AWS Database Blog
Large object storage strategies for Amazon DynamoDB
Customers across all industries use Amazon DynamoDB as the primary database for their mission critical workloads. DynamoDB is designed to provide consistent performance at any scale. To take advantage of this performance, one of the most important tasks to complete is data modeling. Your success with DynamoDB depends on how well you define and model your access patterns. One of the aspects of data modeling is how to treat large objects within DynamoDB. It’s important to have a defined strategy for how to handle items larger than the maximum size of 400 KB to prevent unexpected behavior and to ensure your solution remains performant as it scales.
In this post, I show you some different options for handling large objects within DynamoDB and the benefits and disadvantages of each approach. I provide some sample code for each option to help you get started with any of these approaches with your own workloads.
In DynamoDB, an item is a set of attributes. Each attribute has a name and a value. Both the attribute name and the value count toward the total item size. For the purposes of this post, large object refers to any item that exceeds the current maximum size for a single item, which is 400 KB. This item could contain long string attributes, a binary object, or any other data type supported by DynamoDB that exceeds the maximum item size.
Solution overview
This post covers multiple approaches that you can use to model large objects within your DynamoDB-backed application. You should have some familiarity with DynamoDB. If you’re just starting out, be sure to review Getting started with Amazon DynamoDB first.
The solutions you’ll explore are:
Option 1: Default behavior
Option 2: Store large objects in Amazon Simple Storage Service (Amazon S3) with a pointer in DynamoDB
Option 3: Split large items into item collections
Option 4: Compress large objects
Deploy the examples
For examples of each solution, you can deploy the AWS Serverless Application Model (SAM) template that accompanies this post. You can use these examples as a reference for your own implementations. These examples are all written in Node.JS, but bindings exist for the techniques used in this post in most popular programming languages.
To deploy the SAM template, clone this GitHub repository and follow the instructions in the repository.
Option 1: Default behavior
The default behavior is to reject items that are over the maximum item size, which can be a perfectly valid design choice. In that situation, you return an error message to the caller indicating the item size is too large and it’s up to the caller to implement the correct behavior, which can be to split the item into multiple parts, send it to a dead letter queue, or return an exception indicating that the item is too large.
In the example repository, you can observe this behavior by running the unencoded-write AWS Lambda function that was deployed by the template. The repository includes a large sample event that exceeds the maximum item size (420 KB—20 KB over the maximum item size). If you invoke the function using this payload, you’ll get a ValidationException error from DynamoDB with a message that the item has exceeded the maximum allowed size, as shown in Figure 1 that follows.
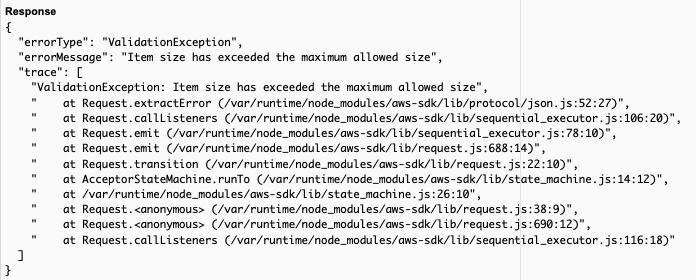
Figure 1: DynamoDB validation exception
This approach has the benefit that no custom server-side logic needs to be implemented and so costs and complexity remain low. In addition, requests that fail with this validation error don’t consume any write capacity units (WCU) from the table. The downside is that this approach might not satisfy your users’ requirements, so implementing one of the other strategies in this post is recommended.
Option 2: Store large objects in Amazon S3 with a pointer in DynamoDB
One strategy for storing a large object is to use an alternative storage platform and use a pointer to the object in DynamoDB. Amazon S3 is well suited to storing this data due to its high durability and low-cost characteristics. The implementation writes the large object to an S3 bucket, then creates a DynamoDB item with an attribute that points to the Amazon S3 URL of the object. You can then use this URL to generate a pre-signed URL to return to the caller, which has the added benefit of saving compute resources by avoiding downloading the object server-side. This architecture is illustrated in Figure 2 that follows.

Figure 2: Amazon S3 large object storage architecture
This pattern is common in content-indexing solutions where the content itself could be any size, is semi-structured, and is stored in an S3 bucket. DynamoDB then forms an index that is used as a fast lookup of where this data is stored within the S3 bucket, as explored in Building and maintaining an Amazon S3 metadata index.
In the example repository, there are two functions created that demonstrate this pattern: one that writes the item to the S3 bucket and DynamoDB, and one that reads the item and generates a pre-signed URL to return to the caller. This lets you securely download the object to the client without needing to add an additional load to the server.
If you invoke the write function with the same payload as used previously, you’ll see that this time the write succeeds, as shown in Figure 3 that follows:

Figure 3: Item written successfully
Then, if you run the corresponding read function, you get a pre-signed URL. This is shown in Figure 4 that follows.

Figure 4: Generation of pre-signed URL
This temporary URL provides access to a private-resource stored in an S3 bucket and is a secure way to grant access to those resources. If you take this URL and paste it into the browser, you retrieve the object that you stored in the S3 bucket, as shown in Figure 5 that follows:

Figure 5: Retrieval of object using pre-signed URL
One advantage of this approach is that you can store data of virtually any size in Amazon S3 (up to 5 TB per object). It also keeps your DynamoDB costs lower as you consume less space for storage and fewer read capacity units (RCU) and WCUs to read and write the item by storing just the URL in DynamoDB. The disadvantage is that a second call is required to retrieve the large object, which adds additional latency and client complexity to resolve the additional call. There are also costs associated with the storage and retrieval from S3 (see the S3 pricing page for more information).
Option 3: Split large items into item collections
Another strategy is to split a large item into a collection of items with the same partition key. In this pattern, the partition key acts as a bucket that contains all the individual parts of the original large object as separate items.
There are multiple ways to split large items into item collections. The preferred method if there are natural delineations within the object—for example if it is a large JSON object with many attributes—is to split the object so that different sets of attributes are stored as different items. This means you can selectively retrieve only the attributes you need, reducing I/O costs. For example, suppose the item is currently structured as shown in the following table:
| Partition Key | Data |
| document-a | {
|
If this item is 10 KB, it will take 1.5 RCU to make a single eventually consistent read of the item. The following table shows how this item could be split into an item collection:
| Partition Key | Sort Key | Data |
| document-a | name | John Doe |
| document-a | gender | Female |
| document-a | company | AnyCompany |
| document-a | john@example.com | |
| document-a | phone | +1 (846) 555-0100 |
| document-a | notes | Lorem ipsum dolor … |
Using this structure any single attribute can be retrieved, instead consuming 0.5 RCU per eventually consistent read, potentially reducing the required capacity of the table and therefore the cost. The entire item collection can also still be retrieved via the partition key.
This structure could be costly however if multiple items need to be frequently retrieved or updated, plus the initial write cost could be high if there are many individual attributes. An optimization is to group attributes together based on how frequently they are updated. For example, if all the attributes describing the person are fairly static, but the notes attribute changes frequently, you could structure the item collection as in the following table:
| Partition Key | Sort Key | Name | Gender | Company | Phone | Notes | |
| document-a | person | John Doe | Female | AnyCompany | john@example.com | +1 (846) 555-0100 | . |
| document-a | notes | . | . | . | . | . | Lorem ipsum dolor … |
Using this approach, all the less frequently changed attributes can be retrieved with a single request and 0.5 RCU, but can also be updated with a single WCU as they are cumulatively below 1 KB. If the original item had many hundreds or even thousands of attributes, you could create multiple of these attribute groups to help minimize the WCU required.
If the notes field could still exceed the maximum item size, or there is no clear way to split the object, such as when it is a binary object, the other option is to split the object into as many parts as necessary so that each part is small enough to fit into a DynamoDB item. You then concatenate these parts back together at retrieval time to transparently return it to the caller as one object.
Referring back to the repository samples, the write function to split items takes the input string and splits it into as many parts as needed to fit each part into the maximum item size in DynamoDB. The function then creates a separate item with the same partition key. The item is uniquely identified by an incrementing part number as the sort key. The sort key is required to provide uniqueness, see Using Sort Keys to Organize Data for more details.
In this example, each item is sent individually in a loop for simplicity. You could construct the item collection separately and write this to DynamoDB in a single operation using the BatchWriteItem API action, or if you want all items to either succeed or fail atomically, you can use the TransactWriteItem API action. The caveat is that both these API actions are limited to 25 items per request (and 16 MB aggregate size for BatchWriteItem or 4 MB aggregate size for TransactWriteItem), so you still need to incorporate iterator logic into your code if the item collection might exceed those limits.
As shown in Figure 6 that follows, the results of running this function show two items in the collection with the same partition key in DynamoDB:
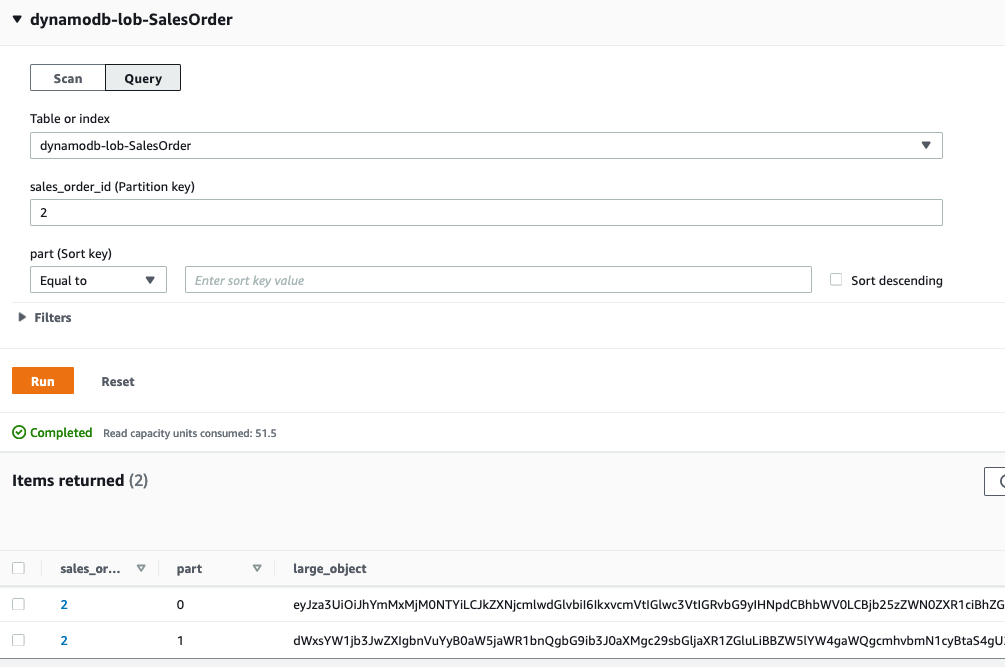
Figure 6: DynamoDB items
To read the object, you have to recombine the parts. Retrieval is straightforward as DynamoDB lets you use the partition part of the composite key to retrieve all items with that partition key. By using the Query API action to retrieve the results, you can guarantee that the parts are processed in order based on the numeric sort key of the table. You then join these parts back together server-side to abstract this implementation detail away from the caller.
This pattern also allows for previewing items. Return the first element in the item collection—the 0 part in this case—as a preview with the option of choosing a button in the UI to view more that then returns the whole string. This reduces the IOPs—and therefore cost—required by only loading a preview of the data by default and loading the rest only if requested.
The disadvantages of this approach are that complexity is high on the server-side to split and recombine the parts and so these functions must be well-tested in order to avoid data loss. Another consideration is the extra RCUs needed to return all of the items to make up the original object. For larger objects, consider using an alternate data-store, as discussed in Option 2 or combining with Option 4 to reduce the capacity required per item.
Option 4: Compress large objects
In this final section, you explore compressing large objects. You learn two compression algorithms that can be used to perform the compression and the benefits and drawbacks of each.
First, let’s look at the native zlib compression built into the Node.JS standard libraries. Within the samples repository there is a zlib folder. Within this folder are two Lambda functions, one for writing the data and one for reading the data.
Using the same payload as earlier, you first invoke the write function, which uses the gzip function to compress the item. When the function completes, you get a success message as shown in Figure 7 that follows.

Figure 7: Gzip write success
Then the read function uncompresses this string to the original verbose payload which is returned when the read function is complete, as shown in Figure 8 that follows.

Figure 8: Gzip read success
Next, try snappy compression. Again, under the snappy folder there are two functions—one to write, one to read.
Invoking the write function uses the snappy node.js bindings to compress the large string and write the resulting smaller string to DynamoDB:

Figure 9: Snappy write success
Then the read function uncompresses the string back to the original:

Figure 10: Snappy read success
As you see in the table that follows, snappy is faster—as it’s described to be—averaging 180 ms per invocation compared to 440 ms for zlib for writes over the 100 executions I tried, but with a comparatively weak compression ratio of 50 percent (208 KB) compared to zlib’s 66 percent (139 KB). This is fine for our use-case, and might be for yours too. Remember that in a serverless environment such as this, you’re billed by the millisecond, so if speed of execution is the primary concern, snappy might be a good fit. zlib, while providing slower compression, is a native implementation. It doesn’t require any additional packages to be installed, so if you’re working in an environment that prohibits third-party software, then this provides a quick and simple solution that might be good enough for your use-case. A comparison of how these differences effect the cost of your application is shown in the table that follows:
| Compression | Item size (KB) |
DynamoDB WCU per request |
Lambda execution (ms) per request |
DynamoDB WCU cost per month ($) | Lambda execution cost per month ($) | Total cost ($) |
| uncompressed | 420 | – | – | – | – | – |
| snappy | 208 | 208 | 180 | 11160.24 | 446.76 | 11607 |
| zlib | 139 | 139 | 440 | 7458.05 | 1016.16 | 8474.21 |
Based on 100 executions per second of a 512 MB Lambda function for one month in the eu-west-1 Region
There are other compression algorithm libraries you can use, such as lzo and zstandard, that offer different performance characteristics. Please keep in mind that there might be licenses needed for the different algorithm libraries you adopt within your own projects.
One disadvantage of the compression strategy is that it adds some overhead to the compute time, regardless of the algorithm you use. This approach is also only suitable if the data can be compressed down to fit within the item size limit, which you might not know ahead of time. If the size of your data is predictable or there is a defined upper limit that happens to be within the compression ratio, then it might be suitable as a standalone solution. For data that is orders of magnitude above the item limit, it’s unlikely to compress down enough to fit. If that’s the case, using compression in conjunction with the item-splitting solution discussed earlier is a viable option. The advantage of compression is simplicity, with the implementation being transparent to the caller and reducing the need to restructure the item or use additional AWS services to supplement the storage.
Clean-up
The Lambda function invocations and DynamoDB usage described in this post should fall within the Amazon Web Services (AWS) free tier for those services, so you shouldn’t incur any charges for these services until you exceed the free usage tier. After that, pricing details for both services are found on the DynamoDB pricing page and Lambda pricing page.
If you deployed the example SAM template, then delete the AWS CloudFormation stack from the CloudFormation console.
Final considerations
Depending on the access patterns and characteristics of your workload, any of these approaches could be suitable. Below are some final considerations to help you pick the right strategy for your workload.
Storing large objects in Amazon S3
- By distributing your workload across multiple data stores, you lose transactional consistency. AWS Step Functions can be used to establish consistency in distributed systems, for example by using the saga pattern.
- If you’re using DynamoDB’s global table feature for multi-Region replication, consider replicating the S3 bucket to the other Regions, particularly for disaster recovery scenarios. This can be achieved using the S3 Cross-Region Replication feature.
Splitting large items into item collections
- If you’re using global or local secondary indexes as part of your DynamoDB table, consider whether the large attributes need to be projected to the secondary indexes. Using the base table for lookups of the large object parts and secondary indexes for other access patterns without this attribute projected can save costs on the storage and the write capacity required to propagate these changes to the index.
- Queries and scans in DynamoDB can retrieve a maximum of 1 MB of data. If the total result size is greater than this, you will have to make multiple paginated calls or use the BatchGetItem API.
Compression
If you need to perform filter expressions for your queries, then this won’t be possible with a compressed string as DynamoDB cannot natively decompress the object.
Conclusion
For many DynamoDB use-cases, you have to consider how you treat large objects. Making a conscious design decision up-front allows for the limits and access patterns of the system to be understood and provides a scalable and performant solution as the data size grows. To understand more design considerations when adopting DynamoDB, see How to determine if Amazon DynamoDB is appropriate for your needs. For more data modeling tips, see Data modeling with NoSQL Workbench for Amazon DynamoDB.
Test the options discussed in this post by deploying the code samples yourself and let me know your thoughts in the comments section below.
About the Author
 Josh Hart is a Senior Solutions Architect at Amazon Web Services. He works with ISV customers in the UK to help them build and modernize their SaaS applications on AWS.
Josh Hart is a Senior Solutions Architect at Amazon Web Services. He works with ISV customers in the UK to help them build and modernize their SaaS applications on AWS.