AWS Big Data Blog

Validate streaming data over Amazon MSK using schemas in cross-account AWS Glue Schema Registry
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Today’s businesses face an unprecedented growth in the volume of data. A growing portion of the data is generated in real time by IoT devices, websites, business […]
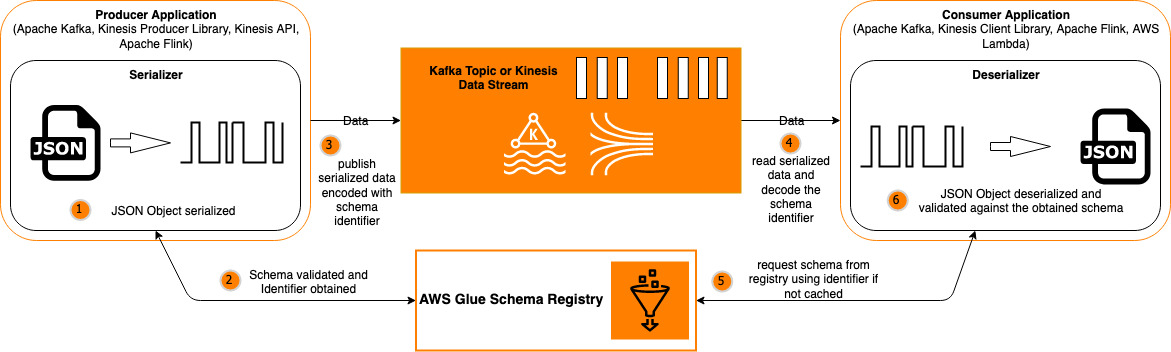
Evolve JSON Schemas in Amazon MSK and Amazon Kinesis Data Streams with the AWS Glue Schema Registry
Data is being produced, streamed, and consumed at an immense rate, and that rate is projected to grow exponentially in the future. In particular, JSON is the most widely used data format across streaming technologies and workloads. As applications, websites, and machines increasingly adopt data streaming technologies such as Apache Kafka and Amazon Kinesis Data […]

Handle fast-changing reference data in an AWS Glue streaming ETL job
Streaming ETL jobs in AWS Glue can consume data from streaming sources such as Amazon Kinesis and Apache Kafka, clean and transform those data streams in-flight, as well as continuously load the results into Amazon Simple Storage Service (Amazon S3) data lakes, data warehouses, or other data stores. The always-on nature of streaming jobs poses […]

Gain insights into your Amazon Kinesis Data Firehose delivery stream using Amazon CloudWatch
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. The volume of data being generated globally is growing at an ever-increasing pace. Data is generated to support an increasing number of use cases, such as IoT, advertisement, gaming, security monitoring, machine […]
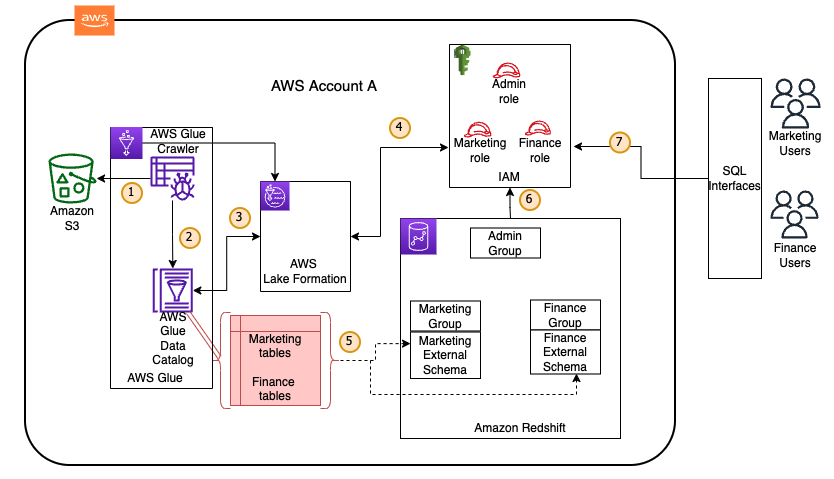
Centralize governance for your data lake using AWS Lake Formation while enabling a modern data architecture with Amazon Redshift Spectrum
Many customers are modernizing their data architecture using Amazon Redshift to enable access to all their data from a central data location. They are looking for a simpler, scalable, and centralized way to define and enforce access policies on their data lakes on Amazon Simple Storage Service (Amazon S3). They want access policies to allow […]

Securely share your data across AWS accounts using AWS Lake Formation
Data lakes have become very popular with organizations that want a centralized repository that allows you to store all your structured data and unstructured data at any scale. Because data is stored as is, there is no need to convert it to a predefined schema in advance. When you have new business use cases, you […]

Backtest trading strategies with Amazon Kinesis Data Streams long-term retention and Amazon SageMaker
July 2023: This post was reviewed for accuracy. Real-time insight is critical when it comes to building trading strategies. Any delay in data insight can cost lot of money to the traders. Often, you need to look at historical market trends to predict future trading pattern and make the right bid. More the historical data […]

Build event-driven data quality pipelines with AWS Glue DataBrew
Businesses collect more and more data every day to drive processes like decision-making, reporting, and machine learning (ML). Before cleaning and transforming your data, you need to determine whether it’s fit for use. Incorrect, missing, or malformed data can have large impacts on downstream analytics and ML processes. Performing data quality checks helps identify issues […]
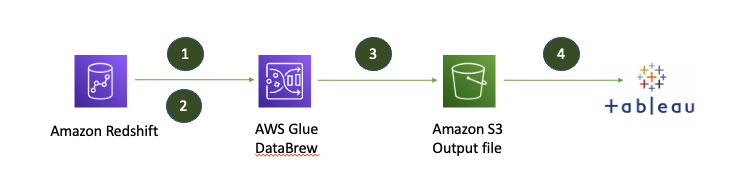
Transform data and create dashboards using AWS Glue DataBrew and Tableau
Before you can create visuals and dashboards that convey useful information, you need to transform and prepare the underlying data. With AWS Glue DataBrew, you can now easily transform and prepare datasets from Amazon Simple Storage Service (Amazon S3), an Amazon Redshift data warehouse, Amazon Aurora, and other Amazon Relational Database Service (Amazon RDS) databases […]

Define error handling for Amazon Redshift Spectrum data
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift Spectrum allows you to query open format data directly from the Amazon Simple Storage Service (Amazon S3) data lake without having to load the data into Amazon Redshift tables. With Redshift Spectrum, you can query open file formats such as […]