Artificial Intelligence
Amazon DevOps Guru is powered by pre-trained ML models that encode operational excellence
On December 1, 2020, we announced the preview of Amazon DevOps Guru, a machine learning (ML)-powered service that gives operators of cloud-based applications a simpler way to measure and improve an application’s operational performance and availability to reduce expensive downtime.
Amazon DevOps Guru is a turn-key solution that helps operators by automatically ingesting operational data for analysis and predictively identifying operationally relevant issues. Although DevOps Guru uses ML models that are informed by years of operational expertise in building, scaling, and maintaining highly available applications at Amazon.com, it doesn’t require any ML experience.
Amazon DevOps Guru automatically identifies most common behaviors of applications that correspond to operational incidents. When it identifies a critical issue, it alerts service operators with a summary of related anomalies, the likely root cause, and context on when and where the issue occurred. When possible, it also provides prescriptive recommendations on how to remediate the issue. In this post, we shed light on some of the ML approaches that power DevOps Guru.
DevOps Guru detectors
At the core of Amazon DevOps Guru is a unique approach to identify meaningful operational incidents. At the start of our research for DevOps Guru, we focused on domain-agnostic, general-purpose anomaly detection models. Though they gave statistically correct results, these models couldn’t always identify or distinguish critical failures from interesting but not critical issues. Over time, we learned that failure patterns differ considerably from metric to metric. For example, a common use case of DevOps Guru is running highly available, low-latency web applications, where an operator may be interested in monitoring both application latency and the number of incoming requests. However, failure patterns in these two metrics differ substantially, making generic statistical anomaly detection models to address both scenarios unlikely to succeed. As a result, we changed our approach radically. After consulting with domain experts to identify known anomaly types across a variety of metrics and services, we set out to built domain-specific, single-purpose models to identify these known failure modes instead of normal metric behavior.
Fast-forward to now, Amazon DevOps Guru relies on a large ensemble of detectors—statistical models tuned to detect common adverse scenarios in a variety of operational metrics. DevOps Guru detectors don’t need to be trained or configured. They work instantly as long as enough history is available, saving days if not months of time that would otherwise be spent training ML models prior to anomaly generation. Individual detectors work in preconfigured ensembles to generate anomalies on some of the most important metrics operators monitor: error rates, availability, latency, incoming request rates, CPU, memory, and disk utilization, among others.
Detectors codify experts’ understanding of operational anomalies as closely as possible, in both determining anomalous patterns as well as establishing bounds for normal application behavior. Both detectors, and the ensembles that compose them into full models, were trained and tuned on Amazon’s data based on years of operational experience at Amazon.com and AWS. Next, we dive into some of the capabilities of DevOps Guru detectors.
Monitoring resource metrics with finite bounds
The purpose of this detector is to monitor finite resource metrics such as disk utilization. It utilizes a digital filter to detect long-running trends in metric data in a highly scalable and compute-effective manner. The detector notifies operators when these trends point to impending resource exhaustion. The following graph shows an illustrative example.

This detector identified a significant trend in disk usage, heading for disk exhaustion within 24 hours. The model has identified a significant trend between the vertical dashed lines. Extrapolating this trend (diagonal dashed line), the detector predicts time to resource exhaustion. As the metric breaches the horizontal red line, which acts as a significance threshold, the detector notifies operators.
Detecting scenarios with periodicity
Many metrics, such as the number of incoming requests in customer-facing APIs, exhibit periodic behavior. The purpose of the causal convolution detector is to analyze temporal data with such patterns and to determine expected periodic behavior. When the detector infers that a metric is periodic, it adapts normal metric behavior thresholds to the seasonal pattern (as in the following graph). On a selected group of metrics, Amazon DevOps Guru can also identify and filter periodic spiking behavior, such as regular batch jobs producing high database load. In the following graph, we only see one detector active for better visualization—in reality, the causal convolution detector tracks the seasonal metric closely, whereas a further dynamic threshold detector detects catastrophic changes if breached.
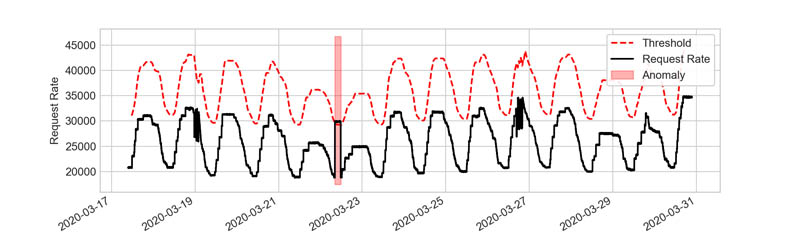
The causal convolution detector sets bounds for application behavior in line with daily application load patterns. By tracking the seasonality, it allows catching spikes relative to the weekend, which traditional approaches, based on static threshold lines, only catch at the expense of many false positives.
DevOps Guru insights
Instead of providing just a list of anomalies that an ensemble of detectors find, DevOps Guru generates operational insights that aggregate relevant information needed to investigate and remediate an operational issue. Amazon DevOps Guru leverages anomaly metadata to identify related anomalies and potential root causes. Based on metadata, related anomalies are grouped together based on their temporal proximity, shared resources, and a large graph of potential causal links between anomaly types.
DevOps Guru presents insights with the following:
- Graphs and timelines related to the numerous anomalous metrics
- Contextual information such as relevant events and log snippets for easily understanding the anomaly scope
- Recommendations to remediate the issue
The following screenshot illustrates an example insight detail page from DevOps Guru, which shows a collection of related metrics’ anomalies in a timeline view.

Conclusion
Amazon DevOps Guru saves IT operators hours if not days of time and effort spent detecting, debugging, and resolving operational issues. Because it uses pre-trained proprietary ML models informed by years of operational experience at Amazon.com and AWS in managing highly available services, IT operators can receive the same high-quality insights without having any ML experience. Start using DevOps Guru today.
Acknowledgements: The algorithms and models presented in this blog post were developed jointly with Jan Gasthaus, Valentin Flunkert, Syama Rangapuram, Lorenzo Stella, Konstantinos Benidis, and François-Xavier Aubet.
About the Authors
 Caner Türkmen is a Machine Learning Scientist at Amazon Web Services, where he works on problems at the intersection of machine learning, forecasting, and anomaly detection. Before joining AWS, he worked in the management consulting industry as a data scientist, serving the financial services and telecommunications industries on projects across the globe. Caner’s personal research interests span a range of topics including probabilistic and Bayesian ML, stochastic processes, and their practical applications.
Caner Türkmen is a Machine Learning Scientist at Amazon Web Services, where he works on problems at the intersection of machine learning, forecasting, and anomaly detection. Before joining AWS, he worked in the management consulting industry as a data scientist, serving the financial services and telecommunications industries on projects across the globe. Caner’s personal research interests span a range of topics including probabilistic and Bayesian ML, stochastic processes, and their practical applications.
 Ravi Turlapati leads product efforts at AWS. Ravi joined AWS more than three years ago, and has launched multiple products from scratch including AWS Data Exchange and Amazon DevOps Guru. In his latest role at AWS AI group, Ravi aims to deliver easy to use ML-based products that solve complex challenges for customers. Ravi is passionate about social causes and supports any charity that creates a self sustaining environment for those in need.
Ravi Turlapati leads product efforts at AWS. Ravi joined AWS more than three years ago, and has launched multiple products from scratch including AWS Data Exchange and Amazon DevOps Guru. In his latest role at AWS AI group, Ravi aims to deliver easy to use ML-based products that solve complex challenges for customers. Ravi is passionate about social causes and supports any charity that creates a self sustaining environment for those in need.
 Tim Januschowski is a Machine Learning Science Manager in Amazon’s AWS AI Labs. He has broad interests in machine learning with a particular focus on machine learning for business problems and decision making. At Amazon, he has produced end-to-end solutions for a wide variety of problems, from forecasting, to anomaly detection and personalization in application areas such as retail, operations and energy. Tim’s interests in applying machine learning span applications, system, algorithm and modeling aspects and the downstream mathematical programming problems. He studied Mathematics at TU Berlin, IMPA, Rio de Janeiro, and Zuse-Institute Berlin and holds a PhD from University College Cork.
Tim Januschowski is a Machine Learning Science Manager in Amazon’s AWS AI Labs. He has broad interests in machine learning with a particular focus on machine learning for business problems and decision making. At Amazon, he has produced end-to-end solutions for a wide variety of problems, from forecasting, to anomaly detection and personalization in application areas such as retail, operations and energy. Tim’s interests in applying machine learning span applications, system, algorithm and modeling aspects and the downstream mathematical programming problems. He studied Mathematics at TU Berlin, IMPA, Rio de Janeiro, and Zuse-Institute Berlin and holds a PhD from University College Cork.