AWS Big Data Blog
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
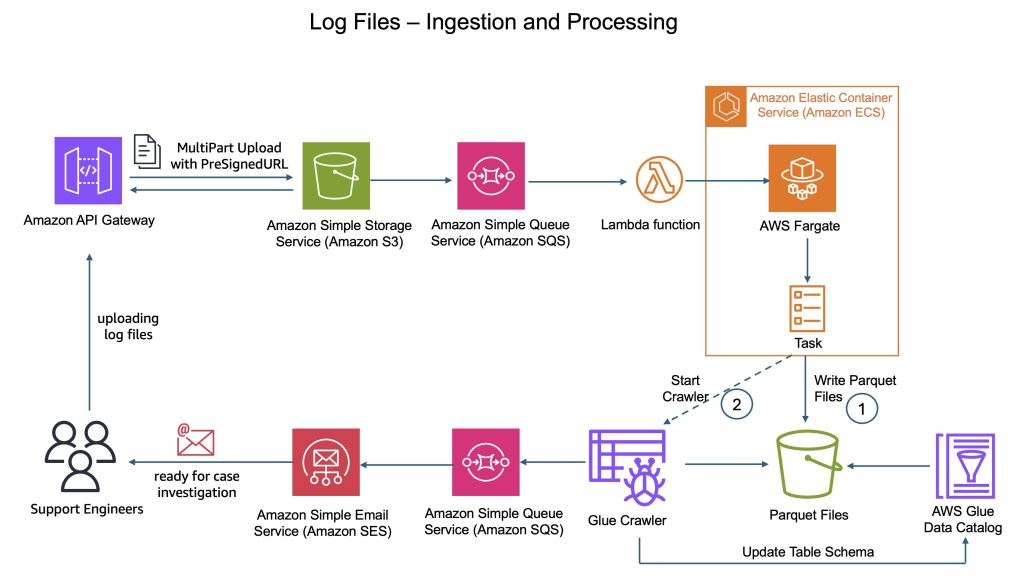
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.

Best practices for right-sizing Amazon OpenSearch Service domains
In this post, we guide you through the steps to determine if your OpenSearch Service domain is right-sized, using AWS tools and best practices to optimize your configuration for workloads like log analytics, search, vector search, or synthetic data testing.

Amazon Managed Service for Apache Flink application lifecycle management with Terraform
In this post, you’ll learn how to use Terraform to automate and streamline your Apache Flink application lifecycle management on Amazon Managed Service for Apache Flink. We’ll walk you through the complete lifecycle including deployment, updates, scaling, and troubleshooting common issues. This post builds upon our two-part blog series “Deep dive into the Amazon Managed Service for Apache Flink application lifecycle”.

Build a data pipeline from Google Search Console to Amazon Redshift using AWS Glue
In this post, we explore how AWS Glue extract, transform, and load (ETL) capabilities connect Google applications and Amazon Redshift, helping you unlock deeper insights and drive data-informed decisions through automated data pipeline management. We walk you through the process of using AWS Glue to integrate data from Google Search Console and write it to Amazon Redshift.

Verisk cuts processing time and storage costs with Amazon Redshift and lakehouse
Verisk, a catastrophe modeling SaaS provider serving insurance and reinsurance companies worldwide, cut processing time from hours to minutes-level aggregations while reducing storage costs by implementing a lakehouse architecture with Amazon Redshift and Apache Iceberg. If you’re managing billions of catastrophe modeling records across hurricanes, earthquakes, and wildfires, this approach eliminates the traditional compute-versus-cost trade-off by separating storage from processing power. In this post, we examine Verisk’s lakehouse implementation, focusing on four architectural decisions that delivered measurable improvements.

Amazon OpenSearch Service 101: T-shirt size your domain for e-commerce search
While general sizing guidelines for OpenSearch Service domains are covered in detail in OpenSearch Service documentation, in this post we specifically focus on T-shirt-sizing OpenSearch Service domains for e-commerce search workloads. T-shirt sizing simplifies complex capacity planning by categorizing workloads into sizes like XS, S, M, L, XL based on key workload parameters such as data volume and query concurrency.

Common streaming data enrichment patterns in Amazon Managed Service for Apache Flink
This post was originally published in March 2024 and updated in February 2026. Stream data processing allows you to act on data in real time. Real-time data analytics can help you have on-time and optimized responses while improving overall customer experience. Apache Flink is a distributed computation framework that allows for stateful real-time data processing. It […]

Matching your Ingestion Strategy with your OpenSearch Query Patterns
In this post, we demonstrate how you can create a custom index analyzer in OpenSearch to implement autocomplete functionality efficiently by using the Edge n-gram tokenizer to match prefix queries without using wildcards.

Amazon Athena adds 1-minute reservations and new capacity control features
Amazon Athena is a serverless interactive query service that makes it easy to analyze data using SQL. With Athena, there’s no infrastructure to manage, you simply submit queries and get results. Capacity Reservations is a feature of Athena that addresses the need to run critical workloads by providing dedicated serverless capacity for workloads you specify. In this post, we highlight three new capabilities that make Capacity Reservations more flexible and easier to manage: reduced minimums for fine-grained capacity adjustments, an autoscaling solution for dynamic workloads, and capacity cost and performance controls.

How Zalando innovates their Fast-Serving layer by migrating to Amazon Redshift
In this post, we show how Zalando migrated their fast-serving layer data warehouse to Amazon Redshift to achieve better price-performance and scalability.