AWS Database Blog
How Apollo Tyres built their tyre genealogy solution using Amazon Neptune and Amazon Bedrock
This is a joint post co-authored with Shailender Gupta, Global Head of Data Engineering, Reporting and Analytics at Apollo Tyres
Apollo Tyres, headquartered in Gurgaon, India, is a prominent global tyre manufacturer with production facilities in India and Europe. The company has a widespread presence, selling tyres to consumers and industrial customers across over 100 countries. Apollo Tyres pride themselves on delivering high-quality tyres that meet the highest standards of safety and performance. However, in the manufacturing world, even the slightest issue can have far-reaching consequences. That’s why they have always been committed to staying ahead of the curve when it comes to quality control and root cause analysis. One of the biggest challenges Apollo Tyres faced was tracking the genealogy of their tyres—a process that involves tracing the intricate web of components, processes, and systems involved in the manufacturing of a specific tyre. Tyre genealogy is a system used to monitor and track production process parameters for each tyre throughout the production process. This information is crucial for identifying and resolving issues related to warranty claims, product defects, and quality assurance. Traditional data storage solutions, such as relational databases and data warehouses, struggled to keep up with the recursive and resource-intensive nature of genealogy tracking. That’s when they turned to the power of graph databases and generative artificial intelligence (AI) solutions offered by Amazon Web Services (AWS)
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it straightforward to build and run applications that work with highly connected data sets. The core of Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with milliseconds latency. You can build knowledge graphs, fraud graphs, identity graphs, recommendation engines, master data management, and network security applications using Neptune.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
In this post, we show you how Apollo Tyres enhanced their tyre genealogy tracking and quality control processes using Amazon Neptune and Amazon Bedrock. By leveraging Neptune’s graph database capabilities and Amazon Bedrock’s generative AI models, Apollo Tyres was able to create a powerful system for tracing the complex relationships between tyre components, manufacturing processes, and quality control checkpoints.
Challenge: Tracing the lineage of a tyre
Tyre genealogy is a complex concept that involves mapping the entire lineage of a tyre, from the raw materials used to the various manufacturing processes and systems involved. It’s like tracing the branches of a family tree, but with countless interconnected nodes and relationships. Imagine trying to find the root cause of a warranty claim or a product issue. You might start from the finished tyre and work your way backward, traversing through the intricate web of components and processes. Or you might begin with a specific component or process and trace its impact on the final product. Either way, the process is recursive and resource-intensive, making it a challenge for traditional data storage solutions. The following image shows multiple interconnected nodes arranged in a hierarchical structure, representing the complex relationships and connections found in genealogy tracing.
 Figure 1: Tracing Genealogy is a complex process with hierarchy of nodes connected to each other
Figure 1: Tracing Genealogy is a complex process with hierarchy of nodes connected to each other
Problem with traditional solutions using relational databases or data warehouses
To retrieve genealogical data in a SQL-based solution, you need to use a recursive common table expression (CTE), which iterates through each row and stores the result in a temporary table. Recursive CTEs are computationally expensive and can become slow when dealing with multi-level queries.
In a data warehouse that uses columnar storage, the performance of recursive CTEs is even worse because these systems are not designed for row-by-row operations. Instead, they are optimized for bulk queries on columns.
“In our initial test to build the solution using SQL based systems, we faced performance challenges when users tried to query Genealogy beyond 2 levels or to query multiple Genealogies at the same time. Even with a system as large as having 24 CPUs and 256 GB RAM, it took more than 8 minutes to get results at level 3 of genealogy.”
– Shailender Gupta, Global Head of Data Engineering, Reporting and Analytics at Apollo Tyres
Solution: Graph database powered by Amazon Neptune
A graph database is a type of database that stores data in a way that highlights the connections and relationships between different data entities. Instead of using the traditional table-based structure found in relational databases, graph databases represent data as a network of nodes (which store the data entities) and edges (which represent the relationships between the nodes). This approach is based on the mathematical graph theory. In a graph database, each node can have multiple types of relationships with other nodes, and these relationships can be one-to-many or many-to-many. Nodes and edges can also have properties or attributes that provide additional information about them.
Neptune, a graph database for data storage and querying, is perfectly suited for handling complex, interconnected data structures like tyre genealogy. Unlike traditional databases, Neptune database is designed to store and navigate relationships between data points, making it ideal for tracing the intricate web of connections in manufacturing processes.
The advantages of using Neptune database for tyre genealogy tracking are the following:
- Indexed structure for connecting nodes: Neptune database is inherently indexed, allowing for efficient traversal of connected nodes, even in large and complex data structures.
- Fast traversal of connected nodes: With Neptune database, you can quickly navigate through the relationships between nodes, making it easier to trace the genealogy of a tyre. It can quickly find the connected nodes to any N level of recursion (depth).
- Handling many-to-many relationships: Tyre manufacturing involves numerous components and processes, each with its own set of relationships. Neptune database excel at handling these complex, many-to-many relationships.
- Ability to add properties to nodes and edges: Neptune database allows you to store additional metadata and properties on both nodes and edges providing a richer and more comprehensive view of your data.
The following architecture diagram shows the solution architecture of tyre genealogy solution.
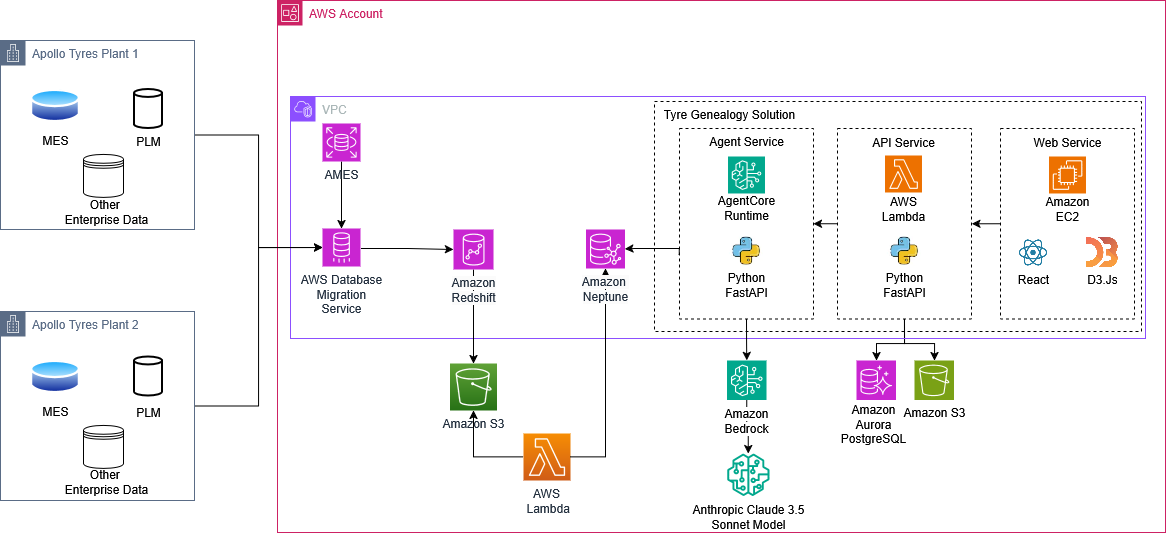
Figure 2. The solution architecture.
The workflow includes the following steps:
- AWS Database Migration Service (AWS DMS) is used to send data from Apollo Tyre’s on-premises and cloud Manufacturing Execution System (MES) to Amazon Redshift. The data in Amazon Redshift is used for various analytical processing and visualization using Business Intelligence (BI) dashboards.
- Data from Amazon Redshift is exported to Amazon Simple Storage Service (Amazon S3), which is then accessed by AWS Lambda for further processing.
- Custom Lambda functions written in Python are used to load data from Amazon S3 to Neptune. The Neptune Bulk Loader allows you to import data from external files directly into a Neptune database cluster. The Neptune Loader command provides several advantages. It operates at a faster pace, introduces less overhead, and is optimized for handling large datasets efficiently.
- The tyre genealogy application hosted, on AWS Lambda and Amazon Bedrock’s AgentCore Runtime, queries the data in Neptune using openCypher queries and returns the response to the application.
- The application is written using Strands Agents Python SDK, and integrated with the Amazon Bedrock API. To connect to the database, the LangChain Neptune wrapper was used, and invoked with openCypher queries.
- The generated queries are run against Neptune, and the response is relayed back to the tyre genealogy solution. The following code snippet shows an example of executing an openCypher query for Neptune graph database.
(In the production app, this blocking call is offloaded to a background thread usingasyncio.to_threadto keep the event loop responsive) - The solution user interface (UI) is built using React, Python’s FastAPI, and JS and shows the results of the user query and displays network charts.
Solution approach
Apollo Tyres embarked on a journey to leverage graph database technology for managing and analyzing their tyre genealogy data. The process involved the following key steps:
1. Model graph data
The first step in Apollo Tyres’ journey was to model the tyre genealogy data as a graph. They worked closely with domain experts and data engineers to identify the key entities, relationships, and properties that needed to be represented in the graph database.
2. Proof of concept using AWS DMS, Neptune, and source RDBMS
To validate the approach, they conducted a proof of concept (PoC) using AWS DMS to migrate data from their source relational database management system (RDBMS) to Neptune Database. This allowed them to test the performance and scalability of our graph database solution.
“AWS DMS is already a very stable and trusted data replication solution adopted at Apollo Tyres. The fact that it seamlessly integrates with Neptune Graph DB was a big motivator for us to do a quick PoC. DMS provides a GUI interface to map fields against Vertex and Edges of Neptune DB, which was the quickest way for us to start with transfer of sample data from our production systems to Neptune DB. Within few hours we were ready to run the PoC.” said Shailender Gupta
3. Full load of data
Encouraged by the success of the PoC, they proceeded with the full load of the tyre genealogy data into Neptune. This involved exporting the data to Amazon S3 and then performing a bulk import using the Neptune API. In total, over 270 million edges and 76 million vertices were loaded into the graph database.
4. Learn graph query language for querying graph data
With the data in place, the next challenge was to learn how to query the graph database effectively. Neptune supports multiple query languages that can work inter-operably over the same data. One of the supported languages is Gremlin, which is defined by the Apache TinkerPop project for creating and querying property graphs. In Gremlin, a query is structured as a traversal consisting of discrete steps, where each step follows an edge to a node. Another language supported by Neptune is openCypher, a declarative query language for property graphs originally developed by Neo4j and later open-sourced under the Apache 2 license. The openCypher syntax is documented in the openCypher specification. Additionally, Neptune supports SPARQL, a declarative language based on graph pattern-matching, for querying RDF data.
Apollo Tyres explored two query languages, Gremlin and openCypher, and ultimately decided to go with openCypher. To accelerate the learning curve, they used the power of Amazon Bedrock and the Anthropic Claude3 Sonnet large language model (LLM) to generate openCypher queries based on natural language queries.
5. Develop a query UI for users
To make the tyre genealogy solution accessible to a wider audience, Apollo Tyres developed a user-friendly user interface (UI). This UI allowed users to query the graph database using natural language through the integration of Amazon Bedrock and Anthropic Claude LLM. The results were then displayed in a visually appealing and interactive React page, complete with a network chart for quick visualization of the genealogy data. The following screenshot shows the custom UI built by Apollo Tyres based on the internal users’ requirement for quick visualization of genealogy data.
 Figure 3: Custom UI build by Apollo Tyres
Figure 3: Custom UI build by Apollo Tyres
The Detailed Solution: A Multi-step GraphQL-Generator
Following the rollout of their solution to users, Apollo Tyres started analysing user feedback to identify areas for growth. They decided to build upon their initial success by deepening the solution’s logic for two specific types of queries that went beyond the original scope.
- Complicated, multi-hop queries (such as, “From the child and parent nodes of xxxxxxxxxx, find the count of unique child and parent nodes that use the same equipment; limit 20.”).
- Identifying unlabelled entities. For instance, a simply stated barcode like “xxxxxxxxxx” would not reliably be identified by the agent; the word “barcode” had to precede it.
They also wanted users to conduct follow-up conversations, start new conversations, and focus on data, all without cluttering the UI with multiple chats. In order to accomplish all of this, Apollo Tyres worked with Invisibl Cloud, an Advanced Tier Services AWS Partner. Invisibl Cloud created a solution that followed the subsequent multi-step process for each message received from the user.
Step 1: Intent-Classification
Since the idea was not to clutter the UI with multiple chats for a single user, the first step was to determine if the user wanted to start a new chat, continue an existing one, or have non-data interactions. Responses to non-data queries were immediate, while continuation used hints from the history, and new data queries reset the context.
Step 2: Entity-Recognition
In order to solve the problem of subject-matter experts employing terms without explicitly stating their entity type, Invisibl Cloud decided to help the agent by bringing this entity information into the agent’s context. They used named-entity recognition (NER) enhanced with RegEx patterns of some of the most common (and unique) entity types to extract them from the user’s message.
Thus, a message like, “From the child and parent nodes of xxxxxxxxxx, find the count of unique child and parent nodes that use the same equipment; limit 20,” would let the agent know that the user was talking about an entity of type “barcode” with the value “xxxxxxxxxx.”
Step 3: Prompt-Enhancement and Query-Generation
Invisibl Cloud injected extracted entities and the knowledge graph ontology into the user’s message, transforming it into a context-rich prompt. An agent then generated openCypher queries, guided by system prompts that specified syntax constraints, optimizations, and examples, and instructions to avoid complex or unsupported queries.
Step 4: Query-Validation
Next, generated queries underwent validation. Checks included the security of the query; features supported by openCypher but not Neptune; the presence of a reasonable LIMIT clause; syntactic correctness; and semantic accuracy. If validation failed, reasons were appended to the context, and the query was retried, with a cap on the number of retries. With this validate-and-retry approach, Invisibl Cloud ensured only safe, syntactically correct, and semantically valid queries proceeded.
Step 5: Query-Execution
This step was simple: execute the generated query against the Neptune database. If a query timed out, the system reduced the LIMIT clause and retried, improving response completeness without risking indefinite waits.
Step 6: Response-Generation
Finally, some few-shot examples were provided to an LLM, along with the data from the response from the DB and instructions about how to respond to the user. With this, Invisibl Cloud ensured Apollo Tyres’s users had a complete, accurate, data-backed answer to their question.
Implementation and Deployment Upgrades
In addition to adding the above steps to make the tyre genealogy solution more robust, Invisibl Cloud upgraded the agent to Claude 3.5 Sonnet and adopted the Strands Agents SDK. The system was split into two services: an API service managing conversation threads via AWS Lambda and an agent service running on Amazon Bedrock’s AgentCore Runtime.
Since threads were implemented in a custom manner, separate from Strands’ existing file- and S3-based session-handling capabilities, this data resided in an Amazon Aurora PostgreSQL database. Finally, whenever graph data was returned by the agent, the graph sat in Amazon S3, so that it could be retrieved and displayed on the UI as needed.
Benefits and results
The tyre genealogy solution has transformed the Apollo Tyres’ operations and quality control processes. This system has brought about significant enhancements across various aspects of their business:
1. Improved query performance and ability to search multiple nodes
Users are now able to search multiple node components and at a deep level of hierarchy within seconds, using only a fraction of resources compared to earlier solution built on relational database.
2. Improved root cause analysis for warranty claims and product issues
With the ability to quickly trace the genealogy of a tyre, the quality control and engineering teams can now identify the root cause of warranty claims and product issues more efficiently. This has led to faster resolution times and improved customer satisfaction.
3.Reduced QA issues and improved productivity
The tyre genealogy solution provides a comprehensive view of the manufacturing process and the relationships between components and systems, which enabled Apollo Tyres to identify and address potential quality assurance issues proactively. This has resulted in improved productivity and reduced waste.
4. Optimized manufacturing processes
The insights gained from the tyre genealogy solution have also enabled Apollo Tyres to optimize their manufacturing processes. By identifying bottlenecks and inefficiencies, they have streamlined the operations and improve overall efficiency.
Challenges and lessons learned
While the journey with Neptune and Amazon Bedrock has been incredibly rewarding, it wasn’t without its challenges. One of the biggest hurdles Apollo Tyres faced was modeling their complex data structure as a graph as it was a new technology adoption for them. It required a deep understanding of the domain and close collaboration between the data engineers and subject matter experts.
Another challenge was learning and adapting to the new query languages and paradigms of graph databases. However, with the help of Amazon Bedrock and Anthropic Claude LLM, they were able to accelerate the learning curve and quickly become proficient in querying their graph data.
During the initial full load of data, Apollo Tyres had to deal with a volume of 270 million edges and 76 million vertices. They explored various strategies for loading this data, including using AWS DMS, custom Python scripts, and ultimately achieved success by exporting the data to Amazon S3 and performing a bulk import using the Neptune API.
Creating a user-friendly interface for querying the graph database posed a significant challenge. While Neptune offers Graph Explorer, which enables users to explore graph data interactively without the need to learn a specialized query language, it didn’t meet the user requirements. Consequently, Apollo Tyres developed a custom solution using React JS, Python’s FastAPI, and D3.JS. This solution uses Amazon Bedrock and Anthropic’s Claude 3.5 Sonnet LLM to allow users to query the database using natural language. The results are then displayed on a React page with a network chart, providing a more intuitive and accessible experience for users.
Next Steps
As next step, Apollo Tyres is planning to use graph analytics to perform deep analytics on the graph data. Graph Analytics is a powerful way to find anomalies, reduce product complexity, and detect quality patterns in the data. Using graph analytics, one can find the following:
- Centrality – which component is the most important in terms of dependence. Failure of this component can impact a large number of dependent components.
- Reduce product complexity –
- Find the products which are designed using overly complicated components.
- Find the components that are similar in features and are replaceable with other components which are less costly to produce, but can give same or better quality.
Neptune Analytics offers solutions for deep analytics on graph data. Apollo Tyres plans to expand the use of graph data to Neptune Analytics to solve these business problems.
Conclusion
Apollo Tyres’ genealogy solution using Amazon Neptune and Amazon Bedrock has been a transformative experience for the company. By adopting graph database technology and using generative AI solutions on AWS, Apollo Tyres has remodeled its approach to tracking the genealogy of its tyres. This solution has yielded significant benefits, including enhanced root cause analysis, reduced quality assurance challenges, and optimized manufacturing processes. The advantages of the tyre genealogy solution have been widespread and impactful for the company.
Apollo Tyres is excited to continue exploring the potential of graph databases and AWS services as they look forward to further advancements in the realm of data management and analytics.
“What we like about AWS is that it offers products based on opensource systems. These systems are simple to integrate with, are widely supported in the industry and avoid locking into proprietary technology. The Neptune database supports Apache open source Apache TinkerPop Gremlin graph traversal language, and openCypher query language for property graphs. This gives us the freedom to port our solution to other environments any day we feel we need a better price performance ratio than what we are getting. Lastly, AWS offer an integrated landscape of services. It is simple to spin a service when you know it can quickly talk to other existing services you are using.” said Shailender Gupta.
To learn more about Amazon Neptune and Amazon Bedrock and getting started, refer to Getting started with Amazon Neptune Database and Getting started with Amazon Bedrock. If you have feedback about this post, submit comments in the Comments section below.
About the Authors

Shailender Gupta is the Global Head of Data Engineering, Reporting and Analytics at Apollo Tyres. With over 25 years of experience in the field of Data Warehousing and Analytics, he has built large scale Analytics solutions for Fortune 500 clients. He is a hands-on tech leader with deep understanding of technologies he works on. He’s an avid reader and likes to travel exploring new places.
 Gautam Kumar is a Solution Architect at AWS. Gautam helps various Enterprise customers to design and architect innovative solutions on AWS and specifically passionate about building secure workloads on AWS. Outside work, he enjoys travelling and spending time with family.
Gautam Kumar is a Solution Architect at AWS. Gautam helps various Enterprise customers to design and architect innovative solutions on AWS and specifically passionate about building secure workloads on AWS. Outside work, he enjoys travelling and spending time with family.