Artificial Intelligence
Amazon SageMaker Automatic Model Tuning now supports grid search
Today Amazon SageMaker announced the support of Grid search for automatic model tuning, providing users with an additional strategy to find the best hyperparameter configuration for your model.
Amazon SageMaker automatic model tuning finds the best version of a model by running many training jobs on your dataset using a range of hyperparameters that you specify. Then it chooses the hyperparameter values that result in a model that performs the best, as measured by a metric of your choice.
To find the best hyperparameters values for your model, Amazon SageMaker automatic model tuning supports multiple strategies, including Bayesian (default), Random search, and Hyperband.
Grid search
Grid search exhaustively explores the configurations in the grid of hyperparameters that you define, which allows you to get insights into the most promising hyperparameter configurations in your grid and deterministically reproduce your results across different tuning runs. Grid search gives you more confidence that the entire hyper parameter search space was explored. This benefit comes with a trade-off because it’s computationally more expensive than Bayesian and random search if your main goal is to find the best hyperparameter configuration.
Grid search with Amazon SageMaker
In Amazon SageMaker, you use Grid search when your problem requires you to have the optimal hyperparameter combination that maximizes or minimizes your objective metric. A common use case where customer use Grid Search is when model accuracy and reproducibility is more important for your business than the training cost required to obtain it.
To enable Grid Search in Amazon SageMaker, set the Strategy field to Grid when you create a tuning job, as follows:
Additionally, Grid search requires you to define your search space (Cartesian grid) as a categorical range of discrete values in your job definition using the CategoricalParameterRanges key under the ParameterRanges parameter, as follows:
Note that we don’t specify MaxNumberOfTrainingJobs for Grid search in the job definition because this is determined for you from the number of category combinations. When using Random and Bayesian search, you specify the MaxNumberOfTrainingJobs parameter as a way to control tuning job cost by defining an upper boundary for compute. With Grid search, the value of MaxNumberOfTrainingJobs (now optional) is automatically set as the number of candidates for the grid search in the DescribeHyperParameterTuningJob shape. This allows you to explore your desired grid of hyperparameters exhaustively. Additionally, Grid search job definition only accepts discrete categorical ranges and doesn’t require a continuous or integer ranges definition because each value in the grid is considered discrete.
Grid Search experiment
In this experiment, given a regression task, we search for the optimal hyperparameters within a search space of 200 hyperparameters, 20 eta and 10 alpha ranging from 0.1 to 1. We use the direct marketing dataset to tune a regression model.
- eta: Step size shrinkage used in updates to prevent over-fitting. After each boosting step, you can directly get the weights of new features. The
etaparameter actually shrinks the feature weights to make the boosting process more conservative. - alpha: L1 regularization term on weights. Increasing this value makes models more conservative.
 |
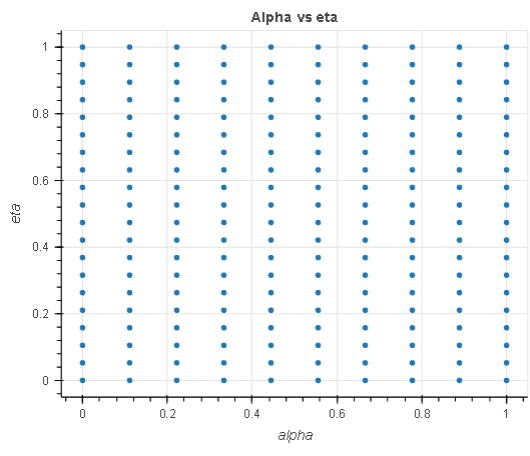 |
The chart to the left shows an analysis of the eta hyperparameter in relation to the objective metric and demonstrates how grid search has exhausted the entire search space (grid) in the X axes before returning the best model. Equally, the chart to the right analyzes the two hyperparameters in a single cartesian space to demonstrate that all the points in the grid were picked during tuning.
The experiment above demonstrates that the exhaustive nature of Grid search guaranties an optimal hyperparameter selection given the defined search space. It also demonstrates that you can reproduce your search result across tuning iterations, all other things being equal.
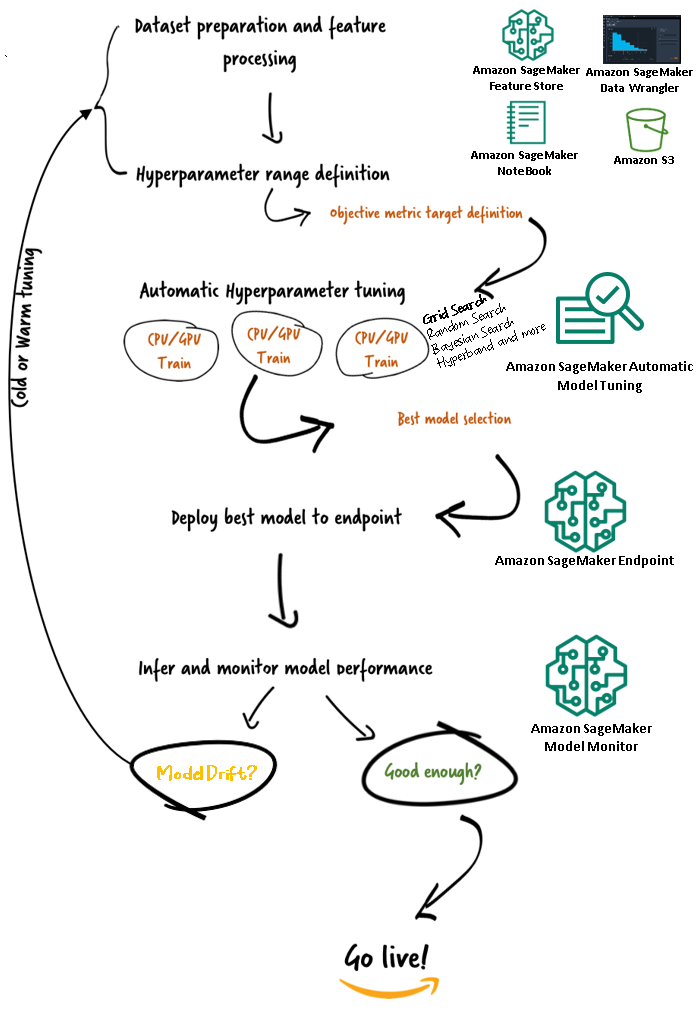
Amazon SageMaker Automatic Model Tuning workflows (AMT)
With Amazon SageMaker automatic model tuning, you can find the best version of your model by running training jobs on your dataset with several search strategies, such as Bayesian, Random search, Grid search, and Hyperband. Automatic model tuning allows you to reduce the time to tune a model by automatically searching for the best hyperparameter configuration within the hyperparameter ranges that you specify.
Now that we have reviewed the advantage of using Grid search in Amazon SageMaker AMT, let’s take a look at AMT’s workflows and understand how it all fits together in SageMaker.
Conclusion
In this post, we discussed how you can now use the Grid search strategy to find the best model and its ability to deterministically reproduce results across different tuning jobs. We discussed the trade-off when using grid search compared to other strategies, and how it allows you to explore what regions of the hyperparameter spaces are most promising and reproduce your results deterministically.
To learn more about automatic model tuning, visit the product page and technical documentation.
About the author
 Doug Mbaya is a Senior Partner Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solutions in the cloud.
Doug Mbaya is a Senior Partner Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solutions in the cloud.