AWS Database Blog
Creating a proof of concept using Amazon Aurora
As customers move to the cloud, they’re looking for the best tools to run their applications. When considering relational databases, Amazon Aurora is a frequent choice. This is no surprise, given that Amazon Aurora is MySQL and PostgreSQL wire-compatible and that it can provide greater throughput than either. Aurora provides up to five times the throughput of standard MySQL databases and up to three times the throughput of standard PostgreSQL databases.
As customers investigate Aurora, they commonly build proofs of concept (POCs) to see if Amazon Aurora is a good fit with their applications. Following, we list some things to consider as you create a POC.
Is Amazon Aurora the right tool?
When you think about data and databases, one of the key factors is the velocity of the data. At one end of the spectrum, data moves very fast with perhaps thousands of connections and hundreds of thousands of simultaneous queries both reading and writing to a database. At this velocity, the queries usually affect a relatively small number of rows at a time. Additionally, when data is accessed at this velocity, it’s common for queries to access multiple columns at once as in a record. This type of access makes it more practical to store and retrieve data in rows. A common example of this type of workload is an online transaction processing (OLTP) system.
At the other end of this spectrum, as the velocity of data slows down there might only be a handful of connections and a few queries executing in parallel. However, here the range of rows is often many times greater, including full-table scans. At this velocity, the queries are usually focused on a smaller subset of columns but perhaps all of the rows in a table. This approach makes it more practical to store data in a columnar format. Additionally, write patterns are much different at slower velocities. Most data is bulk-loaded at regular intervals rather than the rapid individual and nearly constant writes at the higher velocities. A common example of this type of workload is a data warehousing or online analytical processing (OLAP) system.
Amazon Aurora was primarily designed to handle high-velocity data. Depending on the workload, with a single r4.16xlarge Aurora cluster you can exceed 600,000 SELECT statements per second. With such a cluster, you can also exceed 200,000 data manipulation language (DML) statements per second (such as INSERT, UPDATE, and DELETE). Aurora is a row-store database and is ideally suited for high-volume, high-throughput, and highly parallelized OLTP workloads.
Another scenario where Aurora excels is when running hybrid transaction/analytical processing (HTAP) workloads. Aurora is capable of supporting up to 15 replicas (as described in the Aurora documentation). Each of these, on average, runs within 10–20 milliseconds of the writer. This functionality enables you to query OLTP data in real time with minimal impact on OLTP operations. Additionally, with the release of the Aurora parallel query feature, you can now use potentially thousands of storage nodes in your Aurora cluster to process, refine, and aggregate data before sending it to the compute node.
For very low-velocity data, the workloads benefit from a columnar storage format and other features more suitable to OLAP workloads. For these cases, a number of tools exist in the AWS portfolio. These include Amazon Redshift, Amazon EMR, and Amazon Athena. Many workloads benefit from a combination of Aurora with one or more of these tools. You can also move data among these tools by using AWS Glue, the AWS Database Migration Service, imports or exports to Amazon S3, or many other popular extract, transform, load (ETL) tools.
How do I measure success?
When evaluating Amazon Aurora as part of a POC, it’s important to identify ahead of time how to measure success.
Compatibility
Although it might seem obvious, it’s important to ensure that all of the existing functionality of an existing application is compatible with Aurora. Aurora is wire-compatible with MySQL 5.6 and MySQL 5.7, and also with PostgreSQL 9.6 and PostgreSQL 10.4. Nearly any application that is compatible with those engines is also compatible with Amazon Aurora. However, it’s still critical to validate compatibility for each application.
Prerequisites
After basic functional compatibility has been established, it’s important to replicate the actual conditions under which the application runs. For example, it’s not likely that the application being tested generally runs from a personal user’s laptop across a VPN connection into AWS. More likely, the application runs on Amazon EC2 instances in the same AWS Region and likely the same VPC. This means that it’s important that the POC also run from EC2 instances in the same AWS Region and VPC. It might also be the case that the actual production application runs on multiple EC2 instances spanning multiple Availability Zones. If that’s the case, then the POC architecture should reflect that also.
Workload
After the environment is configured appropriately, the next thing to consider is the workload itself. Although you can’t always run an exact replica of the workload that is anticipated in production, the workload used in the POC should at least mirror significant aspects of what you anticipate in production. For example, suppose that the actual workload is an HTAP workload. In this case, running an OLTP is insufficient because it doesn’t take into account the analytical queries expected at launch.
Measure success
Now that the environment and the actual workload reflect production, the next step is to measure how well the application performs. The role of Aurora in a given architecture is to store, modify, and retrieve data. Thus, the primary metrics by which success should be measured should reflect these abilities. Two questions need to be answered:
- How many queries per second is Aurora processing?
- Reads per second
- Writes per second
- How long does it take, on average, for Aurora to process a given query?
- Read latency
- Write latency
Perhaps the easiest way to determine this is to look at the Amazon RDS console for a given Aurora cluster, as illustrated following.
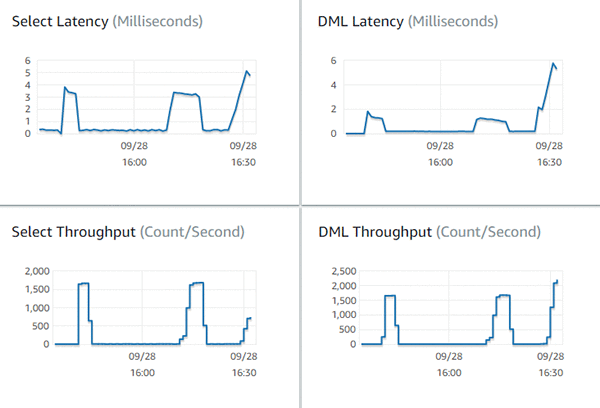
These specific metrics break the queries down into reads (SELECT) and writes (DML statements). They answer the questions of “How many queries per second?” and “How long does it take to execute a query?” For certain workloads, you might find both the Commit Throughput and Commit Latency metrics valuable to assess transaction throughput for the system.
The specific values required for each of these metrics preceding vary from application to application, so it’s important to establish baseline values for these metrics. These baseline numbers might already exist based on where the application is hosted today. If no baseline exists, then running a workload representative of what is anticipated in production should provide a good starting point. For example, you might run a workload with the same number of users.
Sizing
To ensure that an application performs at its peak without overprovisioning resources, it’s critical to determine the appropriate size of the instances in the Aurora cluster. A good starting point is to select an instance size that has similar CPU and memory capacity to what the application runs on in production today. After collecting throughput and latency numbers for the workload at that instance size, we recommend that you scale the instance up to the next greater size. At this size, see if the throughput and latency numbers improve. In addition, scale down to see if the latency and throughput numbers remain the same. The goal, of course, is to get the highest throughput with the lowest latency on the smallest instance possible.
Parameters
Many customers in their on-premises environments modify the default MySQL or PostgreSQL parameters to improve performance. Although Amazon Aurora is wire-compatible with MySQL and PostgreSQL, a number of parameters no longer apply due to the unique Aurora storage architecture. Additionally, other parameters might have a different impact than what’s expected with standard MySQL or PostgreSQL. This being the case, we recommend that you start with the default settings. Then if a specific issue is identified that requires tweaking, modify the parameters at that time.
Conclusion
At this point in the POC process, we can determine whether Aurora is the right tool based on the anticipated workload of OLTP or HTAP. We have defined the fundamentals regarding proper POC design and also, most importantly, how to define success from a performance perspective.
If you’re interested in learning more about Aurora, you can read the latest Aurora blog posts on the AWS Database Blog. If you want to provide feedback, ask questions, or request enhancements, email us.
About the Author
 Steve Abraham is a principal solutions architect for Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.
Steve Abraham is a principal solutions architect for Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.