One of the challenges in data science is getting access to operational or real-time data, which is often stored in operational database systems. Being able to connect data science tools to operational data easily and efficiently unleashes enormous potential for gaining insights from real-time data. In this post, we explore using Amazon SageMaker to analyze data stored in Amazon DocumentDB (with MongoDB compatibility).
For illustrative purposes, we use public event data from the GitHub API, which has a complex nested JSON format, and is well-suited for a document database such as Amazon DocumentDB. We use SageMaker to analyze this data, conduct descriptive analysis, and build a simple machine learning (ML) model to predict whether a pull request will close within 24 hours, before writing prediction results back into the database.
SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly. SageMaker removes the heavy lifting from each step of the ML process to make it easier to develop high-quality models.
Amazon DocumentDB is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without having to worry about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data.
Solution overview
In this post, we analyze GitHub events, examples of which include issues, forks, and pull requests. Each event is represented by the GitHub API as a complex, nested JSON object, which is a format well-suited for Amazon DocumentDB. The following code is an example of the output from a pull request event:
{
"id": "13469392114",
"type": "PullRequestEvent",
"actor": {
"id": 33526713,
"login": "arjkesh",
"display_login": "arjkesh",
"gravatar_id": "",
"url": "https://api.github.com/users/arjkesh",
"avatar_url": "https://avatars.githubusercontent.com/u/33526713?"
},
"repo": {
"id": 234634164,
"name": "aws/deep-learning-containers",
"url": "https://api.github.com/repos/aws/deep-learning-containers"
},
"payload": {
"action": "closed",
"number": 570,
"pull_request": {
"url": "https://api.github.com/repos/aws/deep-learning-containers/pulls/570",
"id": 480316742,
"node_id": "MDExOlB1bGxSZXF1ZXN0NDgwMzE2NzQy",
"html_url": "https://github.com/aws/deep-learning-containers/pull/570",
"diff_url": "https://github.com/aws/deep-learning-containers/pull/570.diff",
"patch_url": "https://github.com/aws/deep-learning-containers/pull/570.patch",
"issue_url": "https://api.github.com/repos/aws/deep-learning-containers/issues/570",
"number": 570,
"state": "closed",
"locked": false,
"title": "[test][tensorflow][ec2] Add timeout to Data Service test setup",
"user": {
"login": "arjkesh",
"id": 33526713,
"node_id": "MDQ6VXNlcjMzNTI2NzEz",
"avatar_url": "https://avatars3.githubusercontent.com/u/33526713?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arjkesh",
"html_url": "https://github.com/arjkesh",
"followers_url": "https://api.github.com/users/arjkesh/followers",
"following_url": "https://api.github.com/users/arjkesh/following{/other_user}",
"gists_url": "https://api.github.com/users/arjkesh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arjkesh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arjkesh/subscriptions",
"organizations_url": "https://api.github.com/users/arjkesh/orgs",
"repos_url": "https://api.github.com/users/arjkesh/repos",
"events_url": "https://api.github.com/users/arjkesh/events{/privacy}",
"received_events_url": "https://api.github.com/users/arjkesh/received_events",
"type": "User",
"site_admin": false
},
"body": "*Issue #, if available:*\r\n\r\n## Checklist\r\n- [x] I've prepended PR tag with frameworks/job this applies to : [mxnet, tensorflow, pytorch] | [ei/neuron] | [build] | [test] | [benchmark] | [ec2, ecs, eks, sagemaker]\r\n\r\n*Description:*\r\nCurrently, this test does not timeout in the same manner as execute_ec2_training_test or other ec2 training tests. As such, a timeout should be added here to avoid hanging instances. A separate PR will be opened to address why the global timeout does not catch this.\r\n\r\n*Tests run:*\r\nPR tests\r\n\r\n\r\nBy submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license. I confirm that you can use, modify, copy, and redistribute this contribution, under the terms of your choice.\r\n\r\n",
"created_at": "2020-09-05T00:29:22Z",
"updated_at": "2020-09-10T06:16:53Z",
"closed_at": "2020-09-10T06:16:53Z",
"merged_at": null,
"merge_commit_sha": "4144152ac0129a68c9c6f9e45042ecf1d89d3e1a",
"assignee": null,
"assignees": [
],
"requested_reviewers": [
],
"requested_teams": [
],
"labels": [
],
"milestone": null,
"draft": false,
"commits_url": "https://api.github.com/repos/aws/deep-learning-containers/pulls/570/commits",
"review_comments_url": "https://api.github.com/repos/aws/deep-learning-containers/pulls/570/comments",
"review_comment_url": "https://api.github.com/repos/aws/deep-learning-containers/pulls/comments{/number}",
"comments_url": "https://api.github.com/repos/aws/deep-learning-containers/issues/570/comments",
"statuses_url": "https://api.github.com/repos/aws/deep-learning-containers/statuses/99bb5a14993ceb29c16641bd54865db46ee6bf59",
"head": {
"label": "arjkesh:add_timeouts",
"ref": "add_timeouts",
"sha": "99bb5a14993ceb29c16641bd54865db46ee6bf59",
"user": {
"login": "arjkesh",
"id": 33526713,
"node_id": "MDQ6VXNlcjMzNTI2NzEz",
"avatar_url": "https://avatars3.githubusercontent.com/u/33526713?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arjkesh",
"html_url": "https://github.com/arjkesh",
"followers_url": "https://api.github.com/users/arjkesh/followers",
"following_url": "https://api.github.com/users/arjkesh/following{/other_user}",
"gists_url": "https://api.github.com/users/arjkesh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arjkesh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arjkesh/subscriptions",
"organizations_url": "https://api.github.com/users/arjkesh/orgs",
"repos_url": "https://api.github.com/users/arjkesh/repos",
"events_url": "https://api.github.com/users/arjkesh/events{/privacy}",
"received_events_url": "https://api.github.com/users/arjkesh/received_events",
"type": "User",
"site_admin": false
},
"repo": {
"id": 265346646,
"node_id": "MDEwOlJlcG9zaXRvcnkyNjUzNDY2NDY=",
"name": "deep-learning-containers-1",
"full_name": "arjkesh/deep-learning-containers-1",
"private": false,
"owner": {
"login": "arjkesh",
"id": 33526713,
"node_id": "MDQ6VXNlcjMzNTI2NzEz",
"avatar_url": "https://avatars3.githubusercontent.com/u/33526713?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arjkesh",
"html_url": "https://github.com/arjkesh",
"followers_url": "https://api.github.com/users/arjkesh/followers",
"following_url": "https://api.github.com/users/arjkesh/following{/other_user}",
"gists_url": "https://api.github.com/users/arjkesh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arjkesh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arjkesh/subscriptions",
"organizations_url": "https://api.github.com/users/arjkesh/orgs",
"repos_url": "https://api.github.com/users/arjkesh/repos",
"events_url": "https://api.github.com/users/arjkesh/events{/privacy}",
"received_events_url": "https://api.github.com/users/arjkesh/received_events",
"type": "User",
"site_admin": false
},
"html_url": "https://github.com/arjkesh/deep-learning-containers-1",
"description": "AWS Deep Learning Containers (DLCs) are a set of Docker images for training and serving models in TensorFlow, TensorFlow 2, PyTorch, and MXNet.",
"fork": true,
"url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1",
"forks_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/forks",
"keys_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/keys{/key_id}",
"collaborators_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/collaborators{/collaborator}",
"teams_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/teams",
"hooks_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/hooks",
"issue_events_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/issues/events{/number}",
"events_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/events",
"assignees_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/assignees{/user}",
"branches_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/branches{/branch}",
"tags_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/tags",
"blobs_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/git/blobs{/sha}",
"git_tags_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/git/tags{/sha}",
"git_refs_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/git/refs{/sha}",
"trees_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/git/trees{/sha}",
"statuses_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/statuses/{sha}",
"languages_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/languages",
"stargazers_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/stargazers",
"contributors_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/contributors",
"subscribers_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/subscribers",
"subscription_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/subscription",
"commits_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/commits{/sha}",
"git_commits_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/git/commits{/sha}",
"comments_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/comments{/number}",
"issue_comment_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/issues/comments{/number}",
"contents_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/contents/{+path}",
"compare_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/compare/{base}...{head}",
"merges_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/merges",
"archive_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/{archive_format}{/ref}",
"downloads_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/downloads",
"issues_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/issues{/number}",
"pulls_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/pulls{/number}",
"milestones_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/milestones{/number}",
"notifications_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/notifications{?since,all,participating}",
"labels_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/labels{/name}",
"releases_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/releases{/id}",
"deployments_url": "https://api.github.com/repos/arjkesh/deep-learning-containers-1/deployments",
"created_at": "2020-05-19T19:38:21Z",
"updated_at": "2020-06-23T04:18:45Z",
"pushed_at": "2020-09-10T02:04:27Z",
"git_url": "git://github.com/arjkesh/deep-learning-containers-1.git",
"ssh_url": "git@github.com:arjkesh/deep-learning-containers-1.git",
"clone_url": "https://github.com/arjkesh/deep-learning-containers-1.git",
"svn_url": "https://github.com/arjkesh/deep-learning-containers-1",
"homepage": "https://docs.aws.amazon.com/deep-learning-containers/latest/devguide/deep-learning-containers-images.html",
"size": 68734,
"stargazers_count": 0,
"watchers_count": 0,
"language": "Python",
"has_issues": false,
"has_projects": true,
"has_downloads": true,
"has_wiki": true,
"has_pages": true,
"forks_count": 0,
"mirror_url": null,
"archived": false,
"disabled": false,
"open_issues_count": 0,
"license": {
"key": "apache-2.0",
"name": "Apache License 2.0",
"spdx_id": "Apache-2.0",
"url": "https://api.github.com/licenses/apache-2.0",
"node_id": "MDc6TGljZW5zZTI="
},
"forks": 0,
"open_issues": 0,
"watchers": 0,
"default_branch": "master"
}
},
"base": {
"label": "aws:master",
"ref": "master",
"sha": "9514fde23ae9eeffb9dfba13ce901fafacef30b5",
"user": {
"login": "aws",
"id": 2232217,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjIyMzIyMTc=",
"avatar_url": "https://avatars3.githubusercontent.com/u/2232217?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aws",
"html_url": "https://github.com/aws",
"followers_url": "https://api.github.com/users/aws/followers",
"following_url": "https://api.github.com/users/aws/following{/other_user}",
"gists_url": "https://api.github.com/users/aws/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aws/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aws/subscriptions",
"organizations_url": "https://api.github.com/users/aws/orgs",
"repos_url": "https://api.github.com/users/aws/repos",
"events_url": "https://api.github.com/users/aws/events{/privacy}",
"received_events_url": "https://api.github.com/users/aws/received_events",
"type": "Organization",
"site_admin": false
},
"repo": {
"id": 234634164,
"node_id": "MDEwOlJlcG9zaXRvcnkyMzQ2MzQxNjQ=",
"name": "deep-learning-containers",
"full_name": "aws/deep-learning-containers",
"private": false,
"owner": {
"login": "aws",
"id": 2232217,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjIyMzIyMTc=",
"avatar_url": "https://avatars3.githubusercontent.com/u/2232217?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aws",
"html_url": "https://github.com/aws",
"followers_url": "https://api.github.com/users/aws/followers",
"following_url": "https://api.github.com/users/aws/following{/other_user}",
"gists_url": "https://api.github.com/users/aws/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aws/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aws/subscriptions",
"organizations_url": "https://api.github.com/users/aws/orgs",
"repos_url": "https://api.github.com/users/aws/repos",
"events_url": "https://api.github.com/users/aws/events{/privacy}",
"received_events_url": "https://api.github.com/users/aws/received_events",
"type": "Organization",
"site_admin": false
},
"html_url": "https://github.com/aws/deep-learning-containers",
"description": "AWS Deep Learning Containers (DLCs) are a set of Docker images for training and serving models in TensorFlow, TensorFlow 2, PyTorch, and MXNet.",
"fork": false,
"url": "https://api.github.com/repos/aws/deep-learning-containers",
"forks_url": "https://api.github.com/repos/aws/deep-learning-containers/forks",
"keys_url": "https://api.github.com/repos/aws/deep-learning-containers/keys{/key_id}",
"collaborators_url": "https://api.github.com/repos/aws/deep-learning-containers/collaborators{/collaborator}",
"teams_url": "https://api.github.com/repos/aws/deep-learning-containers/teams",
"hooks_url": "https://api.github.com/repos/aws/deep-learning-containers/hooks",
"issue_events_url": "https://api.github.com/repos/aws/deep-learning-containers/issues/events{/number}",
"events_url": "https://api.github.com/repos/aws/deep-learning-containers/events",
"assignees_url": "https://api.github.com/repos/aws/deep-learning-containers/assignees{/user}",
"branches_url": "https://api.github.com/repos/aws/deep-learning-containers/branches{/branch}",
"tags_url": "https://api.github.com/repos/aws/deep-learning-containers/tags",
"blobs_url": "https://api.github.com/repos/aws/deep-learning-containers/git/blobs{/sha}",
"git_tags_url": "https://api.github.com/repos/aws/deep-learning-containers/git/tags{/sha}",
"git_refs_url": "https://api.github.com/repos/aws/deep-learning-containers/git/refs{/sha}",
"trees_url": "https://api.github.com/repos/aws/deep-learning-containers/git/trees{/sha}",
"statuses_url": "https://api.github.com/repos/aws/deep-learning-containers/statuses/{sha}",
"languages_url": "https://api.github.com/repos/aws/deep-learning-containers/languages",
"stargazers_url": "https://api.github.com/repos/aws/deep-learning-containers/stargazers",
"contributors_url": "https://api.github.com/repos/aws/deep-learning-containers/contributors",
"subscribers_url": "https://api.github.com/repos/aws/deep-learning-containers/subscribers",
"subscription_url": "https://api.github.com/repos/aws/deep-learning-containers/subscription",
"commits_url": "https://api.github.com/repos/aws/deep-learning-containers/commits{/sha}",
"git_commits_url": "https://api.github.com/repos/aws/deep-learning-containers/git/commits{/sha}",
"comments_url": "https://api.github.com/repos/aws/deep-learning-containers/comments{/number}",
"issue_comment_url": "https://api.github.com/repos/aws/deep-learning-containers/issues/comments{/number}",
"contents_url": "https://api.github.com/repos/aws/deep-learning-containers/contents/{+path}",
"compare_url": "https://api.github.com/repos/aws/deep-learning-containers/compare/{base}...{head}",
"merges_url": "https://api.github.com/repos/aws/deep-learning-containers/merges",
"archive_url": "https://api.github.com/repos/aws/deep-learning-containers/{archive_format}{/ref}",
"downloads_url": "https://api.github.com/repos/aws/deep-learning-containers/downloads",
"issues_url": "https://api.github.com/repos/aws/deep-learning-containers/issues{/number}",
"pulls_url": "https://api.github.com/repos/aws/deep-learning-containers/pulls{/number}",
"milestones_url": "https://api.github.com/repos/aws/deep-learning-containers/milestones{/number}",
"notifications_url": "https://api.github.com/repos/aws/deep-learning-containers/notifications{?since,all,participating}",
"labels_url": "https://api.github.com/repos/aws/deep-learning-containers/labels{/name}",
"releases_url": "https://api.github.com/repos/aws/deep-learning-containers/releases{/id}",
"deployments_url": "https://api.github.com/repos/aws/deep-learning-containers/deployments",
"created_at": "2020-01-17T20:52:43Z",
"updated_at": "2020-09-09T22:57:46Z",
"pushed_at": "2020-09-10T04:01:22Z",
"git_url": "git://github.com/aws/deep-learning-containers.git",
"ssh_url": "git@github.com:aws/deep-learning-containers.git",
"clone_url": "https://github.com/aws/deep-learning-containers.git",
"svn_url": "https://github.com/aws/deep-learning-containers",
"homepage": "https://docs.aws.amazon.com/deep-learning-containers/latest/devguide/deep-learning-containers-images.html",
"size": 68322,
"stargazers_count": 61,
"watchers_count": 61,
"language": "Python",
"has_issues": true,
"has_projects": true,
"has_downloads": true,
"has_wiki": true,
"has_pages": false,
"forks_count": 49,
"mirror_url": null,
"archived": false,
"disabled": false,
"open_issues_count": 28,
"license": {
"key": "apache-2.0",
"name": "Apache License 2.0",
"spdx_id": "Apache-2.0",
"url": "https://api.github.com/licenses/apache-2.0",
"node_id": "MDc6TGljZW5zZTI="
},
"forks": 49,
"open_issues": 28,
"watchers": 61,
"default_branch": "master"
}
},
"_links": {
"self": {
"href": "https://api.github.com/repos/aws/deep-learning-containers/pulls/570"
},
"html": {
"href": "https://github.com/aws/deep-learning-containers/pull/570"
},
"issue": {
"href": "https://api.github.com/repos/aws/deep-learning-containers/issues/570"
},
"comments": {
"href": "https://api.github.com/repos/aws/deep-learning-containers/issues/570/comments"
},
"review_comments": {
"href": "https://api.github.com/repos/aws/deep-learning-containers/pulls/570/comments"
},
"review_comment": {
"href": "https://api.github.com/repos/aws/deep-learning-containers/pulls/comments{/number}"
},
"commits": {
"href": "https://api.github.com/repos/aws/deep-learning-containers/pulls/570/commits"
},
"statuses": {
"href": "https://api.github.com/repos/aws/deep-learning-containers/statuses/99bb5a14993ceb29c16641bd54865db46ee6bf59"
}
},
"author_association": "CONTRIBUTOR",
"active_lock_reason": null,
"merged": false,
"mergeable": false,
"rebaseable": false,
"mergeable_state": "dirty",
"merged_by": null,
"comments": 1,
"review_comments": 0,
"maintainer_can_modify": false,
"commits": 6,
"additions": 26,
"deletions": 18,
"changed_files": 1
}
},
"public": true,
"created_at": "2020-09-10T06:16:53Z",
"org": {
"id": 2232217,
"login": "aws",
"gravatar_id": "",
"url": "https://api.github.com/orgs/aws",
"avatar_url": "https://avatars.githubusercontent.com/u/2232217?"
}
}
Amazon DocumentDB stores each JSON event as a document. Multiple documents are stored in a collection, and multiple collections are stored in a database. Borrowing terminology from relational databases, documents are analogous to rows, and collections are analogous to tables. The following table summarizes these terms.
| Document Database Concepts |
SQL Concepts |
| Document |
Row |
| Collection |
Table |
| Database |
Database |
| Field |
Column |
We now implement the following Amazon DocumentDB tasks using SageMaker:
- Connect to an Amazon DocumentDB cluster.
- Ingest GitHub event data stored in the database.
- Generate descriptive statistics.
- Conduct feature selection and engineering.
- Generate predictions.
- Store prediction results.
Creating resources
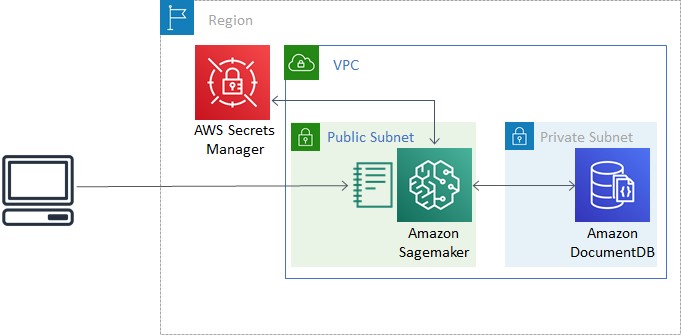
We have prepared the following AWS CloudFormation template to create the required AWS resources for this post. For instructions on creating a CloudFormation stack, see the video Simplify your Infrastructure Management using AWS CloudFormation.
The CloudFormation stack provisions the following:
- A VPC with three private subnets and one public subnet.
- An Amazon DocumentDB cluster with three nodes, one in each private subnet. When creating an Amazon DocumentDB cluster in a VPC, its subnet group should have subnets in at least two Availability Zones in a given Region.
- An AWS Secrets Manager secret to store login credentials for Amazon DocumentDB. This allows us to avoid storing plaintext credentials in our SageMaker instance.
- A SageMaker role to retrieve the Amazon DocumentDB login credentials, allowing connections to the Amazon DocumentDB cluster from a SageMaker notebook.
- A SageMaker instance to run queries and analysis.
- A SageMaker instance lifecycle configuration to run a bash script every time the instance boots up, downloading a certificate bundle to create TLS connections to Amazon DocumentDB, as well as a Jupyter Notebook containing the code for this tutorial. The script also installs required Python libraries (such as
pymongo for database methods and xgboost for ML modeling), so that we don’t need to install these libraries from the notebook. See the following code:
#!/bin/bash
sudo -u ec2-user -i <<'EOF'
source /home/ec2-user/anaconda3/bin/activate python3
pip install --upgrade pymongo
pip install --upgrade xgboost
source /home/ec2-user/anaconda3/bin/deactivate
cd /home/ec2-user/SageMaker
wget https://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pem
wget https://github.com/aws-samples/documentdb-sagemaker-example/blob/main/script.ipynb
EOF
In creating the CloudFormation stack, you need to specify the following:
- Name for your CloudFormation stack
- Amazon DocumentDB username and password (to be stored in Secrets Manager)
- Amazon DocumentDB instance type (default db.r5.large)
- SageMaker instance type (default ml.t3.xlarge)
It should take about 15 minutes to create the CloudFormation stack. The following diagram shows the resource architecture.
Running this tutorial for an hour should cost no more than US$2.00.
Connecting to an Amazon DocumentDB cluster
All the subsequent code in this tutorial is in the Jupyter Notebook in the SageMaker instance created in your CloudFormation stack.
- To connect to your Amazon DocumentDB cluster from a SageMaker notebook, you have to first specify the following code:
stack_name = "docdb-sm" # name of CloudFormation stack
The stack_name refers to the name you specified for your CloudFormation stack upon its creation.
- Use this parameter in the following method to get your Amazon DocumentDB credentials stored in Secrets Manager:
def get_secret(stack_name):
# Create a Secrets Manager client
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=session.region_name
)
secret_name = f'{stack_name}-DocDBSecret'
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
secret = get_secret_value_response['SecretString']
return json.loads(secret)
- Next, we extract the login parameters from the stored secret:
secret = get_secret(secret_name)
db_username = secret['username']
db_password = secret['password']
db_port = secret['port']
db_host = secret['host']
- Using the extracted parameters, we create a
MongoClient from the pymongo library to establish a connection to the Amazon DocumentDB cluster.
uri_str = f"mongodb://{db_username}:{db_password}@{db_host}:{db_port}/?ssl=true&ssl_ca_certs=rds-combined-ca-bundle.pem&replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false"
client = MongoClient(uri_str)
Ingesting data
After we establish the connection to our Amazon DocumentDB cluster, we create a database and collection to store our GitHub event data. For this post, we name our database gharchive, and our collection events:
db_name = "gharchive" # name the database
collection_name = "events" # name the collection
db = client[db_name] # create a database
events = db[collection_name] # create a collection
Next, we need to download the data from gharchive.org, which has been aggregated into hourly archives with the following naming format:
https://data.gharchive.org/YYYY-MM-DD-H.json.gz
The aim of this analysis is to predict whether a pull request closes within 24 hours. For simplicity, we limit the analysis over two days: February 10–11, 2015. Across these two days, there were over 1 million GitHub events.
The following code downloads the relevant hourly archives, then formats and ingests the data into your Amazon DocumentDB database. It takes about 7 minutes to run on an ml.t3.xlarge instance.
# Specify target date and time range for GitHub events
year = 2015
month = 2
days = [10, 11]
hours = range(0, 24)
# Download data from gharchive.org and insert into Amazon DocumentDB
for day in days:
for hour in hours:
print(f"Processing events for {year}-{month}-{day}, {hour} hr.")
# zeropad values
month_ = str(month).zfill(2)
day_ = str(day).zfill(2)
# download data
url = f"https://data.gharchive.org/{year}-{month_}-{day_}-{hour}.json.gz"
response = requests.get(url, stream=True)
# decompress data
respdata = zlib.decompress(response.content, zlib.MAX_WBITS|32)
# format data
stringdata = respdata.split(b'\n')
data = [json.loads(x) for x in stringdata if 0 < len(x)]
# ingest data
events.insert_many(data, ordered=True, bypass_document_validation=True)
The option ordered=False command allows the data to be ingested out of order. The bypass_document_validation=True command allows the write to skip validating the JSON input, which is safe to do because we validated the JSON structure when we issued the json.loads() command prior to inserting.
Both options expedite the data ingestion process.
Generating descriptive statistics
As is a common first step in data science, we want to explore the data to get some general descriptive statistics. We can use database operations to calculate some of these basic descriptive statistics.
To get a count of the number of GitHub events, we use the count_documents() command:
events.count_documents({})
> 1174157
The count_documents() command gets the number of documents in a collection. Each GitHub event is recorded as a document, and events is what we had named our collection earlier.
The 1,174,157 documents comprise different types of GitHub events. To see the frequency of each type of event occurring in the dataset, we query the database using the aggregate command:
# Frequency of event types
event_types_query = events.aggregate([
# Group by the type attribute and count
{"$group" : {"_id": "$type", "count": {"$sum": 1}}},
# Reformat the data
{"$project": {"_id": 0, "Type": "$_id", "count": "$count"}},
# Sort by the count in descending order
{"$sort": {"count": -1} }
])
df_event_types = pd.DataFrame(event_types_query
The preceding query groups the events by type, runs a count, and sorts the results in descending order of count. Finally, we wrap the output in pd.DataFrame() to convert the results to a DataFrame. This allows us to generate visualizations such as the following.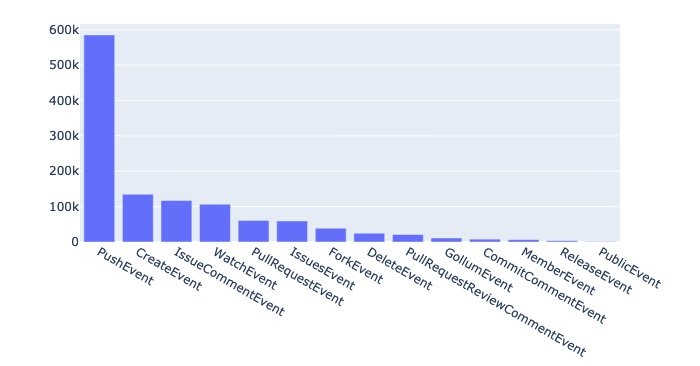
From the plot, we can see that push events were the most frequent, numbering close to 600,000.
Returning to our goal to predict if a pull request closes within 24 hours, we implement another query to include only pull request events, using the database match operation, and then count the number of such events per pull request URL:
# Frequency of PullRequestEvent actions by URL
action_query = events.aggregate([
# Keep only PullRequestEvent types
{"$match" : {"type": "PullRequestEvent"} },
# Group by HTML URL and count
{"$group": {"_id": "$payload.pull_request.html_url", "count": {"$sum": 1}}},
# Reformat the data
{"$project": {"_id": 0, "url": "$_id", "count": "$count"}},
# Sort by the count in descending order
{"$sort": {"count": -1} }
])
df_action = pd.DataFrame(action_query)
From the result, we can see that a single URL could have multiple pull request events, such as those shown in the following screenshot.

One of the attributes of a pull request event is the state of the pull request after the event. Therefore, we’re interested in the latest event by the end of 24 hours in determining whether the pull request was open or closed in that window of time. We show how to run this query later in this post, but continue now with a discussion of descriptive statistics.
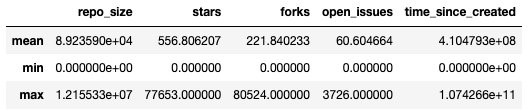
Apart from counts, we can also have the database calculate the mean, maximum, and minimum values for us. In the following query, we do this for potential predictors of a pull request open/close status, specifically the number of stars, forks, and open issues, as well as repository size. We also calculate the time elapsed (in milliseconds) of a pull request event since its creation. For each pull request, there could be multiple pull request events (comments), and this descriptive query spans across all these events:
# Descriptive statistics (mean, max, min) of repo size, stars, forks, open issues, elapsed time
descriptives = list(events.aggregate([
# Keep only PullRequestEvents
{"$match": {"type": "PullRequestEvent"} },
# Project out attributes of interest
{"$project": {
"_id": 0,
"repo_size": "$payload.pull_request.base.repo.size",
"stars": "$payload.pull_request.base.repo.stargazers_count",
"forks": "$payload.pull_request.base.repo.forks_count",
"open_issues": "$payload.pull_request.base.repo.open_issues_count",
"time_since_created": {"$subtract": [{"$dateFromString": {"dateString": "$payload.pull_request.updated_at"}},
{"$dateFromString": {"dateString": "$payload.pull_request.created_at"}}]}
}},
# Calculate min/max/avg for various metrics grouped over full data set
{"$group": {
"_id": "descriptives",
"mean_repo_size": {"$avg": "$repo_size"},
"mean_stars": {"$avg": "$stars"},
"mean_forks": {"$avg": "$forks"},
"mean_open_issues": {"$avg": "$open_issues" },
"mean_time_since_created": {"$avg": "$time_since_created"},
"min_repo_size": {"$min": "$repo_size"},
"min_stars": {"$min": "$stars"},
"min_forks": {"$min": "$forks"},
"min_open_issues": {"$min": "$open_issues" },
"min_time_since_created": {"$min": "$time_since_created"},
"max_repo_size": {"$max": "$repo_size"},
"max_stars": {"$max": "$stars"},
"max_forks": {"$max": "$forks"},
"max_open_issues": {"$max": "$open_issues" },
"max_time_since_created": {"$max": "$time_since_created"}
}},
# Reformat results
{"$project": {
"_id": 0,
"repo_size": {"mean": "$mean_repo_size",
"min": "$min_repo_size",
"max": "$max_repo_size"},
"stars": {"mean": "$mean_stars",
"min": "$min_stars",
"max": "$max_stars"},
"forks": {"mean": "$mean_forks",
"min": "$min_forks",
"max": "$max_forks"},
"open_issues": {"mean": "$mean_open_issues",
"min": "$min_open_issues",
"max": "$max_open_issues"},
"time_since_created": {"mean": "$mean_time_since_created",
"min": "$min_time_since_created",
"max": "$max_time_since_created"},
}}
]))
pd.DataFrame(descriptives[0]
The query results in the following output.
For supported methods of aggregations in Amazon DocumentDB, refer to Aggregation Pipeline Operators.
Conducting feature selection and engineering
Before we can begin building our prediction model, we need to select relevant features to include, and also engineer new features. In the following query, we select pull request events from non-empty repositories with more than 50 forks. We select possible predictors including number of forks (forks_count) and number of open issues (open_issues_count), and engineer new predictors by normalizing those counts by the size of the repository (repo.size). Finally, we shortlist the pull request events that fall within our period of evaluation, and record the latest pull request status (open or close), which is the outcome of our predictive model.
df = list(events.aggregate([
# Filter on just PullRequestEvents
{"$match": {
"type": "PullRequestEvent", # focus on pull requests
"payload.pull_request.base.repo.forks_count": {"$gt": 50}, # focus on popular repos
"payload.pull_request.base.repo.size": {"$gt": 0} # exclude empty repos
}},
# Project only features of interest
{"$project": {
"type": 1,
"payload.pull_request.base.repo.size": 1,
"payload.pull_request.base.repo.stargazers_count": 1,
"payload.pull_request.base.repo.has_downloads": 1,
"payload.pull_request.base.repo.has_wiki": 1,
"payload.pull_request.base.repo.has_pages" : 1,
"payload.pull_request.base.repo.forks_count": 1,
"payload.pull_request.base.repo.open_issues_count": 1,
"payload.pull_request.html_url": 1,
"payload.pull_request.created_at": 1,
"payload.pull_request.updated_at": 1,
"payload.pull_request.state": 1,
# calculate no. of open issues normalized by repo size
"issues_per_repo_size": {"$divide": ["$payload.pull_request.base.repo.open_issues_count",
"$payload.pull_request.base.repo.size"]},
# calculate no. of forks normalized by repo size
"forks_per_repo_size": {"$divide": ["$payload.pull_request.base.repo.forks_count",
"$payload.pull_request.base.repo.size"]},
# format datetime variables
"created_time": {"$dateFromString": {"dateString": "$payload.pull_request.created_at"}},
"updated_time": {"$dateFromString": {"dateString": "$payload.pull_request.updated_at"}},
# calculate time elapsed since PR creation
"time_since_created": {"$subtract": [{"$dateFromString": {"dateString": "$payload.pull_request.updated_at"}},
{"$dateFromString": {"dateString": "$payload.pull_request.created_at"}} ]}
}},
# Keep only events within the window (24hrs) since pull requests was created
# Keep only pull requests that were created on or after the start and before the end period
{"$match": {
"time_since_created": {"$lte": prediction_window},
"created_time": {"$gte": date_start, "$lt": date_end}
}},
# Sort by the html_url and then by the updated_time
{"$sort": {
"payload.pull_request.html_url": 1,
"payload.pull_request.updated_time": 1
}},
# keep the information from the first event in each group, plus the state from the last event in each group
# grouping by html_url
{"$group": {
"_id": "$payload.pull_request.html_url",
"repo_size": {"$first": "$payload.pull_request.base.repo.size"},
"stargazers_count": {"$first": "$payload.pull_request.base.repo.stargazers_count"},
"has_downloads": {"$first": "$payload.pull_request.base.repo.has_downloads"},
"has_wiki": {"$first": "$payload.pull_request.base.repo.has_wiki"},
"has_pages" : {"$first": "$payload.pull_request.base.repo.has_pages"},
"forks_count": {"$first": "$payload.pull_request.base.repo.forks_count"},
"open_issues_count": {"$first": "$payload.pull_request.base.repo.open_issues_count"},
"issues_per_repo_size": {"$first": "$issues_per_repo_size"},
"forks_per_repo_size": {"$first": "$forks_per_repo_size"},
"state": {"$last": "$payload.pull_request.state"}
}}
]))
df = pd.DataFrame(df)
Generating predictions
Before building our model, we split our data into two sets for training and testing:
X = df.drop(['state_open'], axis=1)
y = df['state_open']
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
stratify=y,
random_state=42,
)
For this post, we use 70% of the documents for training the model, and the remaining 30% for testing the model’s predictions against the actual pull request status. We use the XGBoost algorithm to train a binary:logistic model evaluated with area under the curve (AUC) over 20 iterations. The seed is specified to enable reproducibility of results. The other parameters are left as default values. See the following code:
# Format data
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Specify model parameters
param = {
'objective':'binary:logistic',
'eval_metric':'auc',
'seed': 42,
}
# Train model
num_round = 20
bst = xgb.train(param, dtrain, num_round)
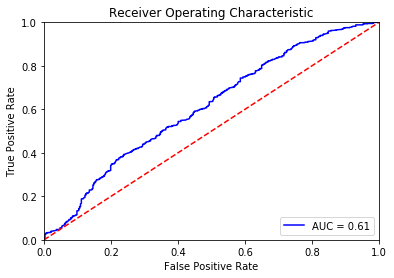
Next, we use the trained model to generate predictions for the test dataset and to calculate and plot the AUC:
preds = bst.predict(dtest)
roc_auc_score(y_test, preds)
> 0.609441068887402
The following plot shows our results.
We can also examine the leading predictors by importance of a pull request event’s state:
xgb.plot_importance(bst, importance_type='weight')
The following plot shows our results.
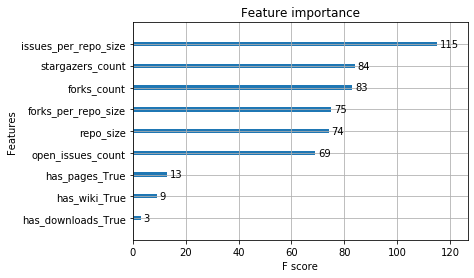
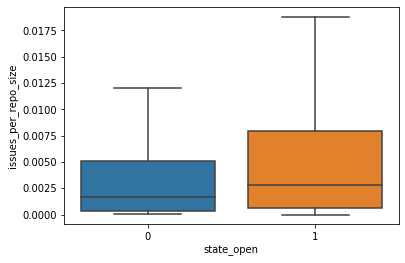
A predictor has different definitions of importance. For this post, we use weight, which is the number of times a predictor appears in the XGBoost trees. The top predictor is the number of open issues normalized by the repository size. Using a box plot, we compare the spread of values for this predictor between closed and still-open pull requests.
After we examine the results and are satisfied with the model performance, we can write predictions back into Amazon DocumentDB.
Storing prediction results
The final step is to store the model predictions back into Amazon DocumentDB. First, we create a new Amazon DocumentDB collection to hold our results, called predictions:
predictions = db['predictions']
Then we change the generated predictions to type float, to be accepted by Amazon DocumentDB:
preds = preds.astype(float)
We need to associate these predictions with their respective pull request events. Therefore, we use the pull request URL as each document’s ID. We match each prediction to its respective pull request URL and consolidate them in a list:
urls = y_test.index
def gen_preds(url, pred):
"""
Generate document with prediction of whether pull request will close in 24 hours.
ID is pull request URL.
"""
doc = {
"_id": url,
"close_24hr_prediction": pred}
return doc
documents = [gen_preds(url, pred) for url, pred in zip(urls, preds)]
Finally, we use the insert_many command to write the documents to Amazon DocumentDB:
predictions.insert_many(documents, ordered=False)
We can query a sample of five documents in the predictions collections to verify that the results have been inserted correctly:
pd.DataFrame(predictions.find({}).limit(5))
The following screenshot shows our results.

Cleaning up resources
To save cost, delete the CloudFormation stack you created. This removes all the resources you provisioned using the CloudFormation template, including the VPC, Amazon DocumentDB cluster, and SageMaker instance. For instructions, see Deleting a stack on the AWS CloudFormation console.
Summary
We used SageMaker to analyze data stored in Amazon DocumentDB, conduct descriptive analysis, and build a simple ML model to make predictions, before writing prediction results back into the database.
Amazon DocumentDB provides you with a number of capabilities that help you back up and restore your data based on your use case. For more information, see Best Practices for Amazon DocumentDB. If you’re new to Amazon DocumentDB, see Getting Started with Amazon DocumentDB. If you’re planning to migrate to Amazon DocumentDB, see Migrating to Amazon DocumentDB.
About the Authors
 Annalyn Ng is a Senior Data Scientist with AWS Professional Services, where she develops and deploys machine learning solutions for customers. Annalyn graduated with an MPhil from the University of Cambridge, and blogs about machine learning at algobeans.com. Her book, ’Numsense! Data Science for the Layman’, has been translated into over five languages and is used in top universities as reference text.
Annalyn Ng is a Senior Data Scientist with AWS Professional Services, where she develops and deploys machine learning solutions for customers. Annalyn graduated with an MPhil from the University of Cambridge, and blogs about machine learning at algobeans.com. Her book, ’Numsense! Data Science for the Layman’, has been translated into over five languages and is used in top universities as reference text.
 Brian Hess is a Senior Solution Architect Specialist for Amazon DocumentDB (with MongoDB compatibility) at AWS. He has been in the data and analytics space for over 20 years and has extensive experience with relational and NoSQL databases.
Brian Hess is a Senior Solution Architect Specialist for Amazon DocumentDB (with MongoDB compatibility) at AWS. He has been in the data and analytics space for over 20 years and has extensive experience with relational and NoSQL databases.