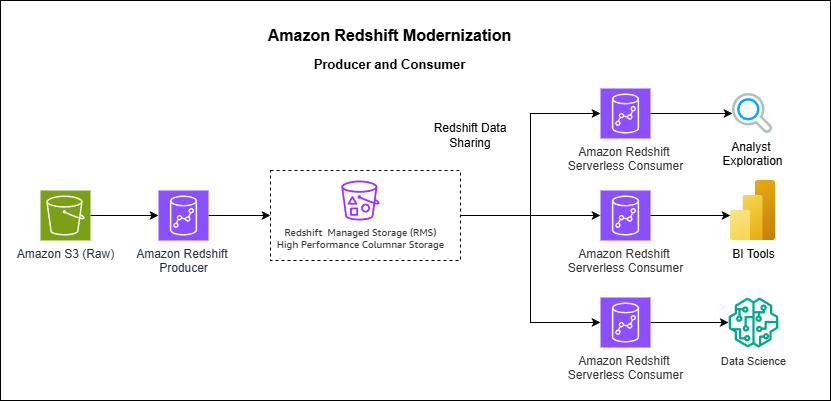
How Vanguard transformed analytics with Amazon Redshift multi-warehouse architecture
In this post, Vanguard’s Financial Advisor Services division describes how they evolved from a single Amazon Redshift cluster to a multi-warehouse architecture using data sharing and serverless endpoints to eliminate performance bottlenecks caused by exponential growth in ETL jobs, dashboards, and user queries.

Scale fine-grained permissions across warehouses with Amazon Redshift and AWS IAM Identity Center
This post provides a comprehensive technical walkthrough for implementing Amazon Redshift federated permissions with AWS IAM Identity Center to help achieve scalable data governance across multiple data warehouses. It demonstrates a practical architecture where an Enterprise Data Warehouse (EDW) serves as the producer data warehouse with centralized policy definitions, helping automatically enforce security policies to consuming Sales and Marketing data warehouses without manual reconfiguration.

Building a scalable, transactional data lake using dbt, Amazon EMR, and Apache Iceberg
Growing data volume, variety, and velocity has made it crucial for businesses to implement architectures that efficiently manage and analyze data, while maintaining data integrity and consistency. In this post, we show you a solution that combines Apache Iceberg, Data Build Tool (dbt), and Amazon EMR to create a scalable, ACID-compliant transactional data lake. You can use this data lake to process transactions and analyze data simultaneously while maintaining data accuracy and real-time insights for better decision-making.
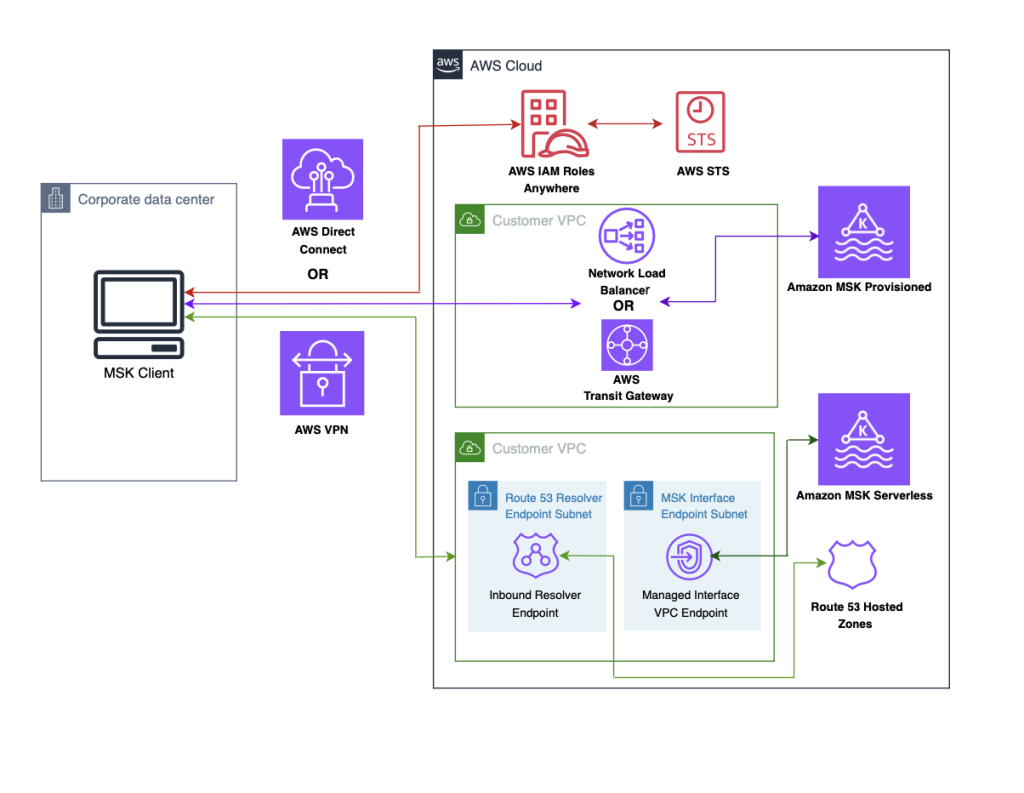
Securely connect Kafka clients running outside AWS to Amazon MSK with IAM Roles Anywhere
In this post, we demonstrate how to use AWS IAM Roles Anywhere to request temporary AWS security credentials, using x.509 certificates for client applications which enables secure interactions with an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster. The solution described in this post is compatible with both Amazon MSK Provisioned and Serverless clusters.

Amazon Redshift DC2 migration approach with a customer case study
In this post, we share insights from one of our customers’ migration from DC2 to RA3 instances. The customer, a large enterprise in the retail industry, operated a 16-node dc2.8xlarge cluster for business intelligence (BI) and ETL workloads. Facing growing data volumes and disk capacity limitations, they successfully migrated to RA3 instances using a Blue-Green deployment approach, achieving improved ETL query performance and expanded storage capacity while maintaining cost efficiency.

Reducing costs for shuffle-heavy Apache Spark workloads with serverless storage for Amazon EMR Serverless
In this post, we explore the cost improvements we observed when benchmarking Apache Spark jobs with serverless storage on EMR Serverless. We take a deeper look at how serverless storage helps reduce costs for shuffle-heavy Spark workloads, and we outline practical guidance on identifying the types of queries that can benefit most from enabling serverless storage in your EMR Serverless Spark jobs.

Optimize HBase reads with bucket caching on Amazon EMR
In this post, we demonstrate how to improve HBase read performance by implementing bucket caching on Amazon EMR. Our tests reduced latency by 57.9% and improved throughput by 138.8%. This solution is particularly valuable for large-scale HBase deployments on Amazon S3 that need to optimize read performance while managing costs.

Kinesis On-demand Advantage saves 60%+ on streaming costs
On November 4, 2025, Amazon Kinesis Data Streams introduced On-demand Advantage mode, a capability that enables on-demand streams to handle instant throughput increases at scale and cost optimization for consistent streaming workloads. Historically, you had to choose between provisioned mode, which required managing stream capacity, and on-demand mode, which automatically scaled capacity, but this new offering removes the need to think about stream type at all. In this post, we show three real-world scenarios comparing different usage patterns and demonstrate how On-demand Advantage mode can optimize your streaming costs while maintaining performance and flexibility.

How Razorpay achieved 11% performance improvement and 21% cost reduction with Amazon EMR
In this post, we explore how Razorpay, India’s leading FinTech company, transformed their data platform by migrating from a third-party solution to Amazon EMR, unlocking improved performance and significant cost savings. We’ll walk through the architectural decisions that guided this migration, the implementation strategy, and the measurable benefits Razorpay achieved.