AWS Database Blog
Performing a Live Migration from a MongoDB Cluster to Amazon DynamoDB
Migrating data from one database to other can be quite challenging with respect to data consistency, downtime of applications, and key design differences between the target and source databases. AWS Data Migration Service (AWS DMS) helps you migrate databases like MongoDB, Oracle, MySQL, and Microsoft SQL Server to AWS quickly, securely, and seamlessly. The source database remains operational during most of the migration, hence minimizing downtime to applications that rely on the database.
In this post, we discuss the approach for seamless migration of live data from a sharded MongoDB cluster to an Amazon DynamoDB table. Amazon DynamoDB is a fully managed, fast, highly scalable, and flexible cloud database service for applications that need consistent, single-digit millisecond latency at any scale. The approach described in this post performs the migration with near-zero downtime, transforms the source data using AWS DMS, and provides a few application access patterns.
Mapping between DynamoDB and MongoDB components
Before starting on the migration journey, let’s quickly compare Amazon DynamoDB and MongoDB components. Even though many concepts in DynamoDB and MongoDB are similar, and both allow applications to store JSON-like data with a flexible dynamic schema, the two differ significantly in some ways.
This section describes a few core DynamoDB concepts and compares DynamoDB and MongoDB components. Refer to the MongoDB documentation for more details on MongoDB concepts.
Core components
In Amazon DynamoDB, tables, items, and attributes are the core components that you work with. A table is a collection of items, and each item is a collection of attributes. DynamoDB uses primary keys to identify items in a table uniquely, and it uses secondary indexes to provide more querying flexibility. Each table is an isolated unit with corresponding indexes, capacity, and scalability configurations. Both DynamoDB and MongoDB allow you to divide your datasets into collections of items.
The following table maps some of the common components of both DynamoDB and MongoDB.
| MongoDB | DynamoDB |
| Collection | Table |
| Document | Item |
| Field | Attribute |
| Secondary index | Secondary index |
Indexing
When you create a table in Amazon DynamoDB, you must specify the primary key of the table. The primary key uniquely identifies each item in the table so that no two items can have the same key.
DynamoDB supports two kinds of primary keys:
- Partition key – A simple primary key, composed of one attribute known as the partition key.
- Partition key and sort key – Referred to as a composite primary key, this type of key is composed of two attributes. The first attribute is the partition key, and the second attribute is the sort key.
DynamoDB provides fast access to items in a table by specifying primary key values. However, to allow efficient access to data with attributes other than the primary key, many applications might benefit from having one or more secondary (or alternate) keys available. To address this scenario, DynamoDB supports two types of secondary indexes:
- Global secondary index – An index with a partition key and a sort key that can be different from those on the base table
- Local secondary index– An index that has the same partition key as the base table, but a different sort key
You can create up to five local secondary indexes when you create a table, each referencing the same partition key as the base table and a range key. You can also create up to five global secondary indexes with either a hash key or a hash key and a range key using attributes other than the item’s primary key. You can choose to project some or all of the table’s attributes into each of the tables indexes.
The following table outlines mapping between DynamoDB and MongoDB indexing strategies.
| MongoDB | DynamoDB |
| Single field | Partition key/global secondary index |
| Compound index | Partition key and sort key/local secondary index/global secondary index |
| Multi-key index | Use one-to-many tables instead of large set attributes and create a local secondary index/global secondary index on top-level attributes |
| Geospatial index | Geospatial indexing and Geo Library |
| Text index | Full-text search by integrating with Amazon OpenSearch Service (Amazon ES) |
| Shard key | Partition key |
Queries
Amazon DynamoDB provides the following three operations for retrieving data from a table:
- GetItem – Retrieves a single item from a table by its primary key.
- Query – Retrieves all items that have a specific partition key. In addition, you can provide a filter condition to the sort key or to any other fields within the table and retrieve only a subset of the data.
- Scan – Retrieves all items in the specified table. It provides more flexibility in defining filter conditions on any field in the table, but it might be costly or time-consuming because it scans the entire contents of the table.
In DynamoDB, you perform Query operations directly on the index; it is always advised to design your schema to leverage indexes for efficient lookup.
Sample MongoDB dataset for migration
In this section, we discuss the migration of a sample dataset containing arrival data for domestic flights by major air carriers in the US beginning with 1987. This dataset provides details such as departure and arrival delays, origin and destination airports, flight numbers, scheduled and actual departure/arrival times, and non-stop distance.
The sample dataset is stored in a MongoDB collection in JSON format as shown in the following example. This collection is sharded for distributing data across the shards, using a shard key index on the Origin and Year fields.
The MongoDB collection also has a unique compound index on the following fields: Origin, Year, UniqueCarrier, FlightNum, DayofMonth, Month, and CRSDepTime (scheduled departure time). This index is optimized for common scenarios like generating a list of delayed flights by airport for a year, scheduled flight details, etc.
Migration approach using AWS DMS
AWS DMS supports migration from a MongoDB collection as a source to a DynamoDB table as a target. AWS DMS supports the MongoDB migration in two modes:
- Document mode: In this mode, AWS DMS migrates all the JSON data into a single column named “
_doc” in the target DynamoDB table. - Table mode: In this mode, AWS DMS scans a specified number of documents in the MongoDB database and creates a sample schema with all the keys and their types. During migration, you can use the object mapping feature in AWS DMS to transform the original data from MongoDB to the desired structure in DynamoDB.
This post primarily covers the table mode of migration.
The following is a high-level diagram showing the data flow from a MongoDB sharded cluster to Amazon DynamoDB:
To perform a database migration, AWS DMS connects to the source MongoDB database, reads the source data, transforms the data for consumption by the target DynamoDB tables, and loads the data into the DynamoDB tables.
For a sharded collection, MongoDB distributes documents across shards using the shard key. To migrate a sharded collection from a sharded cluster, you need to migrate each shard separately.
In our approach, we perform migration of each shard separately to a single DynamoDB table using one AWS DMS task per shard.
Following are the high-level tasks involved in migrating data from a MongoDB sharded cluster to DynamoDB using AWS DMS:
- Prepare the MongoDB cluster for migration.
- Create the replication server.
- Create the source MongoDB endpoint and the target DynamoDB endpoint.
- Create and start the replication tasks to migrate data between the MongoDB cluster and DynamoDB.
Prepare the MongoDB cluster for migration
Step 1: Disable the Balancer in the source MongoDB cluster and wait for any in-process chunk migrations to complete. This is required to avoid any errors that involve in-progress migrations from one shard to another. Refer to Disable the Balancer in the MongoDB documentation for more details.
Step 2: Run the cleanupOrphaned command in the primary replica of each shard. This removes any orphaned documents left over by failed migrations or application errors. See cleanupOrphaned in the MongoDB documentation for more details.
Step 3: To use change data capture (CDC) with a MongoDB source, enable the MongoDB operations log or oplog. This log is a special capped collection in MongoDB that keeps a rolling record of all operations that modify the data stored. To enable oplog in MongoDB, deploy a replica set that creates an oplog. For more information about oplog and replica sets, refer to the MongoDB documentation.
You also need a system root user in MongoDB with permission to access oplog, the source database, and collections.
Create the replication server
AWS DMS creates a replication instance in a virtual private cloud (VPC). Select a replication instance class that has sufficient storage and computing power to perform the migration task, as mentioned in the whitepaper AWS Database Migration Service Best Practices. Choose the Multi-AZ option for high availability and failover support using a Multi-AZ deployment, as shown in the following screenshot. You can specify whether a replication instance uses a public or private IP address to connect to the source and target databases. A replication instance should have a public IP address if the source or target database is located in a network that isn’t connected to the replication instance’s VPC using a virtual private network (VPN), AWS Direct Connect, or VPC peering.
You can specify whether a replication instance uses a public or private IP address to connect to the source and target databases. A replication instance should have a public IP address if the source or target database is located in a network that isn’t connected to the replication instance’s VPC using a virtual private network (VPN), AWS Direct Connect, or VPC peering.
You can create one replication instance for migrating data from all shard source endpoints, or you can create one replication instance for each shard source endpoint. We recommend that you create one replication instance for each shard endpoint to achieve better performance when migrating large volumes of data.
Create the source MongoDB endpoint
The following screenshot shows the creation of a source endpoint for the MongoDB database. Create one source endpoint for the primary replica of each shard. This step is required to migrate data from each shard individually.
The following example shows the source endpoint for three shards:
Create the target DynamoDB endpoint
The following screenshot shows the creation of a target endpoint for Amazon DynamoDB: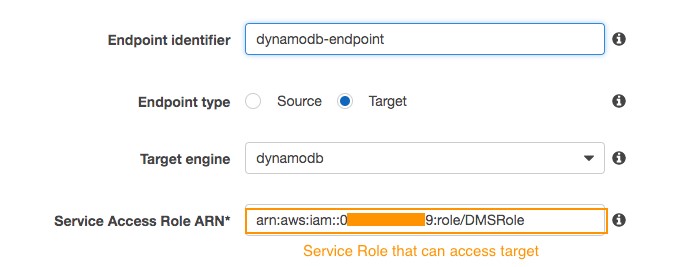 AWS DMS creates a table on a DynamoDB target endpoint during the migration task execution and sets several DynamoDB default parameter values. Additionally, you can pre-create the DynamoDB table with the desired capacity optimized for your migration tasks and with the required primary key.
AWS DMS creates a table on a DynamoDB target endpoint during the migration task execution and sets several DynamoDB default parameter values. Additionally, you can pre-create the DynamoDB table with the desired capacity optimized for your migration tasks and with the required primary key.
You need to create an IAM service role for AWS DMS to assume, and then grant access to the DynamoDB tables that are being migrated into.
Create tasks with a table mapping rule
Both MongoDB and Amazon DynamoDB allow you to store JSON data with a dynamic schema. DynamoDB requires a unique primary key—either a partition key or a combination of a partition and a sort key. You need to restructure the fields to create the desired primary key structure in DynamoDB.
The partition key should be decided based on data ingestion and access patterns. As a best practice, we recommend that you use high-cardinality attributes. For more information about how to choose the right DynamoDB partition key, refer to the blog post Choosing the Right DynamoDB Partition Key.
Based on the example query patterns described in this post, we recommend that you use a composite primary key for the target DynamoDB table. Use a composite primary key with a partition key that is a combination of the same fields as in the MongoDB shard key (the Origin and Year attributes), and a sort key that is a combination of the DayofMonth (day of travel), Month, CRSDepTime (scheduled departure time), UniqueCarrier and FlightNum attributes.
The following screenshot shows the attribute mapping between MongoDB and DynamoDB. For a sharded collection, MongoDB distributes documents across shards using the shard key. To migrate a sharded collection to DynamoDB, you need to create one task for each MongoDB shard.
For a sharded collection, MongoDB distributes documents across shards using the shard key. To migrate a sharded collection to DynamoDB, you need to create one task for each MongoDB shard.
Create an AWS DMS migration task by choosing the following options in the AWS DMS console for each shard endpoint:
- Specify the Replication instance.
- Specify the Source endpoint and Target endpoint.
- For Migration type, choose Migrate existing data and replicate ongoing changes to capture changes to the source MongoDB database that occur while the data is being migrated.
- Choose Start task on create to start the migration task immediately.
- For Target table preparation mode, choose Do nothing so that existing data and metadata of the target DynamoDB table are not affected. If the target DynamoDB table does not exist, the migration task creates a new table; otherwise, it appends data to an existing table.
- Choose Enable logging to track and debug the migration task.
- For Table mappings, choose Enable JSON editing for table mapping.
The following screenshot shows these settings on the Create task page in the console: Table mappings in Create task
Table mappings in Create task
AWS DMS uses table mapping rules to map data from a MongoDB source to Amazon DynamoDB. To map data to DynamoDB, you use a type of table mapping rule called object mapping.
For DynamoDB, AWS DMS supports only map-record-to-record and map-record-to-document as two valid options for rule-action. For more information about object mapping, see Using an DynamoDB Database as a Target for AWS Database Migration Service.
In our example, we set the object mapping rule action as map-record-to-record while creating the AWS DMS task. The map-record-to-record rule action creates an attribute in DynamoDB for each column in the source MongoDB. AWS DMS automatically creates the DynamoDB table (if it’s not created already), the partition key, and the sort key, and excludes any attributes based on the object mapping rule.
The following table mapping JSON has two rules. The first rule has a rule type as selection, for selecting and identifying object locators in MongoDB. The second rule has a rule type as object mapping, which specifies the target table-name, definition, and mapping of the partition key and sort key.
For more information about the object mapping for DynamoDB, see Using Object Mapping to Migrate Data to DynamoDB.
The following image shows migration tasks for three shards (corresponding to three source endpoints that were created in the previous step): Monitor the migration tasks
Monitor the migration tasks
The AWS DMS task can be started immediately or manually depending on the task definition. The AWS DMS task creates the table in Amazon DynamoDB with the necessary metadata, if it doesn’t already exist. You can monitor the progress of the AWS DMS task using Amazon CloudWatch, as shown in the following screenshot. For more information, see Monitoring AWS Database Migration Service Tasks. You can also monitor the AWS DMS task using control tables, which can provide useful statistics. You can use these statistics to plan and manage the current or future tasks. You can enable control table settings using the Advanced settings link on the Create task page. For more information, see Control Table Task Settings.
You can also monitor the AWS DMS task using control tables, which can provide useful statistics. You can use these statistics to plan and manage the current or future tasks. You can enable control table settings using the Advanced settings link on the Create task page. For more information, see Control Table Task Settings.
The following screenshot shows the log events and errors captured by CloudWatch:
Modifying the application to use a DynamoDB endpoint
Refactoring of the application code is required when you migrate from MongoDB to Amazon DynamoDB. The following Java code snippets focus on connection and a few query access patterns. For more information and other access patterns, see Programming with DynamoDB and the AWS SDKs.
Establish a connection to the database
The following are examples of connecting to databases in MongoDB and Amazon DynamoDB.
MongoDB:
The following example shows how to connect to the airlinedb database and get a handle to the airline collection.
DynamoDB:
Setting your AWS credentials: The following is an example of an AWS credentials file named ~/.aws/credentials, where the tilde character (~) represents your home directory:
The following example shows how to establish a connection to the airlineData table in the Oregon (US_WEST_2) Region.
Query patterns
The following are examples of querying data from a MongoDB collection and from a DynamoDB table.
MongoDB:
The following code snippets demonstrate querying data from a MongoDB collection.
Scenario 1: Retrieve all flight details with a delayed departure in San Diego International Airport for the year 2017:
Scenario 2: Retrieve flight status for PS-1451 scheduled to depart on October 14, 2017, at 07:30 AM from San Diego International Airport:
DynamoDB:
The following code snippets demonstrate querying data from a DynamoDB table.
Scenario 1: Retrieve details of all flights with a delayed departure from San Diego International Airport for the year 2017:
Scenario 2: Retrieve the flight status for PS-1451 scheduled to depart on October 14, 2017, at 07:30 AM from San Diego International Airport:
For additional query patterns for DynamoDB, refer to Working with Queries.
Conclusion
In this post, we discussed migrating data from MongoDB to Amazon DynamoDB in near-real time with continuous data capture using AWS DMS. AWS DMS helps you migrate your data, including sharded data stored in MongoDB, to DynamoDB quickly and securely. During the migration process, the source MongoDB database remains fully operational, minimizing downtime to applications that rely on the database.
Because Amazon DynamoDB supports both document and key-value data structures, moving a MongoDB JSON document is relatively simple. The JSON format of your data stored in MongoDB doesn’t need to change much.
If you have questions or suggestions, please leave a comment below.
About the Authors
 Gururaj S Bayari is a solutions architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.
Gururaj S Bayari is a solutions architect at Amazon Web Services. He works with our customers to provide guidance and technical assistance on database projects, helping them improving the value of their solutions when using AWS.
 Arun Kannan is a partner solutions architect with the Global System Integrator (GSI) team at Amazon Web Services. He works with the GSIs to provide architectural guidance for cloud adoption, solution’s development and migration strategy.
Arun Kannan is a partner solutions architect with the Global System Integrator (GSI) team at Amazon Web Services. He works with the GSIs to provide architectural guidance for cloud adoption, solution’s development and migration strategy.