AWS for Games Blog
Elevate Game Design with Recommendations for Virtual Goods, Quests, and Game Balance using Amazon Personalize
Authored by Molly Sheets and edited by Kyle Somers
Today’s games need specialized content to increase retention, drive monetization, and promote feature adoption. No game has a singular player persona: Two players can have vastly different engagement metrics and styles of play over their lifetime with a portfolio. Indie developers and AAA developers alike are challenged with designing gameplay that fits evolving personalities and then segmenting this content to be delivered to players based on personal preferences, location, historical behaviors, and the current meta for games. Game designers familiar with design theory know that elevating content that speaks to player personas is more effective if the right content is put in front of the appropriate player type. This is easier said than done as players often do not fall into a box; rather they exhibit a combination of attributes as they interact with each other, against each other, or against the play space itself.
As a result, developers investigate AI/ML solutions that enable them to attain better gameplay metrics based on user cohorts with an increasing interest in content personalization. Take quest systems, which have a mosaic of quest types, as a use case. While holistically quests serve the need to meet the expectations of an achiever, even achievers are divided into cohorts. In an MMO, quests use escort, collection, and combat mechanics. These can be broken down further with players preferring to play in specific worlds or complete content on behalf of a faction. In a battle royale game, progression systems are often designed to encourage a player to pick a new hero, use a different weapon, or achieve skill-based goals. In games with dungeoning, it is a struggle to find a balance of online players to fill a party of roles. Finally, developers are looking to feature virtual goods, such as outfits, that speak to individual player identities. Between showing popular items for a geographical location, encouraging play of underutilized heroes, all the way to highly personalized recommendations for an individual, the lucrative and lofty goal to achieve results is a feat of strength for any game studio.
Historically, real-time recommendation engines for games use cases required deep expertise in data science along with infrastructure. These alone are prohibitive to developers who do not have the budget to build custom AI/ML solutions against the challenges of a hit-driven industry. This blog reviews how Amazon Personalize, a managed service and suite of APIs, makes it possible to create customized content and influence player behaviors to generate positive sentiment through personalization models. Driven by the AI/ML and infrastructure backing of AWS’ years of experience powering recommendations used by Amazon.com, you can have an in-game recommendation engine without having to write your own models or manage training and inference infrastructure.
Key Takeaways
- Readers will review architectural patterns and best practices when using Amazon Personalize to create recommendation campaigns for games use cases.
- Readers will learn technical requirements for Amazon Personalize when used with analytics data by training their recommendation engine daily or weekly using scheduled jobs with an existing analytics pipeline.
- For developers looking to ingest in real-time to the Amazon Personalize service for their recommendation engine, this blog then reviews the architectural patterns and SDKs used to facilitate real-time recommendations with data ingested to Amazon Personalize using PutEvents() calls.
24-Hour or Weekly Recommendations
Many games do not require near real-time training as part of their recommendation engine. For example, games with stores that update daily or weekly with popular items based on purchases in a geographic region or UI tabs that feature individual recommendations for a user may only need to train their model once every 24 hours or once a week. Developers should re-train their models to maintain the relevance of recommendations based on recent and evolving user behavior; thus, if behavioral evolution is significantly influenced by new content patches or game updates that occur less frequently, a developer may not need to train a model as often. Training can happen on a 24-hour or weekly schedule, spending significantly less on infrastructure with fewer models needing to be retrained.
With this architecture, a new campaign version is generated using the same campaign endpoint and made available to users when the store updates or when designers prefer the in-game screen to be refreshed with the latest, most popular items and recommended content. It also means fewer calls will be made to the service overall.
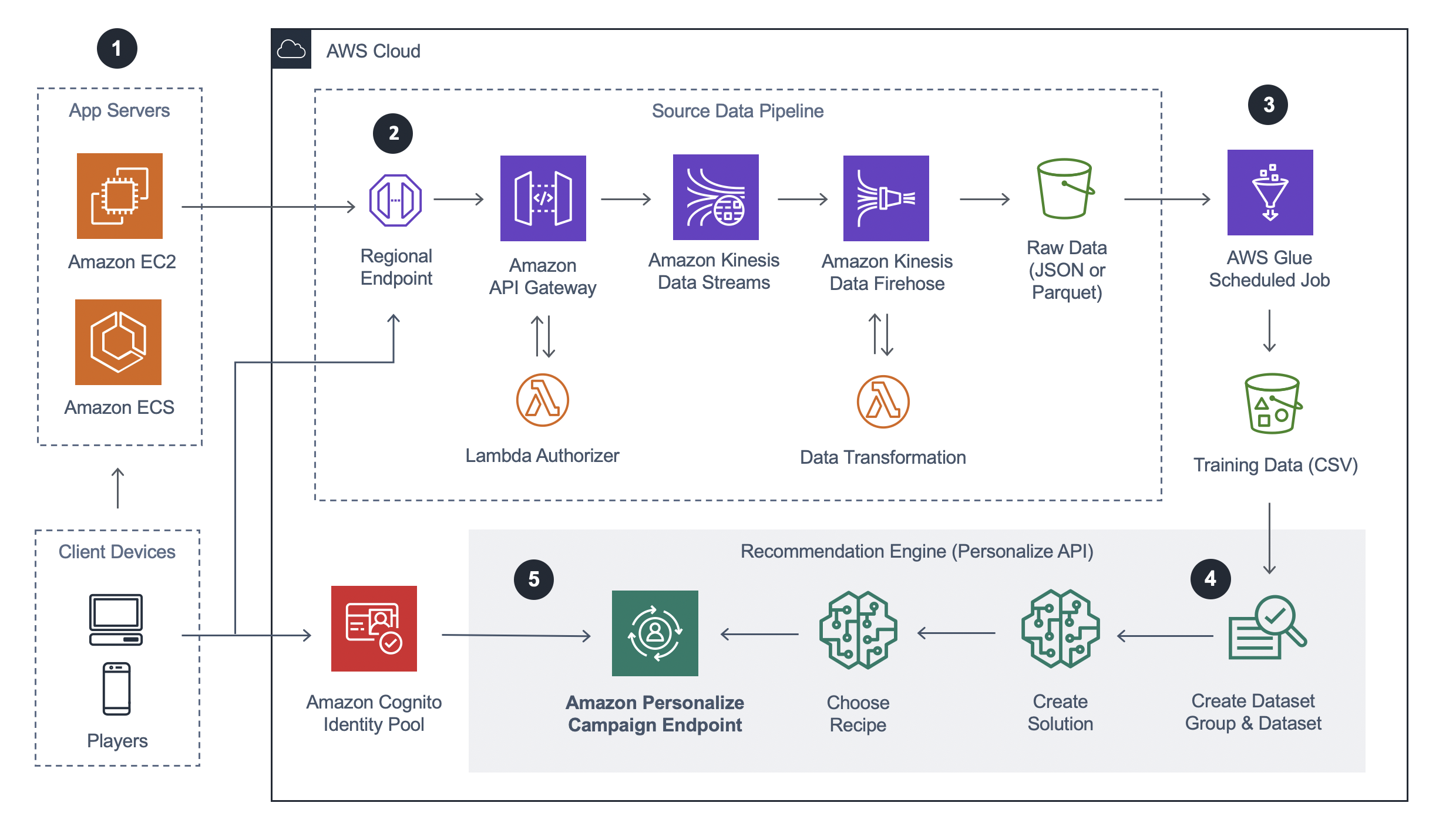
1. Data Producers: In this model, data producers such as app servers or client devices like consoles and mobile phones generate data. When users produce data by making store purchases, completing quests, choosing a game mode, or otherwise “interacting,” they submit records to the AWS Cloud. Often this is done as part of a primary data pipeline.
2. Data Ingestion: Data is sent to the AWS Cloud via REST APIs using Amazon API Gateway and ingested into the Amazon Kinesis Data Streams service. Developers can also use the Amazon Kinesis Data Streams SDKs to PutRecords() directly into their streams. While this blog does not dive into the details of building out a full game analytics pipeline, it is recommended to look at our Game Analytics Pipeline solution, which spins up the necessary infrastructure for developers who do not already have an existing data analytics pipeline in AWS.
3. Scheduled ETL: Amazon Personalize expects data imported as a dataset in .CSV format with a pre-defined schema that conforms to Avro format when not using the event ingestion SDKs. If data is stored as JSON or Parquet in Amazon S3, developers will need to transform it, which can be done using AWS Glue, a fully-managed ETL service, to schedule and execute a job to convert the data into .CSV format for training. This job can additionally remove records that are irrelevant to your recommendation engine for training efficiency. The minimum data requirements to train a model using a .CSV dataset are 1000 records of combined interaction data and 25 unique users with at least 2 interactions each.
4. Recommendation Engine: Once data is prepped, it is time to create a recommendation engine in Amazon Personalize. The recommendation engine can be created manually in the console while initially testing the service, but Amazon Personalize also provides SDKs to interact directly via APIs. Code for automating the recommendation engine steps can be orchestrated via AWS Step Functions and AWS Lambda for a fully serverless workflow. Amazon Personalize supports many languages to interact with the service, including Python, Node.js, Go, C++, and .Net.
-
- Create a dataset group and dataset: Create a dataset group that includes user-item interaction data, user data, or item data datasets.
- Create a solution and choose a recipe: Create a solution and choose a recipe to use as a model for the solution. Interesting recipes to start with for games use cases include:
- aws-user-personalization: Predicts the items that a user will interact with based their interaction history. With automatic exploration, Amazon Personalize automatically tests different item recommendations, learns how users interact with these recommended items, and boosts recommendations for items that drive better engagement and conversion.
- aws-popularity-count: Recommends the most popular item items based on all of your user behavioral data.
- aws-sims: Recommends items similar to a given item based on the co-occurrence of the item in user history in the user-item interaction dataset.
- Create a campaign: Once your solution is created and trained from your data, create a campaign to provision capacity for real-time transactions using your solution which can be referenced for API calls to the service. Note: The solution version ARN (solutionVersionARN) is used to create a campaign. The Solution ARN (solutionARN) is used to create the solution version.
5. Retrieving Recommendations: To retrieve real-time recommendations, a client calls GetRecommendations() and references the Amazon Personalize Campaign ARN as part of the request. The API call used is GetRecommendationsAsync() in the Unity Engine using the .Net SDKs, and similarly for C++ in Unreal Engine. Developers can also make these calls behind a proxy API if they prefer to keep their campaign endpoint separate from any client-side code. GetRecommendations() will return a list of items (technically a GetRecommendationsResponse object) based on the recipe used in the campaign’s solution. Developers can also apply filters during this request to apply business rules to recommendations.
Once a developer has retrieved the recommendations, the developer can use the data to create a variety of experiences: From displaying the most popular virtual goods first, applying graphical badges to the top three items returned, creating a recommended tab unique to that user, or display similar suggested quests and challenges based on the user’s (and other users’) previous interactions to encourage thoughtful avenues of gameplay.
Real-Time Data Ingestion & Recommendations
Some games need data ingested in real time directly to the service to facilitate choices and encourage behaviors without combining their recommendation engine to a larger analytics pipeline. For example, in a multiplayer game where there are multiple heroes to choose from, a developer may want to show the current most popular heroes being selected or encourage play of the least popular heroes with a reward in order to provide a better overall experience for their player base when there is an unbalanced meta. Because Amazon Personalize returns a list of “items,” this list can also include playable characters.
The below architecture pattern facilitates use cases where games need to provide up-to-date statistics that inform their recommendations and rapidly de-prioritize data that has lost value in the current play space. Data can be submitted to Amazon Personalize for real-time data ingestion using either a Personalize server API or they can be sent directly to the Amazon Personalize service from clients using PutEvents() and the developer’s preferred SDKs. The model uses interaction history (sequence of interactions) to recommend relevant items. When real-time events are ingested, the model is aware of these interactions and uses them in its predictions moving forward.
Option 1: Using a Server API
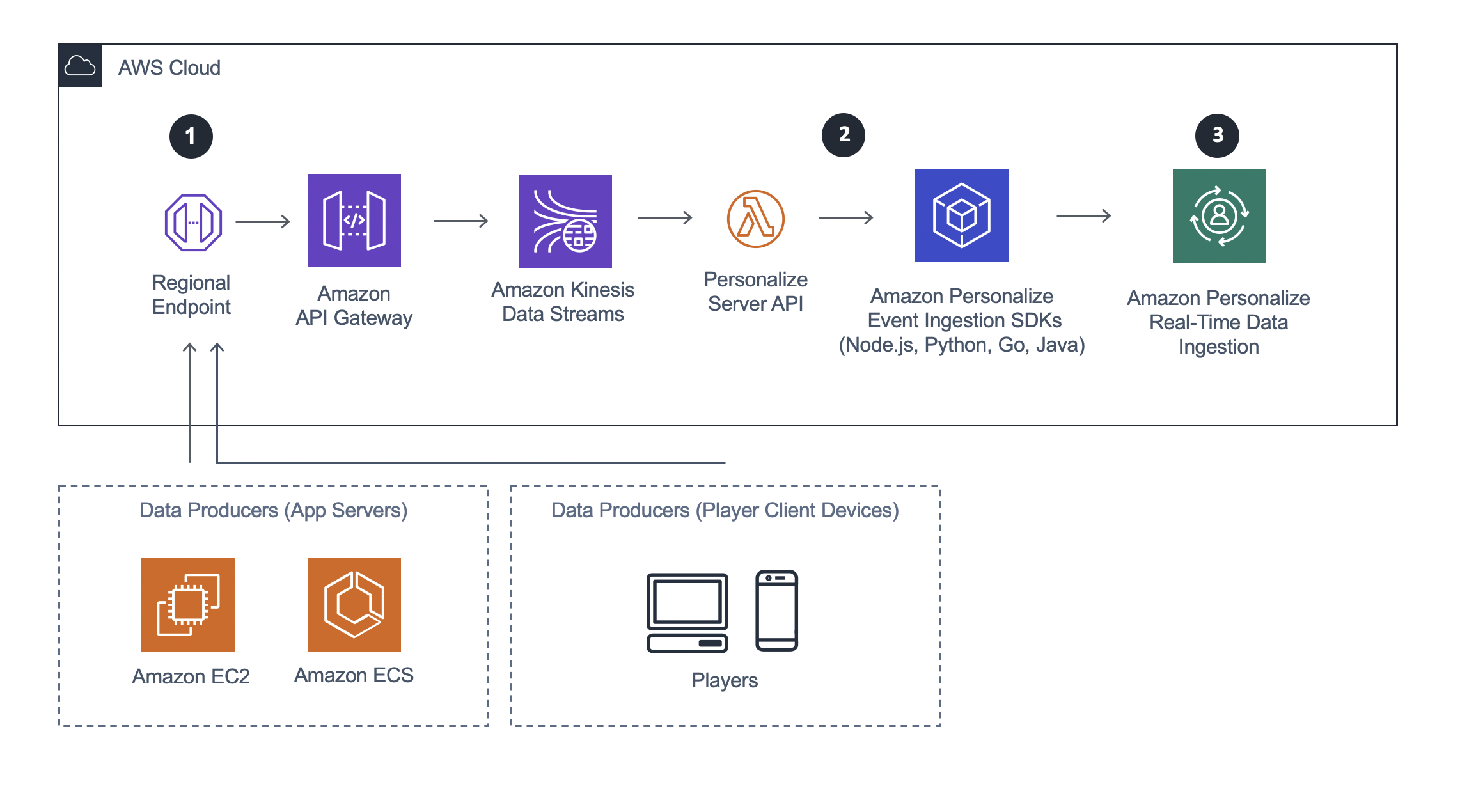
1. Data Pipeline & AWS Lambda: In this architecture, data producers can send events to API Gateway, which can automatically deliver the data to Amazon Kinesis Data Streams. Events can be processed directly from Kinesis in real time using AWS Lambda to take advantage of serverless compute.
2. Event Ingestion: There are three components of ingesting events directly into Amazon Personalize. First, a dataset group that includes a dataset and defined schema; however, the dataset can be empty. Then, an event tracker. An event tracker specifies a destination dataset group for new event data. Finally, the developer calls the PutEvents() API as part of the AWS Lambda function that reads from the stream to begin posting events directly to the service.
3. Real-Time Recommendations: If new items are added to Amazon Personalize using PutEvents(), for example newly released seasonal outfits, and the developer used a user-personalization recipe, Amazon Personalize automatically updates the model every 2 hours. After each update, the new items influence individualized recommendations without additional steps required. The model explores these new items and allows user-interaction data to be collected about the new items. These interactions are used to update how exploration occurs.
Note: For other recipe types, such as popularity-count, developers must create a new solution version for new records to influence recommendations; however, this requires less steps than the previous architecture. When using the event ingestion SDKs, Amazon Personalize automatically stores the recorded events, no scheduled AWS Glue job necessary. The developer only needs to schedule two API calls, using CreateSolutionVersion() to train or retrain an active solution for their campaign endpoint, and then update their campaign to point to the newest version by calling UpdateCampaign(). This makes it easier for developers to automate a response when patches or content updates shift the meta in a multiplayer game on their own terms.
UI changes and recommendations can happen in a matter of a few calls to encourage or discourage behaviors without the time constraints of complex data analysis required by the developer. Developers can find out more about how recorded events influence recommendations here.
Option 2: Client-Side Integration
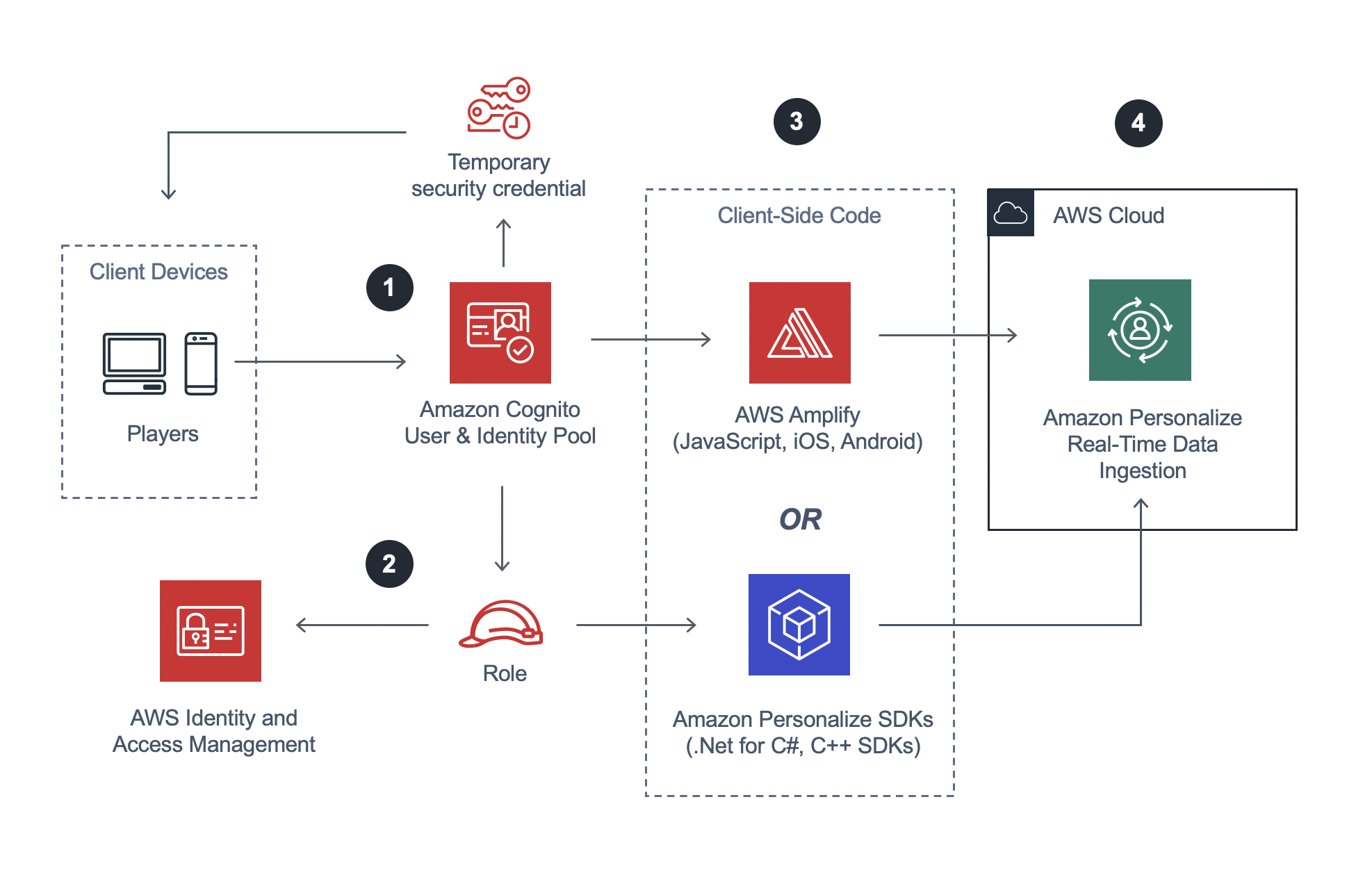
1. API Authentication: When calls are made directly from clients, they need permission to interact with AWS services. Often this is done by allowing clients to assume a role, managed via an identity pool, in Amazon Cognito. If you already have another service that collects user-ids that can be passed as part of a user-interaction dataset, then you only need an identity pool in order to allow anonymous identities to assume a role that can post to the SDKs.
2. Roles in AWS: When a client assumes an identity as part of an identity pool, a role is referenced. Roles are managed in the AWS Identity and Access Management service, or, AWS IAM. This role must have permission to interact with AWS Personalize and should be specified as part of a IAM Policy. See creating a new IAM Policy to allow clients to interact with Personalize. This role should be restricted to only the calls the client needs to make to the service; for example, GetRecommendations() or PutEvents() and not "personalize:*" — which will allow a client to take any action in Personalize.
3. SDK Options: Similar to the server API architecture, clients can also call SDKs. If developing natively for iOS or Android, consider AWS Amplify, which includes code samples and can greatly reduce friction and time to development. Amplify includes other features beyond Personalize. If just integrating with Amazon Personalize and working in the Unity game engine, then use the Amazon Personalize SDKs for .Net / C# NuGet packages and for the Unreal Engine, use the C++ SDKs.
4. PutEvents: In order for clients to call PutEvents() to submit fresh events directly to Amazon Personalize to use in training, developers using the latest versions of Unity should call PutEventsAsync() using the .Net SDK and developers using Unreal should call PutEventsAsync() using the C++ SDK.
There is no preferred method between calling the services from the client versus behind a proxy API. Calling from the client hits a regional AWS endpoint to the service.; however, hosting a proxy API such as with API Gateway and Lambda allows developers more control over their endpoints and gives them the ability to abstract their backend implementation while adding increased security monitoring, such as AWS WAF, to their API. Developers must weigh the pros and cons of cost, security, and development time when implementing their recommendation engine.
Best Practices for Games
Amazon Personalize is a powerful tool in the hands of developers looking to build and host a recommendation engine without wanting to write models from scratch or setup complex training infrastructure. It does not require machine learning expertise and can be integrated with flexibility for game and technical design requirements. It is especially useful for developers who are comfortable working with API calls and have an ideal use case that provides recommended “items” as results returned from the service. On the backend, Personalize also makes available additional features, such as filters and variables for each model, once a developer is more comfortable with the service while still providing a starting point for those newer to AI/ML.
Developers new to Amazon Personalize should experiment with their Avro schemas and one or two use cases to test with the performance in their game. It is recommended to be thoughtful about hitting the campaign endpoint as a point of cost optimization and performance with games. For example, many games do not need to call GetRecommendations() every time a store loads, but only when the game loads and can store the results during the session.
To get started head on over to Amazon Personalize in the console and check out this blog that includes a walkthrough how to create an interaction dataset. To dive deeper, check out the full Amazon Personalize workshop or contact your AWS team to enable your next project.