Artificial Intelligence
Achieve low-latency hosting for decision tree-based ML models on NVIDIA Triton Inference Server on Amazon SageMaker
Machine learning (ML) model deployments can have very demanding performance and latency requirements for businesses today. Use cases such as fraud detection and ad placement are examples where milliseconds matter and are critical to business success. Strict service level agreements (SLAs) need to be met, and a typical request may require multiple steps such as preprocessing, data transformation, model selection logic, model aggregation, and postprocessing. At scale, this often means maintaining a huge volume of traffic while maintaining low latency. Common design patterns include serial inference pipelines, ensembles (scatter-gather), and business logic workflows, which result in realizing the entire workflow of the request as a Directed Acyclic Graph (DAG). However, as workflows get more complex, this can lead to an increase in overall response times, which in turn can negatively impact the end-user experience and jeopardize business goals. Triton can address these use cases where multiple models are composed in a pipeline with input and output tensors connected between them, helping you address these workloads.
As you evaluate your goals in relation to ML model inference, many options can be considered, but few are as capable and proven as Amazon SageMaker with Triton Inference Server. SageMaker with Triton Inference Server has been a popular choice for many customers because it’s purpose-built to maximize throughput and hardware utilization with ultra-low (single-digit milliseconds) inference latency. It has wide range of supported ML frameworks (including TensorFlow, PyTorch, ONNX, XGBoost, and NVIDIA TensorRT) and infrastructure backends, including NVIDIA GPUs, CPUs, and AWS Inferentia. Additionally, Triton Inference Server is integrated with SageMaker, a fully managed end-to-end ML service, providing real-time inference options for model hosting.
In this post, we walk through deploying a fraud detection ensemble workload to SageMaker with Triton Inference Server.
Solution overview
It’s essential for any project to have a list of requirements and an effort estimation, in order to approximate the total cost of the project. It’s important to estimate the return on investment (ROI) that supports the decision of an organization. Some considerations to take account when moving a workload to Triton include:
- Costs – The engineering effort to experiment, code, and test with existing ML models maintained by the company, in order to migrate ML model inferences to SageMaker with Triton Inference Server
- Benefits – Your organization may aim to reduce the latency from tens of milliseconds to single-digit milliseconds for 99% of the traffic for your workload, for example, because it has learned from internal reports that the conversion rate drops 1% with every 100 milliseconds of latency
Effort estimation is key in software development, and its measurement is often based on incomplete, uncertain, and noisy inputs. ML workloads are no different. Multiple factors will affect an architecture for ML inference, some of which include:
- Client-side latency budget – It specifies the client-side round-trip maximum acceptable waiting time for an inference response, commonly expressed in percentiles. For workloads that require a latency budget near tens of milliseconds, network transfers could become expensive, so using models at the edge would be a better fit.
- Data payload distribution size – Payload, often referred to as message body, is the request data transmitted from the client to the model, as well as the response data transmitted from the model to the client. The payload size often has a major impact on latency and should be taken into consideration.
- Data format – This specifies how the payload is sent to the ML model. Format can be human-readable, such as JSON and CSV, however there are also binary formats, which are often compressed and smaller in size. This is a trade-off between compression overhead and transfer size, meaning that CPU cycles and latency is added to compress or decompress, in order to save bytes transferred over the network. This post shows how to utilize both JSON and binary formats.
- Software stack and components required – A stack is a collection of components that operate together to support an ML application, including operating system, runtimes, and software layers. Triton comes with built-in popular ML frameworks, called backends, such as ONNX, TensorFlow, FIL, OpenVINO, native Python, and others. You can also author a custom backend for your own homegrown components. This post goes over an XGBoost model and data preprocessing, which we migrate to the NVIDIA provided FIL and Python Triton backends, respectively.
All these factors should play a vital part in evaluating how your workloads perform, but in this use case we focus on the work needed to move your ML models to be hosted in SageMaker with Triton Inference Server. Specifically, we use an example of a fraud detection ensemble composed of an XGBoost model with preprocessing logic written in Python.
NVIDIA Triton Inference Server
Triton Inference Server has been designed from the ground up to enable teams to deploy, run, and scale trained AI models from any framework on GPU or CPU based infrastructure. In addition, it has been optimized to offer high-performance inference at scale with features like dynamic batching, concurrent runs, optimal model configuration, model ensemble, and support for streaming inputs.
The following diagram shows an example NVIDIA Triton ensemble pipeline.
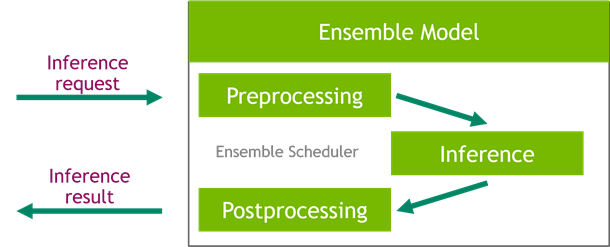
Workloads should take into account the capabilities that Triton provides along with SageMaker hosting to maximize the benefits offered. For example, Triton supports HTTP as well as a C API, which allow for flexibility as well as payload optimization when needed. As previously mentioned, Triton supports several popular frameworks out of the box, including TensorFlow, PyTorch, ONNX, XGBoost, and NVIDIA TensorRT. These frameworks are supported through Triton backends, and in the rare event that a backend doesn’t support your use case, Triton allows you to implement your own and integrate it easily.
The following diagram shows an example of the NVIDIA Triton architecture.
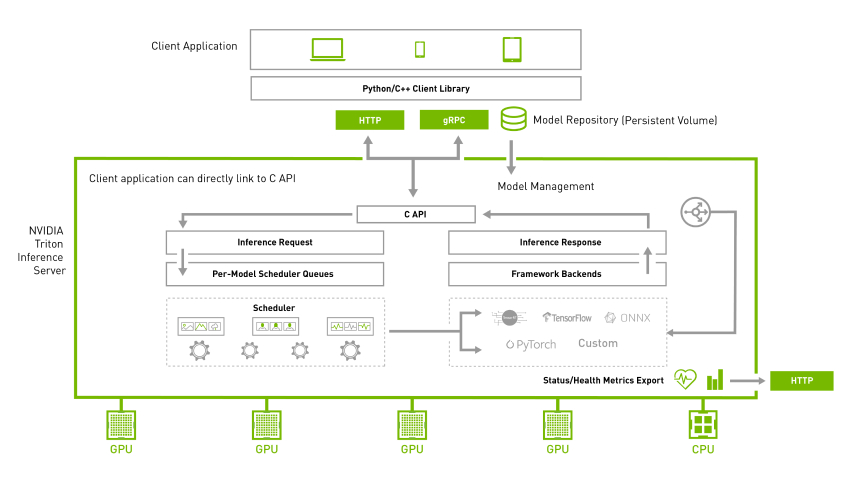
NVIDIA Triton on SageMaker
SageMaker hosting services are the set of SageMaker features aimed at making model deployment and serving easier. It provides a variety of options to easily deploy, auto scale, monitor, and optimize ML models tailored for different use cases. This means that you can optimize your deployments for all types of usage patterns, from persistent and always available with serverless options, to transient, long-running, or batch inference needs.
Under the SageMaker hosting umbrella is also the set of SageMaker inference Deep Learning Containers (DLCs), which come prepackaged with the appropriate model server software for their corresponding supported ML framework. This enables you to achieve high inference performance with no model server setup, which is often the most complex technical aspect of model deployment and in general isn’t part of a data scientist’s skill set. Triton inference server is now available on SageMaker DLCs.
This breadth of options, modularity, and ease of use of different serving frameworks makes SageMaker and Triton a powerful match.
NVIDIA FIL backend support
With the 22.05 version release of Triton, NVIDIA now supports forest models trained by several popular ML frameworks, including XGBoost, LightGBM, Scikit-learn, and cuML. When using the FIL backend for Triton, you should ensure that the model artifacts that you provide are supported. For example, FIL supports model_type xgboost, xgboost_json, lightgbm, or treelite_checkpoint, indicating whether the provided model is in XGBoost binary format, XGBoost JSON format, LightGBM text format, or Treelite binary format, respectively.
This backend support is essential for us to use in our example because FIL supports XGBoost models. The only consideration to check is to ensure that the model that we deploy supports binary or JSON formats.
In addition to ensuring that you have the proper model format, other considerations should be taken. The FIL backend for Triton provides configurable options for developers to tune their workloads and optimize model run performance. The configuration dynamic_batching allows Triton to hold client-side requests and batch them on the server side, in order to efficiently use FIL’s parallel computation to inference the entire batch together. The option max_queue_delay_microseconds offers a fail-safe control of how long Triton waits to form a batch. FIL comes with Shapley explainer, which can be activated by the configuration treeshap_output; however, you should keep in mind that Shapley outputs hurt performance due to its output size. Another important aspect is storage_type in order to trade-off between memory footprint and runtime. For example, using storage as SPARSE can reduce the memory consumption, whereas DENSE can reduce your model run performance at the expense of higher memory usage. Deciding the best choice for each of these depends on your workload and your latency budget, so we recommend a deeper look into all options in the FIL backend FAQ and the list of configurations available in FIL.
Steps to host a model on triton
Let’s look at our fraud detection use case as an example of what to consider when moving a workload to Triton.
Identify your workload
In this use case, we have a fraud detection model used during the checkout process of a retail customer. The inference pipeline is using an XGBoost algorithm with preprocessing logic that includes data preparation for preprocessing.
Identify current and target performance metrics and other goals that may apply
You may find that your end-to-end inference time is taking too long to be acceptable. Your goal could be to go from tens of milliseconds of latency to single-digit latency for the same volume of requests and respective throughput. You determine that the bulk of the time is consumed by data preprocessing and the XGBoost model. Other factors such as network and payload size play a minimal role in the overhead associated with the end-to-end inference time.
Work backward to determine if Triton can host your workload based on your requirements
To determine if Triton can meet your requirements, you want to pay attention to two main areas of concern. The first is to ensure that Triton can serve with an acceptable front end option such as HTTP or C API.
As mentioned previously, it’s also critical to determine if Triton supports a backend that can serve your artifacts. Triton supports a number of backends that are tailor-made to support various frameworks like PyTorch and TensorFlow. Check to ensure that your models are supported and that you have the proper model format that Triton expects. To do this, first check to see what model formats the Triton backend supports. In many cases, this doesn’t require any changes for the model. In other cases, your model may require transformation to a different format. Depending on the source and target format, various options exist, such as transforming a Python pickle file to use Treelite’s binary checkpoint format.
For this use case, we determine the FIL backend can support the XGBoost model with no changes needed and that we can use the Python backend for the preprocessing. With the ensemble feature of Triton, you can further optimize your workload by avoiding costly network calls between hosting instances.
Create a plan and estimate the effort required to use Triton for hosting
Let’s talk about the plan to move your models to Triton. Every Triton deployment requires the following:
- Model artifacts required by Triton backends
- Triton configuration files
- A model repository folder with the proper structure
We show an example of how to create these deployment dependencies later in this post.
Run the plan and validate the results
After you create the required files and artifacts in the properly structured model repository, you need to tune your deployment and test it to validate that you have now hit your target metrics.
At this point, you can use SageMaker Inference Recommender to determine what endpoint instance type is best for you based upon your requirements. In addition, Triton provides tools to make build optimizations to get better performance.
Implementation
Now let’s look at the implementation details. For this we have prepared two notebooks that provide an example of what can be expected. The first notebook shows the training of the given XGBoost model as well as the preprocessing logic that is used for both training and inference time. The second notebook shows how we prepare the artifacts needed for deployment on Triton.
The first notebook shows an existing notebook your organization has that uses the RAPIDS suite of libraries and the RAPIDS Conda kernel. This instance runs on a G4DN instance type provided by AWS, which is GPU accelerated by using NVIDIA T4 processors.

Preprocessing tasks in this example benefit from GPU acceleration and heavily use the cuML and cuDF libraries. An example of this is in the following code, where we show categorical label encoding using cuML. We also generate a label_encoders.pkl file that we can use to serialize the encoders and use them for preprocessing during inference time.

The first notebook concludes by training our XGBoost model and saving the artifacts accordingly.


In this scenario, the training code already existed and no changes are needed for the model at training time. Additionally, although we used GPU acceleration for preprocessing during training, we plan to use CPUs for preprocessing at inference time. We explain more later in the post.
Let’s now move on to the second notebook and recall what we need for a successful Triton deployment.
First, we need the model artifacts required by backends. The files that we need to create for this ensemble include:
- Preprocessing artifacts (
model.py,label_encoders.pkl) - XGBoost model artifacts (
xgboost.json)
The Python backend in Triton requires us to use a Conda environment as a dependency. In this case, we use the Python backend to preprocess the raw data before feeding it into the XGBoost model being run in the FIL backend. Even though we originally used RAPIDS cuDF and cuML libraries to do the data preprocessing (as referenced earlier using our GPU), here we use Pandas and Scikit-learn as preprocessing dependencies for inference time (using our CPU). We do this for three reasons:
- To show how to create a Conda environment for your dependencies and how to package it in the format expected by Triton’s Python backend.
- By showing the preprocessing model running in the Python backend on the CPU while the XGBoost model runs on the GPU in the FIL backend, we illustrate how each model in Triton’s ensemble pipeline can run on a different framework backend, and run on different hardware with different configurations.
- It highlights how the RAPIDS libraries (cuDF, cuML) are compatible with their CPU counterparts (Pandas, Scikit-learn). This way, we can show how
LabelEncoderscreated in cuML can be used in Scikit-learn and vice-versa. Note that if you expect to preprocess large amounts of tabular data during inference time, you can still use RAPIDS to GPU-accelerate it.
Recall that we created the label_encoders.pkl file in the first notebook. There’s nothing more to do for category encoding other than include it in our model.py file for preprocessing.

To create the model.py file required by the Triton Python backend, we adhere to the formatting required by the backend and include our Python logic to process the incoming tensor and use the label encoder referenced earlier. You can review the file used for preprocessing.
For the XGBoost model, nothing more needs to be done. We trained the model in the first notebook and Triton’s FIL backend requires no additional effort for XGBoost models.
Next, we need the Triton configuration files. Each model in the Triton ensemble requires a config.pbtxt file. In addition, we also create a config.pbtxt file for the ensemble as a whole. These files allow Triton to know metadata about the ensemble with information such as the inputs and outputs we expect as well as help defining the DAG associated with the ensemble.
Lastly, to deploy a model on Triton, we need our model repository folder to have the proper folder structure. Triton has specific requirements for model repository layout. Within the top-level model repository directory, each model has its own sub-directory containing the information for the corresponding model. Each model directory in Triton must have at least one numeric sub-directory representing a version of the model. For our use case, the resulting structure should look like the following.

After we have these three prerequisites, we create a compressed file as packaging for deployment and upload it to Amazon Simple Storage Service (Amazon S3).

We can now create a SageMaker model from the model repository we uploaded to Amazon S3 in the previous step.
In this step, we also provide the additional environment variable SAGEMAKER_TRITON_DEFAULT_MODEL_NAME, which specifies the name of the model to be loaded by Triton. The value of this key should match the folder name in the model package uploaded to Amazon S3. This variable is optional in the case of a single model. In the case of ensemble models, this key has to be specified for Triton to start up in SageMaker.
Additionally, you can set SAGEMAKER_TRITON_BUFFER_MANAGER_THREAD_COUNT and SAGEMAKER_TRITON_THREAD_COUNT for optimizing the thread counts. Both configuration values help tune the number of threads that are running on your CPUs, so you can possibly gain better utilization by increasing these values for CPUs with a greater number of cores. In the majority of cases, the default values often work well, but it may be worth experimenting see if further efficiency can be gained for your workloads.

With the preceding model, we create an endpoint configuration where we can specify the type and number of instances we want in the endpoint.

Lastly, we use the preceding endpoint configuration to create a new SageMaker endpoint and wait for the deployment to finish. The status changes to InService after the deployment is successful.

That’s it! Your endpoint is now ready for testing and validation. At this point, you may want to use various tools to help optimize your instance types and configuration to get the best possible performance. The following figure provides an example of the gains that can be achieved by using the FIL backend for an XGBoost model on Triton.

Summary
In this post, we walked you through deploying an XGBoost ensemble workload to SageMaker with Triton Inference Server. Moving workloads to Triton on SageMaker can be a beneficial return on investment. As with any adoption of technology, a vetting process and plan are key, and we detailed a five-step process to guide you through what to consider when moving your workloads. In addition, we dove deep into the steps needed to deploy an ensemble that uses using Python preprocessing and an XGBoost model on Triton on SageMaker.
SageMaker provides the tools to remove the undifferentiated heavy lifting from each stage of the ML lifecycle, thereby facilitating the rapid experimentation and exploration needed to fully optimize your model deployments. SageMaker hosting support for Triton Inference Server enables low-latency, high transactions per second (TPS) workloads.
You can find the notebooks used for this example on GitHub.
About the author
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.
 Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
 Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
 Bruno Aguiar de Melo is a Software Development Engineer at Amazon.com, where he helps science teams to build, deploy and release ML workloads. He is interested in instrumentation and controllable aspects within the ML modelling/design phase that must be considered and measured with the insight that model execution performance is just as important as model quality performance, particularly in latency constrained use cases. In his spare time, he enjoys wine, board games and cooking.
Bruno Aguiar de Melo is a Software Development Engineer at Amazon.com, where he helps science teams to build, deploy and release ML workloads. He is interested in instrumentation and controllable aspects within the ML modelling/design phase that must be considered and measured with the insight that model execution performance is just as important as model quality performance, particularly in latency constrained use cases. In his spare time, he enjoys wine, board games and cooking.
 Eliuth Triana is a Developer Relations Manager at NVIDIA. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
Eliuth Triana is a Developer Relations Manager at NVIDIA. He connects Amazon and AWS product leaders, developers, and scientists with NVIDIA technologists and product leaders to accelerate Amazon ML/DL workloads, EC2 products, and AWS AI services. In addition, Eliuth is a passionate mountain biker, skier, and poker player.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.