Artificial Intelligence
Build text analytics solutions with Amazon Comprehend and Amazon Relational Database Service
Until now, being able to extract value from large volumes of unstructured or semi-structured content has been hard and required a machine learning (ML) background. Amazon Comprehend removes those barriers to entry and enables data engineers and developers easy access to rich, continuously trained, natural language processing services. You can build a complete analytics solution by joining analysis from Amazon Comprehend with relational business information to build valuable trend analysis. For example, you can understand what competitive products are most often mentioned in articles discussing your brand, product, or service. Customers can also join the sentiment of their customer feedback with customer profile information to better understand what types of customers react a specific way when you launch a new product.
The rapid growth of unstructured and semi-structured content like social media posts, news articles and everyday customer feedback being collected and stored in S3 has provided a great opportunity for valuable insights to be derived when it can be analyzed. Amazon Comprehend works seamlessly with the Amazon Relational Database Service (RDS). In this blog post, we will show you how to get started building rich text analytics views from your database, without having to learn anything about machine learning for natural language processing models.
We’ll do this by leveraging Amazon Comprehend, paired with Amazon Aurora-MySQL and AWS Lambda. These are integrated with a set of triggers in Aurora that are fired as data is inserted in order to determine the sentiment and store it back into the database. This can then be joined with additional data in your databases to help drive quicker insights. This same pattern can also be used to integrate other application level ML services, such as Amazon Translate, to translate the content itself.
Important -When not to use this pattern: The pattern is not meant for workloads with a high-rate insert calls (more than a few dozen inserted rows per second). We only recommend it for ad-hoc operations because these triggers are not asynchronous. Placing a Lambda function call behind an insert statement will add tens of milliseconds to each such statement. For high-traffic sources of data you should use a poll-aggregate-push approach to remove Lambda calls from your main insert write path.
Architecture
The following diagram shows the flow we are going to set up in this blog:
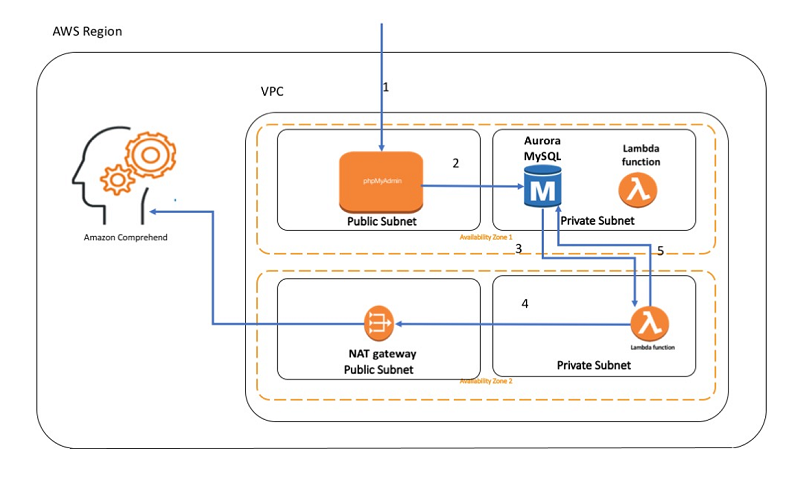
The arrows in the diagram show the following steps:
- Connect to phpMyAdmin, a web based admin tool for MySQL.
Important: We use phpMyAdmin for the purposes of ease of use for the readers. We do not recommend using phpMyAdmin unless you have enabled SSL/TLS in Apache. Otherwise, your database administrator password and other data are transmitted insecurely across the internet. - Insert new records into the Aurora MySQL database.
- A trigger, set to fire on INSERT, invokes a Lambda function.
- The Lambda function calls Amazon Comprehend to determine the sentiment of the text.
- The sentiment gets stored with the row in the table.
Setting it up
In the AWS Management Console, launch the CloudFormation Template.
![]()
Note: Don’t forget to select the key pair (you will have a different name). Also take note of the DB password.

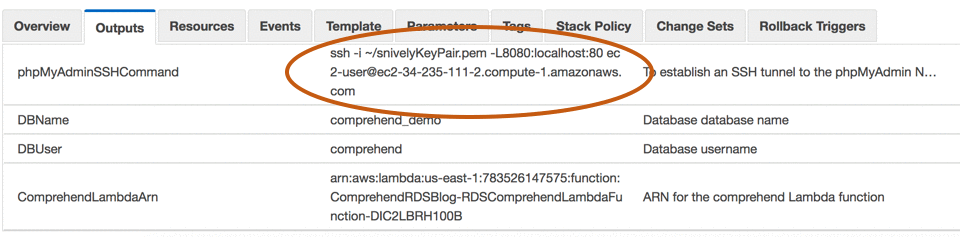
Wait until the script finishes. Usually it takes about 15 minutes to stand up the entire stack. The AWS CloudFormation script has an output that shows what the SSH command should look like, assuming that the keypair path is correct:
Setting up the database configuration
Set up the port forward so that we are hitting the local http port and connecting through SSH.
More details can be found here:
- After you set up the port forward, connect to the phpMyAdmin:
http://localhost:8080/phpMyAdmin/ - Next, log into phpMyAdmin. Use the username/password for the DB from the CloudFormation script config:

- Select SQL on the top navigation window:

- Let’s now create the review Table. Paste the following and choose Go:
This is to represent review information in our relational database, but it could be other text fields that need NLP performed on them.
- Now we’ll create the trigger that invokes our stored procedure when new data comes in. Select SQL up at the top again, paste the following, and choose Go:
- Lastly, we’ll create the stored procedure. Be sure to replace the Lambda function name that follows:
Note: You can find the Lambda ARN in the OUTPUTs of your CloudFormation script. It is the output labeled “ComprehendLambdaArn.”

Setting up IAM for the cluster
The CloudFormation script automatically sets up the parameter in the DB Cluster parameter group, but we left attaching the IAM permission to the cluster as a manual step in this exercise.
- Go to your cluster in the RDS console:
https://console.aws.amazon.com/rds/home?region=us-east-1#dbclusters - Select your cluster (may be named different based on your CloudFormation script) and select Manage IAM roles under Cluster actions:

- Then select the IAM role that CloudFormation created and apply it to the cluster:

Testing the integration
- Back on the phpMyAdmin window, select the SQL option again and paste in the following:

- Now select the table under comprehend_demo.Tables.ReviewInfo. You’ll notice we didn’t enter a Sentiment, but one got filled in. This was automatically determined through Amazon Comprehend.

Entering more example entries
Now run these commands in a SQL window. Paste them all and choose Go:

At this point, we’ve integrated Amazon Comprehend into our Aurora dataset using AWS Lambda and triggers.
Looking under the covers
In this section, we’ll take a look at what the Lambda function is doing. First thing you’ll notice is that it’s only 16 lines of code, including all the import statements.
The Lambda function gets invoked from our Aurora database in the Stored Procedure we created above. Specifically, these lines cause it to get invoked:
You’ll notice that this procedure is taking the ID and Text and creating a simple JSON object that gets passed to AWS Lambda. It’s an asynchronous call because we are using the lambda_async method rather than the lambda_sync.
Note: Starting with Amazon Aurora version 1.16, the stored procedure mysql.lambda_async is deprecated. If you are using Aurora version 1.16 or later, we strongly recommend that you work with native Lambda functions instead. For more information, see Working with Native Functions to Invoke a Lambda Function.
Within lambda, this is what gets passed to it:
We implemented the Lambda function using Python, which is using the Boto3 library to call Amazon Comprehend.
These four lines are all it takes to call Amazon Comprehend, perform NLP on the text, and pull the sentiment out:
After the function gets the sentiment back from the Amazon Comprehend service, the function simply takes that information and stores it back into the database. That can be done in a few additional lines:
Alternative option
Using an trigger to invoke Lambda is not meant for very high-rate insert workloads (more than a dozen inserts per second). We generally recommend the AWS Lambda integration for ad-hoc operations because triggers are not asynchronous. Placing a Lambda call behind an INSERT statement will add tens of milliseconds to each such statement. For high-traffic sources of data you should probably use a poll-aggregate-push approach to remove Lambda calls from your main INSERT write path.
Cleanup
After you are done testing the solution, deleting the CloudFormation stack will make it so that charges stop incurring. Simply delete the CloudFormation stack to clean up everything created in this blog post.
For detailed instructions on how delete a CloudFormation stack, see these instructions: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-console-delete-stack.html
Please note, in some rare cases, the VPC deletion will fail if the ENI is still allocated to the Lambda function and the delete times out. Simply wait approximately 15 minutes and re-delete. If this happens, everything that incurs a cost will also be deleted.
How much will this cost?
If you run this example for an hour in the us-east-1 AWS Region, it will cost you less than $0.50 USD. Most of the services leveraged actually fall into the Free Tier, but assuming worst case, we provide the following calculations:
| Item | Unit | Cost |
| EC2 for phpMyAdmin t2.medium |
1 hour @ 0.0464 per Hour
|
$0.0464 |
| EBS for phpMyAdmin | 8 GB gp2 @ $0.10 per GB-month of provisioned storage (billed per second) |
$0.00109589041
|
| Aurora MySQL compute | db.t2.small @ $0.041 hour | $0.041 |
| Aurora MySQL storage | $0.10 per GB-month | $0.10 |
| Aurora MySQL IOs | $0.20 per 1 million requests | $0.20 |
| Lambda Requests | 8 requests @ $0.0000002 per request. | $0.0000016 |
| Lambda Compute Time | 1 sec * 8 invokes @ 0.000000208 per 100 ms | $0.00001664 |
| Total Estimate: | ~$0.38 | |
Conclusion
With this simple approach, feedback stored as text can be automatically translated and/or enriched with advanced Amazon AI services. We demonstrated this leveraging the sentiment call, but this can easily be extended to extract topics, key phrases, translate, and many other functions.
Known limitations of sample code:
Right now our stored procedure in this blog post doesn’t escape reserved characters in the string value when in creating the JSON message. This can be modified if required in the call.
About the Authors
 Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
 Natasha Alexeeva is an AWS Senior Business Development Manager, focusing on artificial intelligence and machine learning. Her domain expertise is in health and life sciences industries. She enjoys building POCs for AWS clients who are interested in exploring the powers of AI.
Natasha Alexeeva is an AWS Senior Business Development Manager, focusing on artificial intelligence and machine learning. Her domain expertise is in health and life sciences industries. She enjoys building POCs for AWS clients who are interested in exploring the powers of AI.