Artificial Intelligence
Build an Automatic Inventory Solution with public datasets and Amazon Rekognition Custom Labels
Inventorying store items is a general demand for retail stores and supermarkets. This is usually performed manually by counting items and visually checking the correct placement. Tracking changes in inventory helps business owners evaluate performance of each product, validate correct placement, and set future restocking plans. With the cloud making AI and machine learning (ML) scenarios more popular in recent years, you can use deep learning to build automatic solutions for inventory management and planning. Instead of relying on manual counting and recording, computer vision-based solutions can predict the brand and quantity of a product from an image.
Developing a custom model to analyze images is a significant undertaking that requires time, expertise, and resources, often taking months to complete. Additionally, it often requires thousands or tens of thousands of hand-labeled images to train the model to make accurate decisions. Generating this data can take months to gather and requires large teams of labelers to prepare it for use in ML.
This post demonstrates how to inventory soft drinks stored in a vertical refrigerator by automatically detecting products and highlighting which and how many products are visible (as in the following image). We build our solution with Amazon Rekognition Custom Labels.

This solution expedites your AI/ML journey because Amazon Rekognition Custom Labels doesn’t require deep AI/ML expertise, which enables developers to build diverse object detection and image classification use cases.
With Amazon Rekognition Custom Labels, you can identify the objects and scenes in images that are specific to your business needs. For example, you can find your logo in social media posts, identify your products on store shelves, classify machine parts in an assembly line, distinguish between healthy and infected plants, or detect animated characters in videos. Amazon Rekognition Custom Labels takes care of the heavy lifting for you.
To train an object detection model, we normally must collect hundreds of training images and annotate each image with bounding boxes around objects of interest. In the following example, we predefined eight soft drink classes and drew bounding boxes for all soft drink bottles.
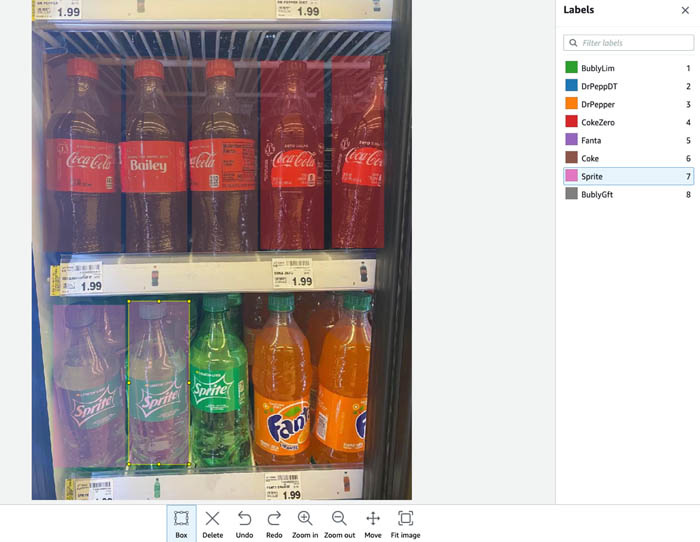
However, to scale this solution to other brands of soft drinks, we must collect extra training images for new brands, add annotations to the images, and retrain the model. Adding new brands leads to further labor and cost. Furthermore, you may must build a model dedicated to proprietary brands, which requires more effort and increases the time to market because of the additional time to train and detect new products. This makes it hard to share training datasets, and each user has to independently work on collecting training data.
The solution we propose in this post requires much less human annotation labor. First, we train an object detection model for general bottles and cans. Then we train a classification model to classify the brand of each bottle or can. Because soft drink bottles and cans are similar in shape, we can use public training datasets. You only need to train your own classification model dedicated to proprietary brands. Additionally, we show that annotation for classification is very easy with the automatic labeling feature from Amazon Rekognition Custom Labels.
Train on COCO and OID datasets with Amazon Rekognition Custom Labels
COCO is a popular ML dataset with 330,000 images covering 80 object categories. It’s widely used in image classification, object detection, and segmentation model trainings. OID is another public dataset, consisting of about 1.7 million images that have been annotated with bounding boxes spanning over 600 categories. COCO has training images for bottles, and OID provides the can class. We combine these two classes of images to train an object detection model that detects both bottles and cans.
Amazon Rekognition Custom Labels is a feature of Amazon Rekognition that enables customized ML model training specific to your business needs. To train a model from public datasets, we must first convert their annotations to manifest format, which is supported by Rekognition Custom Labels. For detailed instructions on converting COCO formatted annotation files into a manifest file, see COCO Format.
Similarly, we can convert an OID formatted annotation file to a manifest file with the following steps:
- Download OID dataset with the help of OIDv4_TooKit. For this post, I use the
Tin canclass. Every can image downloaded comes with an annotation file in the format of”name_of_the_class left top right bottom”. - With the Python class
cl_json_linefrom the COCO format conversion code, we can convert all the annotations saved in theLabelfolder into manifest format.
After we concatenate the manifest files converted from the COCO and OID datasets, we have our final training manifest file, which contains the general shape of bottles and cans.
- Upload all the local training images and the final manifest file into an Amazon Simple Storage Service (Amazon S3) bucket.
You’re now ready to train your model.
- Create a project and a dataset. For instructions, see Getting Started with Amazon Rekognition Custom Labels.
You create the training dataset by importing the manifest file via the Rekognition Custom Labels console.
- For Image location, select Import images labeled by Amazon SageMaker Ground Truth.
- For .manifest file location, enter the path to your S3 bucket. Make sure your source S3 bucket is correctly configured with Rekognition Custom Labels permissions.

- To train your model, select the dataset you created.
- Select Split training dataset.
- Choose Train.

- Wait for the model training to finish, and follow the console instructions to start the model and test it with the Amazon Rekognition API.
For more information, see Training an Amazon Rekognition Custom Labels Model.
When we feed an image into this object detection model, it locates each bottle and can with bounding box coordinates. We can crop each bounding box area and send it to the next classification model to determine which brand the cropped bottle or can is.

Train an image classification model with Amazon Rekognition Custom Labels
Training a classification model in Amazon Rekognition Custom Labels is easy with the automatic labeling feature for the training datasets.
Prepare the images on Amazon S3
Instead of assigning class labels to each image file (image-level annotation), you can organize the images by folder name, and upload all the folders into S3 buckets. Labels are automatically attached to images based on the folder they’re stored in. Now all we need to do is to collect sample images (which we search for on Google) for each soft drink brand and store them in an S3 bucket organized by folders.
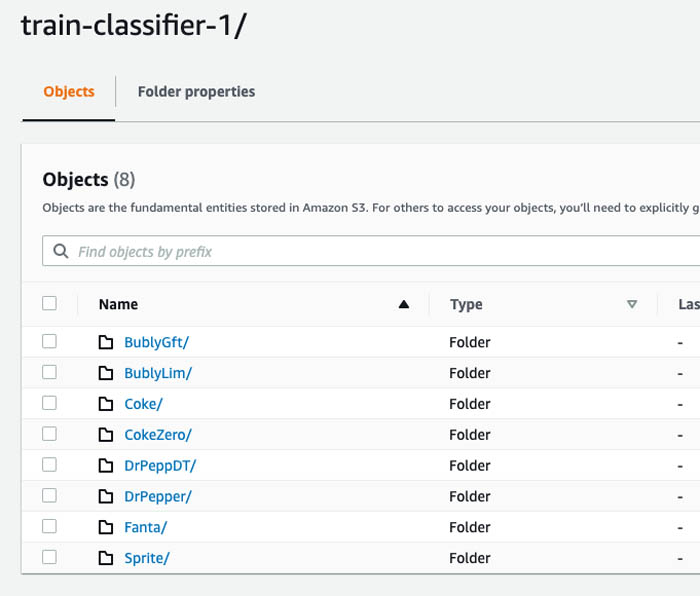
Import images into Amazon Rekognition Custom Labels
When you create a new dataset, select Import images from Amazon S3 bucket and specify the image folder location. When you select Automatically attach a label to my images based on the folder they’re stored in, classification annotations are automatically generated for all the images under the image folder.

Your dataset now has the images imported and they’re classified based on the S3 folders they’re stored in. The following screenshot shows the class names, which are the prefixes you created in Amazon S3 for your buckets.
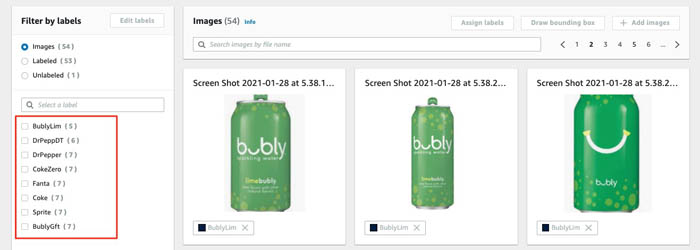
Train the model and analyze the training results
Train the model with similar steps to object detection model training. When the model finishes training, you can find the model performance on the Projects page of the Amazon Rekognition Custom Labels console. When you choose the project, you can find detailed metrics about the model performance and each label assigned. For more information about metrics, see Metrics for Evaluating Your Model.

With the classification model trained, you can apply it to the cropped images from the previous step and detect the brand of each bottle or can. Now we have a ML-based detector for drinks in a vertical refrigerator. The final result is a cropped output picture with soft drinks identified by bounding boxes and labeled by brand (the prefix of their S3 bucket).

Conclusion
In this post, we demonstrated how to implement an inventory detection method for products and brands through Amazon Rekognition Custom Labels, which reduces the heavy lifting to address AI/ML image detection and classification scenarios. This post also showed how to reduce the annotation effort when you need to add different products. You can use public training datasets and automatic labeling to accelerate your training data preparation.
You can easily experiment, iterate, and create your AI/ML model, and integrate with your application through the Amazon Rekognition APIs. For more information, see the Amazon Rekognition Custom Labels Guide.
About the Authors
 Kyle Huang is a Data Scientist in Solutions Prototyping team. His work focuses on providing AI/ML solutions for Global Accounts. Outside of work, Kyle likes endurance sports and is an Ironman finisher.
Kyle Huang is a Data Scientist in Solutions Prototyping team. His work focuses on providing AI/ML solutions for Global Accounts. Outside of work, Kyle likes endurance sports and is an Ironman finisher.
 Claudia Charro has been a Solutions Architect at AWS since 2015. She is focused on management tools and works with Consumer Packaged Goods (CPG) companies supporting their journeys to the AWS Cloud.
Claudia Charro has been a Solutions Architect at AWS since 2015. She is focused on management tools and works with Consumer Packaged Goods (CPG) companies supporting their journeys to the AWS Cloud.