AWS Big Data Blog

How Amplitude implemented natural language-powered analytics using Amazon OpenSearch Service as a vector database
Amplitude is a product and customer journey analytics platform. Our customers wanted to ask deep questions about their product usage. Ask Amplitude is an AI assistant that uses large language models (LLMs). It combines schema search and content search to provide a customized, accurate, low latency, natural language-based visualization experience to end customers. Amplitude’s search architecture evolved to scale, simplify, and cost-optimize for our customers, by implementing semantic search and Retrieval Augmented Generation (RAG) powered by Amazon OpenSearch Service. In this post, we walk you through Amplitude’s iterative architectural journey and explore how we address several critical challenges in building a scalable semantic search and analytics platform.
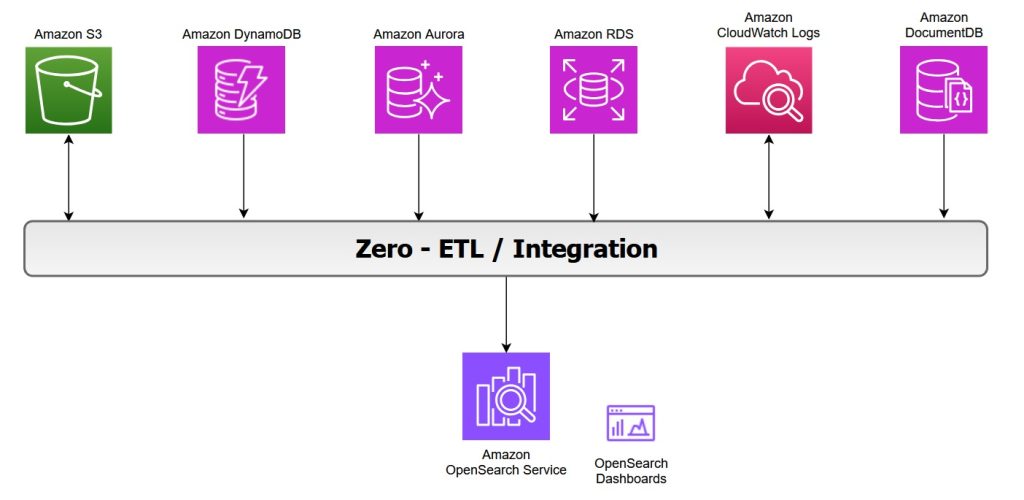
Zero-ETL integrations with Amazon OpenSearch Service
OpenSearch Service offers zero-ETL integrations with other Amazon Web Service (AWS) services, enabling seamless data access and analysis without the need for maintaining complex data pipelines. Zero-ETL refers to a set of integrations designed to minimize or eliminate the need to build traditional extract, transform, load (ETL) pipelines. In this post, we explore various zero-ETL integrations available with OpenSearch Service that can help you accelerate innovation and improve operational efficiency.
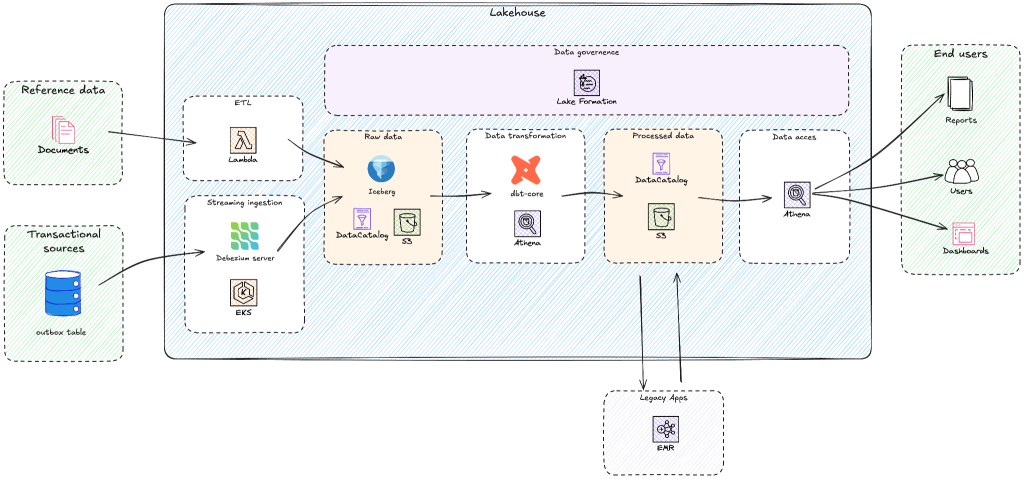
Building a modern lakehouse architecture: Yggdrasil Gaming’s journey from BigQuery to AWS
Yggdrasil Gaming develops and publishes casino games globally, processing massive amounts of real-time gaming data for game performance analytics, player behavior insights, and industry intelligence. Yggdrasil Gaming reduced multi-cloud complexity and built a scalable analytics foundation by migrating from Google BigQuery to AWS analytics services. In this post, you’ll discover how Yggdrasil Gaming transformed their data architecture to meet growing business demands. You will learn practical strategies for migrating from proprietary systems to open table formats such as Apache Iceberg while maintaining business continuity. Yggdrasil worked with GOStack, an AWS Partner, to migrate to an Apache Iceberg-based lakehouse architecture. The migration helped reduce operational complexity and enabled real-time gaming analytics and machine learning.

Set up production-ready monitoring for Amazon MSK using CloudWatch alarms
In this post, I show you how to implement effective monitoring for your Kafka clusters using Amazon MSK and Amazon CloudWatch. You’ll learn how to track critical metrics like broker health, resource utilization, and consumer lag, and set up automated alerts to prevent operational issues.

Standardize Amazon Redshift operations using Templates
In this post, we introduce Redshift Templates and show examples of how they can standardize and simplify your data loading operations across different scenarios. By encapsulating common COPY command parameters into reusable database objects, templates help remove repetitive parameter specifications, facilitate consistency across teams, and centralize maintenance.
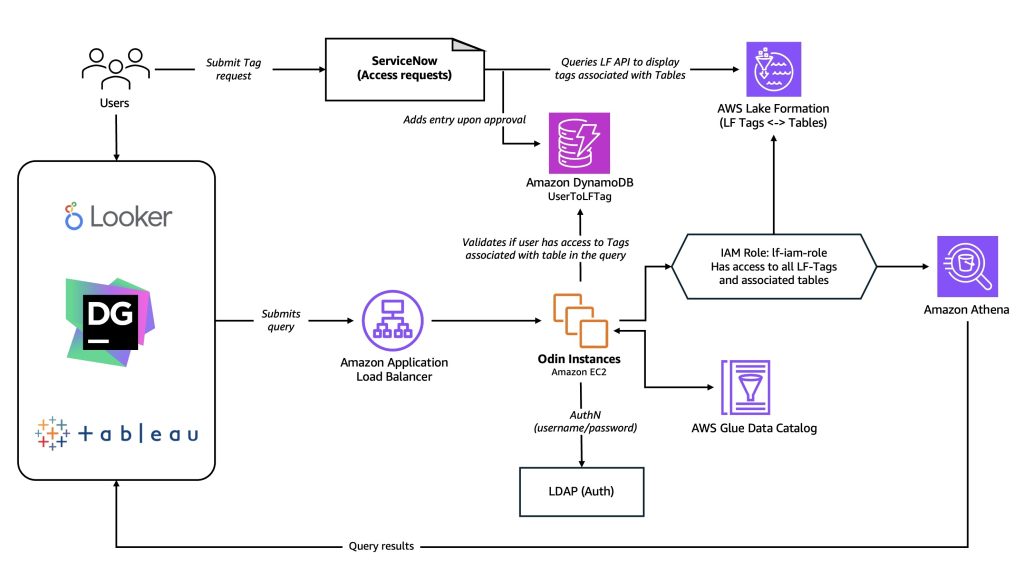
How Twilio secured their multi-engine query platform with AWS Lake Formation
Twilio is a cloud communications platform that provides programmable APIs and tools for developers to easily integrate voice, messaging, email, video, and other communication features into their applications and customer engagement workflows. In this blog series we discuss how we built a multi-engine query platform at Twilio. The first part introduces the use case that led us to build a new platform and why we selected Amazon Athena alongside our open-source Presto implementation. This second part discusses how Twilio’s query infrastructure platform integrates with AWS Lake Formation to provide fine-grained access control to all their data.

Amazon OpenSearch Serverless introduces collection groups to optimize cost for multi-tenant workloads
Today, we’re excited to announce the general availability of the collection groups feature for Amazon OpenSearch Serverless. With this feature you can reduce compute costs for multi-tenant workloads while creating secure tenant boundaries through per-tenant encryption, giving you the flexibility to balance cost efficiency with the exact level of isolation and security your applications requires.

Improving order history search using semantic search with Amazon OpenSearch Service
If you’ve ever shopped on Amazon, you’ve used Your Orders. This feature maintains your complete order history dating back to 1995, so you can track and manage every purchase you’ve made. The order history search feature lets you find your past purchases by entering keywords in the search bar. Beyond just finding items, it provides a straightforward way to repurchase the same or similar items, saving you time and effort. In this post, we show you how the Your Orders team improved order history search by introducing semantic search capabilities on top of our existing lexical search system, using Amazon OpenSearch Service and Amazon SageMaker.
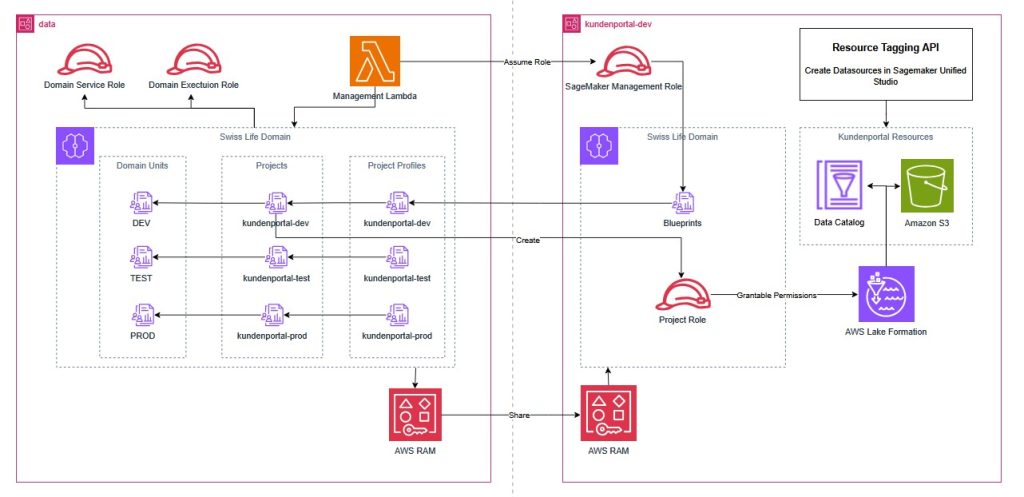
How Swiss Life Germany automated data governance and collaboration with Amazon SageMaker
Swiss Life Germany, a leading provider of customized pension products with over 100 years of experience, recently transitioned from legacy on-premises infrastructure to a modern cloud architecture. To enable secure data sharing and cross-departmental collaboration in this regulated environment, they implemented Amazon SageMaker with a custom Terraform pattern. This post demonstrates how Swiss Life Germany aligned SageMaker’s agility with their rigorous infrastructure as code standards, providing a blueprint for platform engineers and data architects in highly regulated enterprises.

Implement a data mesh pattern in Amazon SageMaker Catalog without changing applications
In this post, we walk through simulating a scenario based on data producer and data consumer that exists before Amazon SageMaker Catalog adoption. We use a sample dataset to simulate existing data and an existing application using an AWS Lambda function, then implement a data mesh pattern using Amazon SageMaker Catalog while keeping your current data repositories and consumer applications unchanged.