AWS Database Blog
Migrating mission-critical SaaS production workloads to Aurora MySQL from RDS Classic
Sumo Logic started around the same time as the AWS stack was starting to mature. The company initially chose infrastructure that was tried and tested, but also cutting-edge at the time, namely Amazon RDS for MySQL instances.
However, over time, that choice started to cost us a significant number of developer hours. Developers spent time performing MySQL version upgrades, scaling instances due to increased database connections, and scaling storage as data and demand from our customers grew with us.
This meant that there was a constant struggle between having customer-visible downtime and staying on an older version of MySQL for too long. We needed a solution that was more hands-off, robust, and flexible for any future workloads we may see as we grew.
Who we are
Sumo Logic is a secure, cloud-native machine-data analytics platform. It delivers real-time, continuous intelligence from structured, semi-structured, and unstructured data across the entire application lifecycle and stack.
More than 2,000 customers around the globe rely on Sumo Logic for the analytics and insights to build, run, and secure their modern applications and cloud infrastructures. With Sumo Logic, customers gain a multi-tenant service-model advantage to accelerate their shift to continuous innovation, increasing competitive advantage, business value, and growth.
Why we migrated to Amazon Aurora
Migrating over to Amazon Aurora provided several benefits over the classic RDS implementation provided by Amazon:
- Fully managed: Aurora instances and clusters are fully managed by Amazon RDS. This management provides the ability to scale, add storage, and perform upgrades and patches with minimal downtime. In most cases, these are done without incurring any client interruptions. This is a great win for our infrastructure team, which is supporting a very high rate of growth and scale for Sumo Logic.
- High availability and durability: One of our biggest concerns with classic MySQL was the customer-visible downtime that came with any maintenance, network partition, or loss of service. Aurora provides much greater resilience on these points.
- Compatibility: A key feature of Aurora is the compatibility with MySQL, which meant that we never had to make a code change in our clients. Things just worked out of the box.
- VPC by default: Along with migrating to a better database system, we also migrated to Amazon VPC for another layer of isolation, security, and ability to operate as a private network. Aurora instances being in VPC by default provided us with an added advantage when moving over our non-VPC Amazon EC2 instances to VPC.
Challenges and migration approaches that we considered
Sumo Logic processes hundreds of petabytes of data every day. Any disruption, delay, or downtime becomes orders of magnitudes worse and absolutely critical, given that we are the solution that our customers use to deal with similar issues of their own. We host terabytes of storage with thousands of database operations per second across each of our databases in eight-plus AWS Regions all over the world. Hundreds of thousands of users log in to Sumo services every day.
VPC
To migrate our EC2 instances (non-VPC) running on EC2-Classic networking platform (that hosted our application) to VPC, we needed to migrate all our databases into VPC first. This was because if you want an EC2 instance that is in VPC to access a database that is not in VPC, it needs to do so over the public internet. This migration thus meant opening up our VPC to the internet. This was a security concern, even though in this case both the EC2 instance and RDS instance are protected by their own security groups for user access.

For some background on this process, see Scenarios for Accessing a DB Instance in a VPC in the RDS documentation.
Downtime
The push-button migration that Amazon provides for RDS instances incurs about 5–10 minutes of downtime, at the time we performed the migration. We were aiming for minimal or no downtime because even with maintenance windows, our systems are always operational. We ingest hundreds of petabytes of data on any given day and perform thousands of database operations per second. Any downtime thus causes problems across the board.
We wanted two things:
- A database migration that itself would be guaranteed instantaneous.
- Control over how we managed the database writes while doing the switchover.
Read replicas
Even though you can create read replicas for RDS DB instances, you can’t do so across the VPC boundary. This means that an instance needs to be in a VPC for its read replica to also exist in a VPC.
We had a few discussions with our AWS technical account managers regarding the possible options to mitigate the above challenges. They were a great source of information and support during this whole process. They provided us with an AWS whitepaper on the topic that detailed moving RDS MySQL databases to VPC. But this was not a use-case that worked for us due to the challenges mentioned preceding.
Around the same time, we started planning to migrate over our databases to Aurora. By our figures, if we did the migration to VPC and migration to Aurora separately, it would have taken us six-plus months. It would have also cost a lot of development hours, mainly due to the slow rollout and minimum downtime requirements per deployment. Instead, migrating directly to Aurora from RDS DB instances on the EC2-Classic networking platform accomplished both goals in a single migration effort, saving us three months of cost and effort.
In the end, we chose to use the Aurora migration path using Aurora read replicas.
Planning
There are several considerations when performing a task that is going to affect literally all parts of your distributed system. Planning is crucial when working with several teams (infrastructure, ingest, search, security, analytics, customer success, and so on) with varying upgrade cycles, expectations, workloads, and impacts on service interruption. Because databases are central to any operations of our service, all teams were equally affected and had to either communicate internally or to customers.
As part of planning, you have to consider dependencies between databases, modules, services, and teams. If possible, you have to try to group together migrations that are mostly independent of each other for faster turnaround time.
Here’s an example of a roll out plan that we used and shared with all teams.
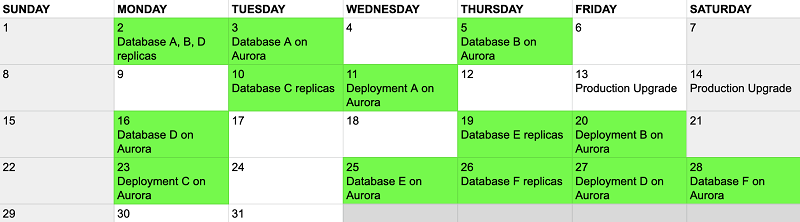
How we migrated our RDS DB instances to Aurora in VPC
Moving to Aurora directly instead of migrating the RDS instances into VPC first gave us both Aurora and VPC in one shot.
Amazon Aurora provides a great migration path for this very purpose: Aurora read replicas. These replicas were designed to be used across the VPC boundary and gave us a replicating copy of our data inside VPC directly. This way, we skipped the complex process of moving our existing RDS instances to VPC. Instead, we directly migrated them to Aurora, which gave us VPC by default. For a great step-by-step description of the process, see the post Create an Amazon Aurora Read Replica from an RDS MySQL DB Instance on the AWS News blog.
Migration: Creation of Aurora Read Replicas
First step was to create Aurora read replicas for each of our databases. Creating these does a few things:
- Creates a snapshot of your database.
- Migrates this snapshot to the Aurora read replica.
- After snapshot migration, Amazon RDS starts replication between your RDS MySQL database and the Aurora read replica.
All of this happens in the background and there is minimal overhead to the operation of the master database — which was no more than a ~5-10% increase in memory and CPU utilization, as seen through Amazon CloudWatch metrics monitoring. However, keep in mind that once the snapshot is migrated, binary log replication can have a similar detrimental performance impact on the master database, so we had to make sure that we size up any DB instances that were near our alert thresholds for CPU, memory or database connections, given the above increase in usage.

This process typically took anywhere between four to six hours per database. Considering hundreds of databases contained on about a hundred database instances across all AWS Regions, it was crucial that this step be started as soon as possible. It also needed to be finished long before we start the actual switchover. Thankfully, this process was mostly nonintrusive, apart from some increased load on the master instances. (We had previously provisioned higher in anticipation of this.)
After all the Aurora replicas were created for our master databases and they were all replicating, it was time for the migration.
Switchover Time!
In our switchover process, we took these steps:
- Made note of all database connections before the migration. We figured that these should roughly be the same after the migration, that is roughly same number of services and processes should be talking to the databases as before. This was just a simple sanity test to make sure that nothing was wrong in a major way.
- Routed or muted all internal Sumo Logic database alerts appropriately.
- Stopped all services that talk to databases. This was to ensure a few things:
- No data was being written to the older databases during the migration.
- No data was picked up off our internal custom queues. This way we could afford a bit of queue backup, but ensure that data was not lost.
- For our use case and considering that we can look at Sumo Logic as a reverse of a streaming service, near-zero downtime from all systems was nearly impossible without loss of data, if we did not stop writes completely. We mainly needed to make sure that the actual switchover from replica to master was instantaneous, which it was. We controlled the rest by use of queues and replaying the data through our services after the switchover was done.
- Confirmed replication status to ensure that there would be no data that is in the old database that has not yet been replicated to the new one. This can be checked using the “Show slave status” option, in addition to ensuring that the replica lag value is 0.

- Made sure that the older database connection count was now zero. This ensured that there were no straggler services still talking to those databases.
- Promoted the Aurora read replica to become a master by choosing Promote read replica for Actions on the console.

Post-migration
After migration, we took these steps:
- Enabled appropriate backups for the new Aurora cluster.
- Updated the service registry to point to the new Aurora instances, so that after we brought back the stopped services, they connected to those instances.
- Brought all the services back online.
Voilà! The migration is complete!
Migration health-check metrics
One of the most important metrics to monitor during the switchover is Login failures.
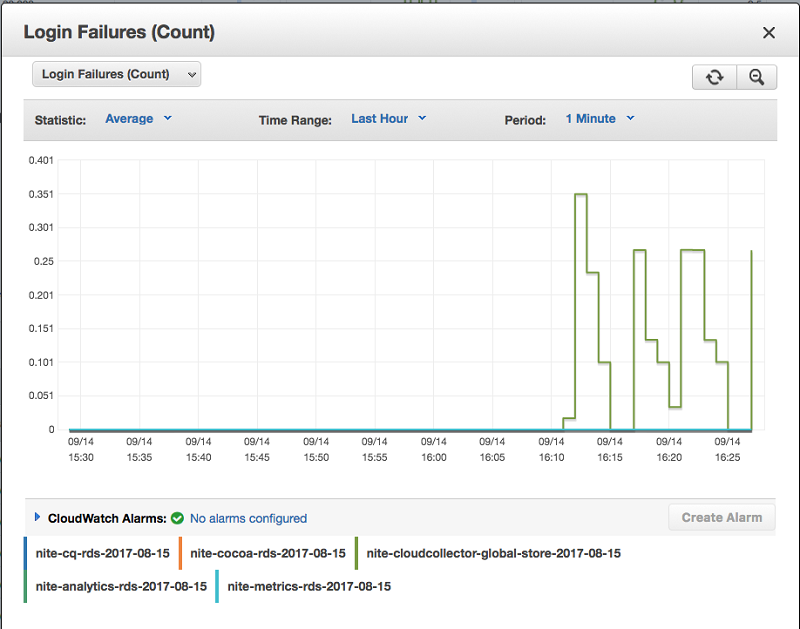
This metric indicates that one or more of your services is unable to connect to the new master instances.
Other metrics to monitor:
- Aurora replica lag — to ensure that the Aurora replicas are in-sync with the RDS DB Instances and it is safe to perform the switch-over.
- CPU Usage — Sudden (re)connection of thousands of processes/threads can cause the CPU usage to shoot up much higher than steady-state operation.
- DB Connections — A huge disparity between before and after connection counts can indicate a systemic problem.
- Select latencies — Similar to CPU usage, sudden connection of all previously stopped processes might lead to slower select queries and could cause system wide issues.
(There could be many other metrics you might want to monitor based on your use case)
Tooling and Automation
We had hundreds of databases on about a hundred instances to migrate over, each containing terabytes of data. If a process of this scale is done manually, this could mean a lot of places for human errors to get introduced:
- Wrong instance type
- Wrong storage sizing
- Missing instances
- Missing backups
- Missing security configurations
- Missing parameter configurations
- Missing the upgrade windows as mandated by our SLAs
- Special configuration for certain databases that span across multiple regions
We wanted to eliminate any deviation of process between any two database migrations.
A non-exhaustive list of things we automated/added tooling for: (these were in-house tools developed specifically for our use case with future migrations in mind.)
- Verification of database connections
- Verification of replica lag
- Creation of Aurora replicas
- Promotion of replicas to Master
- Switching service registry to point to the new instances
- Handling of database specific alerts
- Instance type scaling
Conclusion
Migrating all of our databases took about 3-4 months including the pre-migration steps while keeping all of our systems operational.
Throughout all of this, we had great help from our AWS technical account managers (TAMs) and the Aurora team. We had a few back and forth discussions with them and they always there to help us out and hash out possible strategies. The TAMs also ran several pressure tests and mock migrations on varying types of configurations and accounts included classic (individual AWS accounts), managed (administrator managed), VPC only and hybrid (classic and VPC).
We relied heavily on monitoring and KPIs during this migration (as mentioned in the switchover section), both from AWS Cloudwatch and the internal monitoring using of our own Sumo Logic platform.
Since we use Sumo Logic internally to monitor our own service and infrastructure, we have a massive collections of Sumo Logic dashboards per service that helped our on-call engineers to quickly diagnose and triage any issues caused during the migration like login failures, pre and post migration comparisons on database connections, select throughput, latency, service stability, measurable customer downtime and impact on search, indexing, and streaming of petabytes of data into Sumo Logic.
We were able to migrate about a hundred database instances with hundreds of databases within them, with zero downtime from the customers’ perspective because:
- a.) We controlled when and how our internal downtime should occur by stopping services that talk to databases for a short period, along with queueing, caching of data and help of other AWS services like DynamoDB and S3.
- b.) We had the knowledge and assurance of the Amazon Aurora migration such that the actual switch-over from replica instance to master was almost instantaneous.
Detailed planning with accounting for production upgrades, spikes, downtimes, etc. and most importantly, unknowns, bugs and production fires helped us to stay on course with all teams being in the know at all times.
This migration allowed us to move from older hardware and systems to the latest the RDS platform has to offer, and while doing so, we were able to make our systems more robust and future proof not just in terms of technology, but also processes and future migrations.
Other useful links & references
- Amazon Aurora: https://aws.amazon.com/rds/aurora/
- A Primer on Building a Monitoring Strategy for Amazon RDS: https://www.sumologic.com/blog/amazon-web-services/amazon-rds-monitoring-strategy/
- Migrating Data from a MySQL DB Instance to an Amazon Aurora:
- https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Migrating.RDSMySQL.Replica.html
- Monitor AWS Aurora MySQL and PostgresSQL Database with Sumo Logic: https://www.sumologic.com/blog/using-sumo/aws-aurora-mysql-postgres-apps/
About the Author

Aditya Kelkar is a backend engineer at Sumo Logic in the data and infrastructure team, working on designing and developing next generation features. Aditya also works on ensuring that Sumo Logic has a robust, scalable infrastructure that is up to date with the latest industry standards and trends including containers, microservices and large-scale distributed systems. In his spare time, he enjoys woodworking and playing with his dog.