AWS Big Data Blog

Introducing hybrid access mode for AWS Glue Data Catalog to secure access using AWS Lake Formation and IAM and Amazon S3 policies
To ease the transition of data lake permissions from an IAM and S3 model to Lake Formation, we’re introducing a hybrid access mode for AWS Glue Data Catalog. This feature lets you secure and access the cataloged data using both Lake Formation permissions and IAM and S3 permissions. Hybrid access mode allows data administrators to onboard Lake Formation permissions selectively and incrementally, focusing on one data lake use case at a time. For example, say you have an existing extract, transform and load (ETL) data pipeline that uses the IAM and S3 policies to manage data access. Now you want to allow your data analysts to explore or query the same data using Amazon Athena. You can grant access to the data analysts using Lake Formation permissions, to include fine-grained controls as needed, without changing access for your ETL data pipelines.

Using Experian identity resolution with AWS Clean Rooms to achieve higher audience activation match rates
This is a guest post co-written with Tyler Middleton, Experian Senior Partner Marketing Manager, and Jay Rakhe, Experian Group Product Manager. As the data privacy landscape continues to evolve, companies are increasingly seeking ways to collect and manage data while protecting privacy and intellectual property. First party data is more important than ever for companies […]

Manage your workloads better using Amazon Redshift Workload Management
Amazon Redshift workload management (WLM) helps you maximize query throughput and get consistent performance for the most demanding analytics workloads by optimally using the resources of your existing data warehouse. This post provides examples of analytics workloads for an enterprise, and shares common challenges and ways to mitigate those challenges using WLM. We guide you through common WLM patterns and how they can be associated with your data warehouse configurations. We also show how to assign user roles to WLM queues and how to use WLM query insights to optimize configuration.
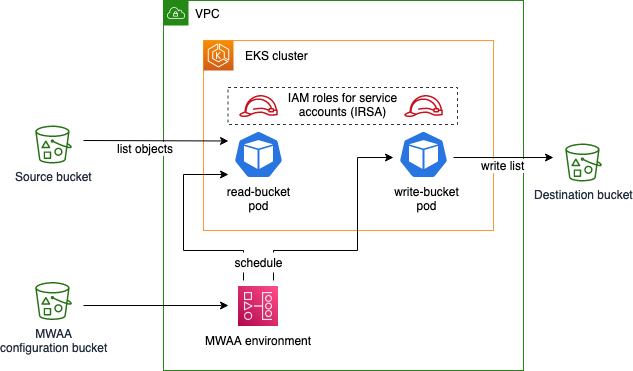
Set up fine-grained permissions for your data pipeline using MWAA and EKS
This blog post shows how to improve security in a data pipeline architecture based on Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Amazon Elastic Kubernetes Service (Amazon EKS) by setting up fine-grained permissions, using HashiCorp Terraform for infrastructure as code.

Use the new SQL commands MERGE and QUALIFY to implement and validate change data capture in Amazon Redshift
Amazon Redshift has added many features to enhance analytical processing like ROLLUP, CUBE and GROUPING SETS, which were demonstrated in the post Simplify Online Analytical Processing (OLAP) queries in Amazon Redshift using new SQL constructs such as ROLLUP, CUBE, and GROUPING SETS. Amazon Redshift has recently added many SQL commands and expressions. In this post, we talk about two new SQL features, the MERGE command and QUALIFY clause, which simplify data ingestion and data filtering.

Stitch Fix seamless migration: Transitioning from self-managed Kafka to Amazon MSK
Stitch Fix is a personalized clothing styling service for men, women, and kids. In this post, we will describe how and why we decided to migrate from self-managed Kafka to Amazon Managed Streaming for Apache Kafka (Amazon MSK).

Accelerate Amazon Redshift secure data use with Satori – Part 1
This post is co-written by Lisa Levy, Content Specialist at Satori. Data democratization enables users to discover and gain access to data faster, improving informed data-driven decisions and using data to generate business impact. It also increases collaboration across teams and organizations, breaking down data silos and enabling cross-functional teams to work together more effectively. […]

Explore visualizations with AWS Glue interactive sessions
AWS Glue interactive sessions offer a powerful way to iteratively explore datasets and fine-tune transformations using Jupyter-compatible notebooks. Interactive sessions enable you to work with a choice of popular integrated development environments (IDEs) in your local environment or with AWS Glue or Amazon SageMaker Studio notebooks on the AWS Management Console, all while seamlessly harnessing […]

Introducing enhanced support for tagging, cross-account access, and network security in AWS Glue interactive sessions
AWS Glue interactive sessions allow you to run interactive AWS Glue workloads on demand, which enables rapid development by issuing blocks of code on a cluster and getting prompt results. This technology is enabled by the use of notebook IDEs, such as the AWS Glue Studio notebook, Amazon SageMaker Studio, or your own Jupyter notebooks. […]

Externalize Amazon MSK Connect configurations with Terraform
Managing configurations for Amazon MSK Connect, a feature of Amazon Managed Streaming for Apache Kafka (Amazon MSK), can become challenging, especially as the number of topics and configurations grows. In this post, we address this complexity by using Terraform to optimize the configuration of the Kafka topic to Amazon S3 Sink connector. By adopting this […]