AWS HPC Blog
Avoid overspending with AWS Batch using a serverless cost guardian monitoring architecture
Pay-as-you-go resources are a compelling but daunting concept for budget conscious research customers. Uncertainty of cloud costs is a barrier-to-entry for most, and having near real-time cost visibility is critical. This is true for research businesses, including non-profits, K-12, and higher-education institutions who are grant-funded and have a limited budget. Grants are painstaking to write and apply for, so cost overruns represent a significant risk to research being done in the cloud.
More research customers now leverage managed compute services beyond just Amazon Elastic Compute Cloud (Amazon EC2) for experimentation in the cloud (e.g. AWS Batch, Amazon Elastic Container Service (Amazon ECS), AWS Fargate). These services enable the type of rapid scalability researchers need for high performance compute (HPC) workloads. However, this scalability can be a double-edged sword in regards to budget planning. Experimental research is unpredictable in nature primarily because it is not steady-state. HPC workloads are typically burstable and sometimes long running, which makes it harder to predict their costs.
In this blog, we introduce a novel architecture to manage the costs of your cloud workloads, leveraging low-cost, serverless technology that is capable of polling costs in near-real time and terminating resources before overspending. This solution is developed for use with AWS Batch, and it currently supports the Fargate deployment model. However, it is open-sourced on GitHub for future extensibility. This architecture relies on AWS Cloud Financial Management solutions as the primary mechanism for cost analysis, and complements them with the added feature of near real-time visibility.
Billing Updates and Frequency
There are a number of AWS Cloud Financial Management solutions to provide cost transparency. This architecture leverages several tools:
- The AWS Cost and Usage Report (CUR) tracks your AWS usage and breaks down your costs by providing estimated charges associated with your account. Each report contains line items for your AWS products, usage type, and operation used in your account. You can customize the AWS CUR to aggregate information by hour, day or month. The AWS CUR publishes AWS billing reports to an Amazon Simple Storage Service (Amazon S3) bucket you own.
- AWS Cost Explorer is a tool that helps manage your AWS costs by giving detailed insights into the line items of your bill. Cost Explorer visualizes daily, monthly, and forecasted spend by combining an array of available filters. Filters allow you to narrow down costs according to AWS service type, linked accounts, and tags.
- AWS Budgets lets you set custom budgets to track your costs from the simplest to the most complex use cases. AWS Budgets supports email or SNS notification when actual or forecasted costs exceed your budget threshold.
These tools are great for retrospective cost analysis, but they do not update in real-time. They can update up to three times a day, or 8-12 hours of granularity. Meaning, if you set an alert for a limit you have passed, the notification may be delayed for half-a-day until the next billing cycle update. This lack of real-time cost data is a barrier to entry for grant-funded research customers that want to leverage AWS.
Solution Overview
This solution is scoped to focus on AWS Batch on AWS Fargate usage for research customers. The architecture leverages low-cost, serverless technology to monitor and manage long-running, experimental compute found in research. Event-driven processes will be kicked off to monitor and terminate managed-compute spend before it goes over budget. This solution is meant to be an enhancement of AWS cost tools with high-frequency polling utilizing serverless compute/storage options.
Additionally, this solution provides a blueprint for similar high-frequency cost tracking monitoring since pricing variables can be swapped out via the AWS Price List API and what resources are being tracked via cost allocation tags.
The following diagram illustrates the solution architecture.
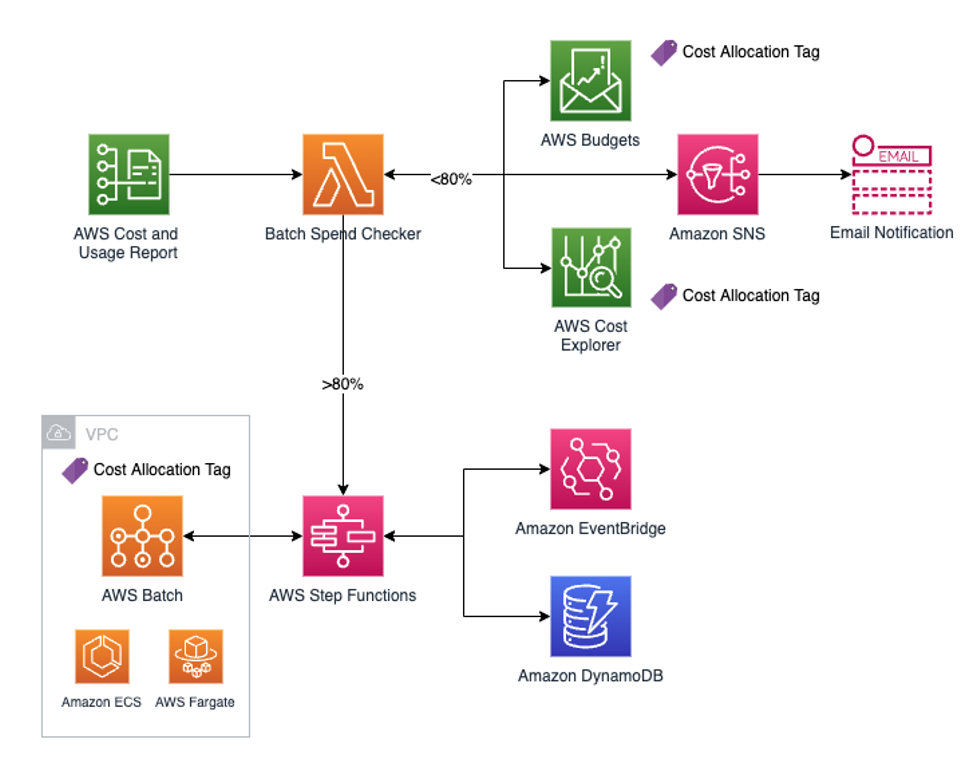
Figure 1: Monitoring Solution Architecture for AWS Batch on AWS Fargate
The solution showcases an AWS Batch on AWS Fargate environment where researchers are sending compute jobs. The Batch Fargate environment has a cost allocation tag for AWS Budgets and Cost Explorer to track its cost.
The architecture begins with the ingestion of the AWS CUR, which lets us know that the most up-to-date billing data is available. The CUR is sent to an S3 bucket, which triggers an AWS Lambda function we named the Batch Spend Checker. Once this Lambda function is triggered, it will perform two actions:
- Check allocated budget and current spend in AWS Budgets
- Run a customized AWS Cost Explorer query to verify budget spend
If both checks return a budget spend less than a configurable threshold, say 80%, Amazon Simple Notification Service (SNS) will send an email notification stating how much is spent as well as how much spend is left according to AWS Budgets and Cost Explorer.
If either of the checks comes back greater than the configurable threshold, e.g. 80%, the architecture will kick off a AWS Step Functions workflow. Step Functions will orchestrate the stopping of new batch jobs from entering and keeping a running cost tally based on a near real-time, configurable, polling frequency. Users can set the polling frequency to be as short as a few seconds, but should ultimately set it to be anything less than 6 hours. This ensures a greater granularity than the existing AWS Cloud Financial Management solutions.
The Step Functions workflow leverages Amazon DynamoDB tables as a data store for both the currently running, indivdual Batch jobs and aggregated job data. In parallel, Amazon EventBridge kicks off an event-driven process that will delete individual Batch jobs that have completed from the DynamoDB table. Another Lambda function will keep a running cost tally in the aggregate job DynamoDB table. Once the AWS Budgets threshold has been reached, the Step Functions workflow will query the currently running, individual Batch jobs from DynamoDB and then stop them to avoid incurring further costs.
AWS Step Functions and Event-Driven Workflow
Here is a more detailed view of the architecture once the 80% threshold is broken. The figure illustrates the Step Functions workflow along with the event-driven parallel process.
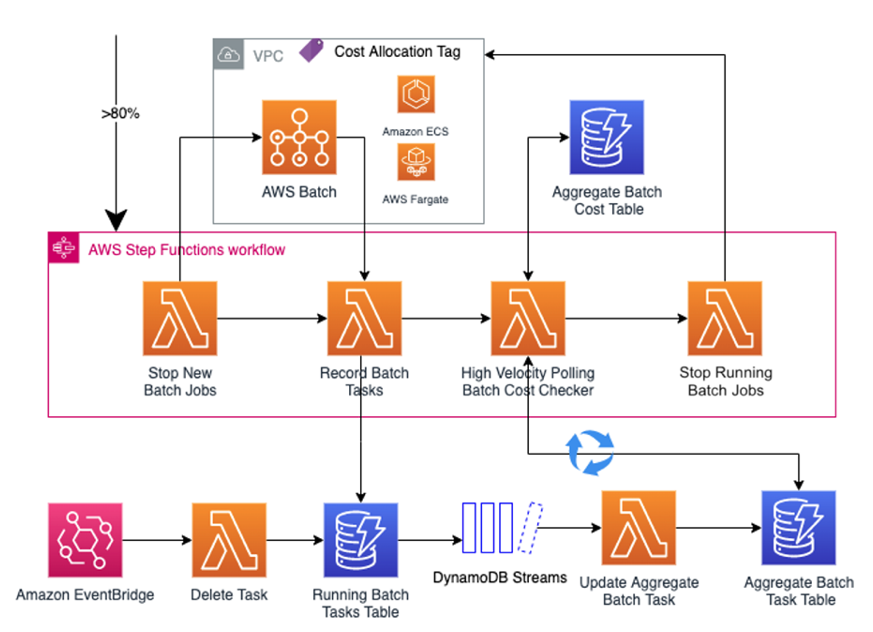
Figure 2: Step Functions state machine & event-driven architecture breakout
The Step Functions workflow steps are as follows:
- After receiving the >80% spend trigger from Batch Spend Checker, the state machine is executed.
- The workflow immediately invokes Stop New Batch Jobs to stop adding new batch jobs to the queue because the budget threshold is almost met.
- Record Batch Tasks will record currently running Batch jobs in the Running Batch Tasks DynamoDB table. This is done once, but is kept up-to-date via the event-driven processes.
- The High Velocity Polling Batch Cost Checker is continuously invoked to poll the Aggregate Batch Task DynamoDB table and update the running cost of the existing batch jobs.
- Lastly, once the budget threshold is 100% met, the Stop Running Batch Jobs will terminate all remaining Batch jobs..
In parallel, these event-driven processes run in the background:
- If one of the currently running batch job finishes, EventBridge will invoke the Delete Task Lambda function to delete the finished batch job from Running Batch Tasks DynamoDB table.
- DynamoDB Streams captures any changes from the Running Batch Tasks DynamoDB table and invokes Update Aggregate Batch Task to aggregate the vCPU and memory of all the currently running Batch jobs and update the Aggregate Batch Task DynamoDB table.
Prerequisites
Before getting started, you must have the following prerequisites:
- An AWS Account
- Have the AWS Cloud Development Kit (AWS CDK) and Python installed (Python 3.6+) on a local machine or cloud IDE of your choice.
- Create an AWS CUR along with accompanying S3 bucket. Follow instructions here. (NOTE: this can take up to 24 hours to create).
- Set the report path prefix as “reports”
- Set granularity to “Hourly”
- Set report versioning to “create new report version”
Deploy the Solution
To deploy the solution using the CDK, complete the following steps to bootstrap your environment:
- Clone the repository
- The cdk.json tells the CDK how to execute your app. This project is set up like a standard Python project. Initialization creates a virtual environment and stored under the .venv directory. To create the virtual environment, the CDK assumes that python3 is executable in your path.
- To manually create a virtual environment on MacOS/Linux:
python3 -m venv .venv
- Activate your virtual environment
source .venv/bin/activate
- Install required dependencies
pip install -r requirements.txt
- Synthesize CloudFormation template
cdk synth
- To manually create a virtual environment on MacOS/Linux:
Sample Batch Environment
If you are already using AWS Batch, identify a Fargate compute environment to monitor.
Otherwise, deploy a test Batch environment via the “sample-batch-env” CDK stack provided in the repository.
$ cdk deploy sample-batch-env-batch-stack Run a quick “hello-world” job via the provided job definition. This triggers the creation of an AWS-Generated Cost Allocation Tag for the Batch Fargate compute environment. In AWS Billing, activate the following AWS-Generated Cost Allocation Tags (NOTE: if not present, wait 24 hours for tags to appear after running the “hello-world” job)
- aws:batch:compute-environment
- aws:batch:job-definition
- aws:batch:job-queue
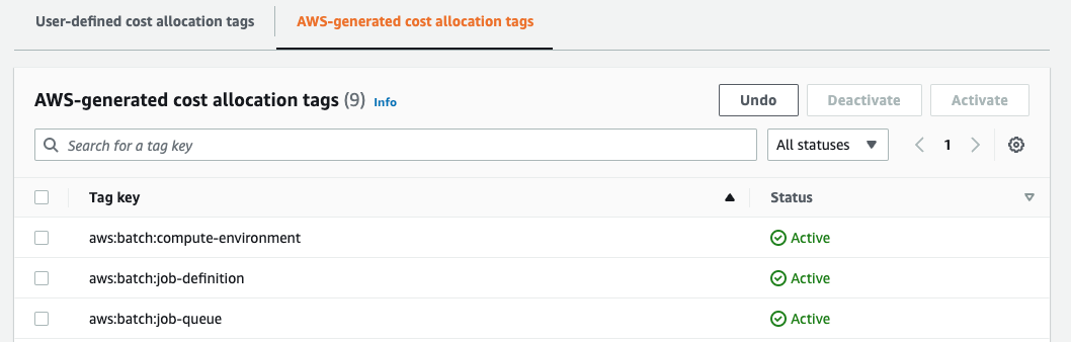
Figure 3: Viewing AWS-generated cost allocation tags in the Billing Console
Finally, create the AWS Budget to be used by the Event-Driven Budget Checker CDK stack. Follow these instructions to create a cost budget. Make sure to select Cost budget, and keep default settings. Name the budget appropriately and set an amount. Afterwards, select the “Filter specific AWS cost dimensions” under Budget Scope. Under Filters, select Tag from the Dimension dropdown. Under the Tag dropdown, choose the “aws:batch:compute-environment”. (NOTE: if tag isn’t appearing, submit another “hello-world” job and wait an additional 24 hours) This will give the tag time to propagate and appear on CUR report. Once the tag appears, under the Values dropdown, select the name of the Batch Fargate compute environment.
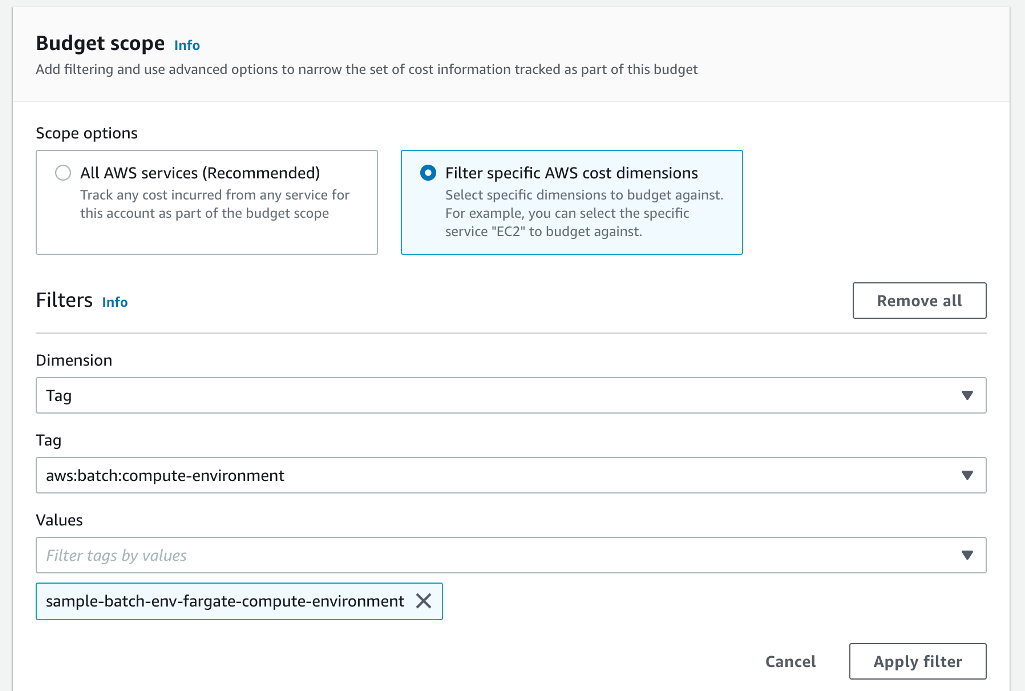
Figure 4: Creating a cost Budget with a tag filter in the Console
Event-Driven Budget Checker
Run the following command to deploy the Event-Driven Budget Checker with your specific parameters. Obtain the “budgetName”, “batchComputeEnvName”, and “s3CurBucketName” from the previous steps. The “desiredBudgetThresholdPercent” is entered as a numerical percent, e.g. 50. Based on how aggressive you would like to be in preventing Batch overspend, you can set the threshold lower. Leave “costGuardianStateMachineArn” blank. We will return back to this parameter after running the Serverless Batch Cost Guardian CDK stack.
cdk deploy event-driven-budget-checker-budget-stack \
--parameters snsEmail=<YOUR-EMAIL> \
--parameters accountId=<YOUR-AWS-ACCOUNT-ID> \
--parameters budgetName=<NAME-OF-AWS-BUDGET> \
--parameters batchComputeEnvName=<NAME-OF-BATCH-COMPUTE-ENVIRONMENT> \
--parameters costGuardianStateMachineArn=<LEAVE-BLANK-FILL-IN-LATER> \
--parameters desiredBudgetThresholdPercent=<DESIRED-BUDGET-THRESHOLD-PERCENTAGE> \
--parameters s3CurBucketName=<S3-BUCKET-NAME-COST-AND-USAGE-REPORT>
Serverless Batch Cost Guardian
Run the following command to deploy the Serverless Batch Cost Guardian with your specific parameters.
cdk deploy serverless-batch-cost-guardian-guardian-stack \
--parameters batchComputeEnvName=<NAME-OF-BATCH-COMPUTE-ENVIRONMENT> \
--parameters batchJobQueueName=<NAME-OF-BATCH-JOB-QUEUE> \
--parameters ecsClusterArn=<ARN-OF-BATCH-COMPUTE-ENV-ECS-CLUSTER> \
--parameters waitTime=<TIME-BETWEEN-CHECKS-IN-SECONDS>
Obtain the “batchComputeEnvName” and “batchJobQueueName” from the previous steps. The “waitTime” parameter is any number of your choosing. This integer will be in seconds.
The “ecsClusterArn” is obtained by selecting the Batch compute environment in the AWS Batch console. (NOTE: Copy the ARN, starting with “arn:xxx”, not the hyperlink to the ECS cluster page beginning with “https:xxx”.) If you are using the “sample-batch-env” CDK stack, the ARN is output for you in the command line, as well.
Figure 5: Obtain the ECS cluster ARN from the Batch compute environment details in the Console
After deploying the Serverless Batch Cost Guardian, go to the newly created Step Functions State Machine and copy its ARN.
Re-run the following CDK deploy command, creating a linkage between the Event-Driven Budget Checker and the Serverless Batch Cost Guardian.
cdk deploy event-driven-budget-checker-budget-stack \
--parameters costGuardianStateMachineArn=<ARN-OF-STEP-FUNCTIONS-STATE-MACHINE>
The above command will not re-deploy the Event-Driven Budget Checker, but instead performs a CloudFormation ChangeSet operation to update the Event-Driven Budget Checker Lambda environment variable with the Serverless Batch Cost Guardian Step Functions ARN.
Test the Solution
Having deployed the stacks above, the solution is fully-operational. However, to see it in action immediately, you can manually trigger the Lambda function instead of waiting for a CUR to trigger an S3 Lambda event.
First, temporarily update your AWS Budget amount to a small value (e.g. $0.01) so you are not waiting long. If the “waitTime” parameter you specified earlier is longer than a few seconds, we recommend updating that to be small, too (e.g. 5 seconds). (NOTE: You can run cdk deploy serverless-batch-cost-guardian-guardian-stack --parameters waitTime=5 to perform a ChangeSet operation.)
After updating these two values, submit a Batch job to your monitored Batch compute environment’s job queue. You can submit multiple jobs to see the aggregated metrics (vCPU and memory) tracked. Leverage the job definition provided in the Sample Batch Environment stack to submit a simple testing job. To do so, go to the job definition in the AWS Batch console. Click “Submit New Job” on the top right of the page. After naming the job and choosing the appropriate job queue from the dropdown, please enter the following bash command under Job configuration: sleep 10000. Make note of the vCPU and memory; the defaults of 1 vCPU and 2 GB are fine. Click submit. (Clone this job to see multiple).
Trigger the Event-Driven Budget Checker Lambda function. Go to the AWS Lambda console and find the function with “monthtodatebatchspend” in the name.

Figure 6: Trigger the Event-Driven Budget Checker from the AWS Lambda console
Click it, and press the “Test” button. The default test event is fine. The test event will simulate an S3 Lambda event triggered by a CUR creation in your account. The Lambda function invocation will trigger the “serverlessbatchcostguardianstatemachine”.
Go to the Step Functions console and click on this state machine. You should see an execution of the state machine in the Running state. Click to see the workflow in action.
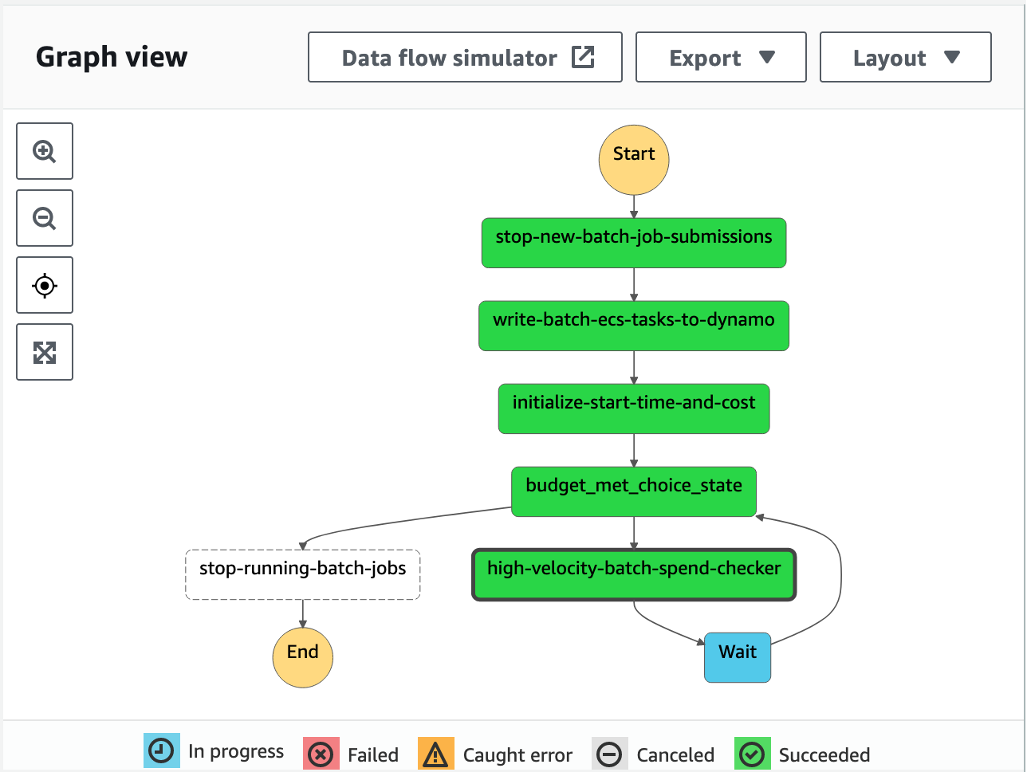
Figure 7: Graph view of the Serverless Batch Cost Guardian state machine in the Step Functions Console
Finally, go to the DynamoDB console. Query the latesttimestamprunningcosttable and refresh the page to see the running costs updating in near real-time..

Figure 8: Query the singular item in the Latest Running Cost DynamoDB for running cost in near real-time
Cleanup
- To reset the solution, you will need to:
- Re-enable the Batch compute environment and Batch job queue. Part of the Serverless Batch Cost Guardian Step Function workflow was to disable them from accepting new jobs. Re-enable accepting new batch jobs by pressing “Enable” at the top right of the AWS Batch console.
- Delete the DynamoDB metric and cost tracking items from the previous cycle. For the three DynamoDB tables with “serverless-batch-cost-guardian-guardian-stack”, delete the items.
- Restore your original AWS Budgets value. Failure to do so will erroneously trigger the Step Functions workflow excessively.
- OPTIONAL: To delete all resources created in this blog the (minus the prerequisites, such as the S3 Cost and Usage Report bucket), you can do so by running
cdk destroy <STACK NAME>for each of the stacks we deployed.
Conclusion
In this blog post, we introduced a novel architecture to manage the costs of your cloud workloads in near real-time. While the solution focuses on AWS Batch on AWS Fargate, customers can take the lessons learned here to monitor other services they are using. Ultimately, the serverless architecture, coupled with the AWS cost management services, such as Budgets and Cost Explorer, will empower research customers to experiment safely in the cloud.