AWS Compute Blog
Implementing Dynamic ETL Pipelines Using AWS Step Functions
This post contributed by:
Wangechi Dole, AWS Solutions Architect
Milan Krasnansky, ING, Digital Solutions Developer, SGK
Rian Mookencherry, Director – Product Innovation, SGK
Data processing and transformation is a common use case you see in our customer case studies and success stories. Often, customers deal with complex data from a variety of sources that needs to be transformed and customized through a series of steps to make it useful to different systems and stakeholders. This can be difficult due to the ever-increasing volume, velocity, and variety of data. Today, data management challenges cannot be solved with traditional databases.
Workflow automation helps you build solutions that are repeatable, scalable, and reliable. You can use AWS Step Functions for this. A great example is how SGK used Step Functions to automate the ETL processes for their client. With Step Functions, SGK has been able to automate changes within the data management system, substantially reducing the time required for data processing.
In this post, SGK shares the details of how they used Step Functions to build a robust data processing system based on highly configurable business transformation rules for ETL processes.
SGK: Building dynamic ETL pipelines
SGK is a subsidiary of Matthews International Corporation, a diversified organization focusing on brand solutions and industrial technologies. SGK’s Global Content Creation Studio network creates compelling content and solutions that connect brands and products to consumers through multiple assets including photography, video, and copywriting.
We were recently contracted to build a sophisticated and scalable data management system for one of our clients. We chose to build the solution on AWS to leverage advanced, managed services that help to improve the speed and agility of development.
The data management system served two main functions:
- Ingesting a large amount of complex data to facilitate both reporting and product funding decisions for the client’s global marketing and supply chain organizations.
- Processing the data through normalization and applying complex algorithms and data transformations. The system goal was to provide information in the relevant context—such as strategic marketing, supply chain, product planning, etc. —to the end consumer through automated data feeds or updates to existing ETL systems.
We were faced with several challenges:
- Output data that needed to be refreshed at least twice a day to provide fresh datasets to both local and global markets. That constant data refresh posed several challenges, especially around data management and replication across multiple databases.
- The complexity of reporting business rules that needed to be updated on a constant basis.
- Data that could not be processed as contiguous blocks of typical time-series data. The measurement of the data was done across seasons (that is, combination of dates), which often resulted with up to three overlapping seasons at any given time.
- Input data that came from 10+ different data sources. Each data source ranged from 1–20K rows with as many as 85 columns per input source.
These challenges meant that our small Dev team heavily invested time in frequent configuration changes to the system and data integrity verification to make sure that everything was operating properly. Maintaining this system proved to be a daunting task and that’s when we turned to Step Functions—along with other AWS services—to automate our ETL processes.
Solution overview
Our solution included the following AWS services:
- AWS Step Functions: Before Step Functions was available, we were using multiple Lambda functions for this use case and running into memory limit issues. With Step Functions, we can execute steps in parallel simultaneously, in a cost-efficient manner, without running into memory limitations.
- AWS Lambda: The Step Functions state machine uses Lambda functions to implement the Task states. Our Lambda functions are implemented in Java 8.
- Amazon DynamoDB provides us with an easy and flexible way to manage business rules. We specify our rules as Keys. These are key-value pairs stored in a DynamoDB table.
- Amazon RDS: Our ETL pipelines consume source data from our RDS MySQL database.
- Amazon Redshift: We use Amazon Redshift for reporting purposes because it integrates with our BI tools. Currently we are using Tableau for reporting which integrates well with Amazon Redshift.
- Amazon S3: We store our raw input files and intermediate results in S3 buckets.
- Amazon CloudWatch Events: Our users expect results at a specific time. We use CloudWatch Events to trigger Step Functions on an automated schedule.
Solution architecture
This solution uses a declarative approach to defining business transformation rules that are applied by the underlying Step Functions state machine as data moves from RDS to Amazon Redshift. An S3 bucket is used to store intermediate results. A CloudWatch Event rule triggers the Step Functions state machine on a schedule. The following diagram illustrates our architecture:

Here are more details for the above diagram:
- A rule in CloudWatch Events triggers the state machine execution on an automated schedule.
- The state machine invokes the first Lambda function.
- The Lambda function deletes all existing records in Amazon Redshift. Depending on the dataset, the Lambda function can create a new table in Amazon Redshift to hold the data.
- The same Lambda function then retrieves Keys from a DynamoDB table. Keys represent specific marketing campaigns or seasons and map to specific records in RDS.
- The state machine executes the second Lambda function using the Keys from DynamoDB.
- The second Lambda function retrieves the referenced dataset from RDS. The records retrieved represent the entire dataset needed for a specific marketing campaign.
- The second Lambda function executes in parallel for each Key retrieved from DynamoDB and stores the output in CSV format temporarily in S3.
- Finally, the Lambda function uploads the data into Amazon Redshift.
To understand the above data processing workflow, take a closer look at the Step Functions state machine for this example.
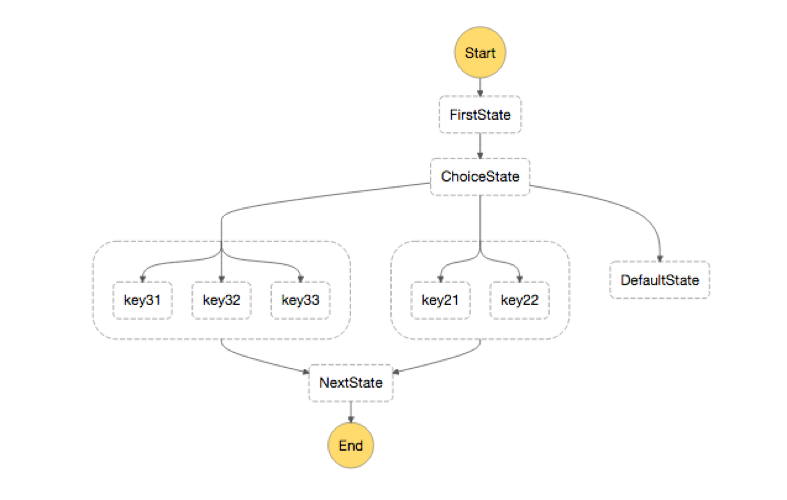
We walk you through the state machine in more detail in the following sections.
Walkthrough
To get started, you need to:
- Create a schedule in CloudWatch Events
- Specify conditions for RDS data extracts
- Create Amazon Redshift input files
- Load data into Amazon Redshift
Step 1: Create a schedule in CloudWatch Events
Create rules in CloudWatch Events to trigger the Step Functions state machine on an automated schedule. The following is an example cron expression to automate your schedule:

In this example, the cron expression invokes the Step Functions state machine at 3:00am and 2:00pm (UTC) every day.
Step 2: Specify conditions for RDS data extracts
We use DynamoDB to store Keys that determine which rows of data to extract from our RDS MySQL database. An example Key is MCS2017, which stands for, Marketing Campaign Spring 2017. Each campaign has a specific start and end date and the corresponding dataset is stored in RDS MySQL. A record in RDS contains about 600 columns, and each Key can represent up to 20K records.
A given day can have multiple campaigns with different start and end dates running simultaneously. In the following example DynamoDB item, three campaigns are specified for the given date.

The state machine example shown above uses Keys 31, 32, and 33 in the first ChoiceState and Keys 21 and 22 in the second ChoiceState. These keys represent marketing campaigns for a given day. For example, on Monday, there are only two campaigns requested. The ChoiceState with Keys 21 and 22 is executed. If three campaigns are requested on Tuesday, for example, then ChoiceState with Keys 31, 32, and 33 is executed. MCS2017 can be represented by Key 21 and Key 33 on Monday and Tuesday, respectively. This approach gives us the flexibility to add or remove campaigns dynamically.
Step 3: Create Amazon Redshift input files
When the state machine begins execution, the first Lambda function is invoked as the resource for FirstState, represented in the Step Functions state machine as follows:
"Comment": ” AWS Amazon States Language.",
"StartAt": "FirstState",
"States": {
"FirstState": {
"Type": "Task",
"Resource": "arn:aws:lambda:xx-xxxx-x:XXXXXXXXXXXX:function:Start",
"Next": "ChoiceState"
} As described in the solution architecture, the purpose of this Lambda function is to delete existing data in Amazon Redshift and retrieve keys from DynamoDB. In our use case, we found that deleting existing records was more efficient and less time-consuming than finding the delta and updating existing records. On average, an Amazon Redshift table can contain about 36 million cells, which translates to roughly 65K records. The following is the code snippet for the first Lambda function in Java 8:
public class LambdaFunctionHandler implements RequestHandler<Map<String,Object>,Map<String,String>> {
Map<String,String> keys= new HashMap<>();
public Map<String, String> handleRequest(Map<String, Object> input, Context context){
Properties config = getConfig();
// 1. Cleaning Redshift Database
new RedshiftDataService(config).cleaningTable();
// 2. Reading data from Dynamodb
List<String> keyList = new DynamoDBDataService(config).getCurrentKeys();
for(int i = 0; i < keyList.size(); i++) {
keys.put(”key" + (i+1), keyList.get(i));
}
keys.put(”key" + T,String.valueOf(keyList.size()));
// 3. Returning the key values and the key count from the “for” loop
return (keys);
}The following JSON represents ChoiceState.
"ChoiceState": {
"Type" : "Choice",
"Choices": [
{
"Variable": "$.keyT",
"StringEquals": "3",
"Next": "CurrentThreeKeys"
},
{
"Variable": "$.keyT",
"StringEquals": "2",
"Next": "CurrentTwooKeys"
}
],
"Default": "DefaultState"
}
The variable $.keyT represents the number of keys retrieved from DynamoDB. This variable determines which of the parallel branches should be executed. At the time of publication, Step Functions does not support dynamic parallel state. Therefore, choices under ChoiceState are manually created and assigned hardcoded StringEquals values. These values represent the number of parallel executions for the second Lambda function.
For example, if $.keyT equals 3, the second Lambda function is executed three times in parallel with keys, $key1, $key2 and $key3 retrieved from DynamoDB. Similarly, if $.keyT equals two, the second Lambda function is executed twice in parallel. The following JSON represents this parallel execution:
"CurrentThreeKeys": {
"Type": "Parallel",
"Next": "NextState",
"Branches": [
{
"StartAt": “key31",
"States": {
“key31": {
"Type": "Task",
"InputPath": "$.key1",
"Resource": "arn:aws:lambda:xx-xxxx-x:XXXXXXXXXXXX:function:Execution",
"End": true
}
}
},
{
"StartAt": “key32",
"States": {
“key32": {
"Type": "Task",
"InputPath": "$.key2",
"Resource": "arn:aws:lambda:xx-xxxx-x:XXXXXXXXXXXX:function:Execution",
"End": true
}
}
},
{
"StartAt": “key33",
"States": {
“key33": {
"Type": "Task",
"InputPath": "$.key3",
"Resource": "arn:aws:lambda:xx-xxxx-x:XXXXXXXXXXXX:function:Execution",
"End": true
}
}
}
]
} Step 4: Load data into Amazon Redshift
The second Lambda function in the state machine extracts records from RDS associated with keys retrieved for DynamoDB. It processes the data then loads into an Amazon Redshift table. The following is code snippet for the second Lambda function in Java 8.
public class LambdaFunctionHandler implements RequestHandler<String, String> {
public static String key = null;
public String handleRequest(String input, Context context) {
key=input;
//1. Getting basic configurations for the next classes + s3 client Properties
config = getConfig();
AmazonS3 s3 = AmazonS3ClientBuilder.defaultClient();
// 2. Export query results from RDS into S3 bucket
new RdsDataService(config).exportDataToS3(s3,key);
// 3. Import query results from S3 bucket into Redshift
new RedshiftDataService(config).importDataFromS3(s3,key);
System.out.println(input);
return "SUCCESS";
}
}After the data is loaded into Amazon Redshift, end users can visualize it using their preferred business intelligence tools.
Lessons learned
- At the time of publication, the 1.5–GB memory hard limit for Lambda functions was inadequate for processing our complex workload. Step Functions gave us the flexibility to chunk our large datasets and process them in parallel, saving on costs and time.
- In our previous implementation, we assigned each key a dedicated Lambda function along with CloudWatch rules for schedule automation. This approach proved to be inefficient and quickly became an operational burden. Previously, we processed each key sequentially, with each key adding about five minutes to the overall processing time. For example, processing three keys meant that the total processing time was three times longer. With Step Functions, the entire state machine executes in about five minutes.
- Using DynamoDB with Step Functions gave us the flexibility to manage keys efficiently. In our previous implementations, keys were hardcoded in Lambda functions, which became difficult to manage due to frequent updates. DynamoDB is a great way to store dynamic data that changes frequently, and it works perfectly with our serverless architectures.
Conclusion
With Step Functions, we were able to fully automate the frequent configuration updates to our dataset resulting in significant cost savings, reduced risk to data errors due to system downtime, and more time for us to focus on new product development rather than support related issues. We hope that you have found the information useful and that it can serve as a jump-start to building your own ETL processes on AWS with managed AWS services.
For more information about how Step Functions makes it easy to coordinate the components of distributed applications and microservices in any workflow, see the use case examples and then build your first state machine in under five minutes in the Step Functions console.
If you have questions or suggestions, please comment below.