Artificial Intelligence
Category: Amazon SageMaker

HyperPod enhances ML infrastructure with security and storage
This blog post introduces two major enhancements to Amazon SageMaker HyperPod that strengthen security and storage capabilities for large-scale machine learning infrastructure. The new features include customer managed key (CMK) support for encrypting EBS volumes with organization-controlled encryption keys, and Amazon EBS CSI driver integration that enables dynamic storage management for Kubernetes volumes in AI workloads.
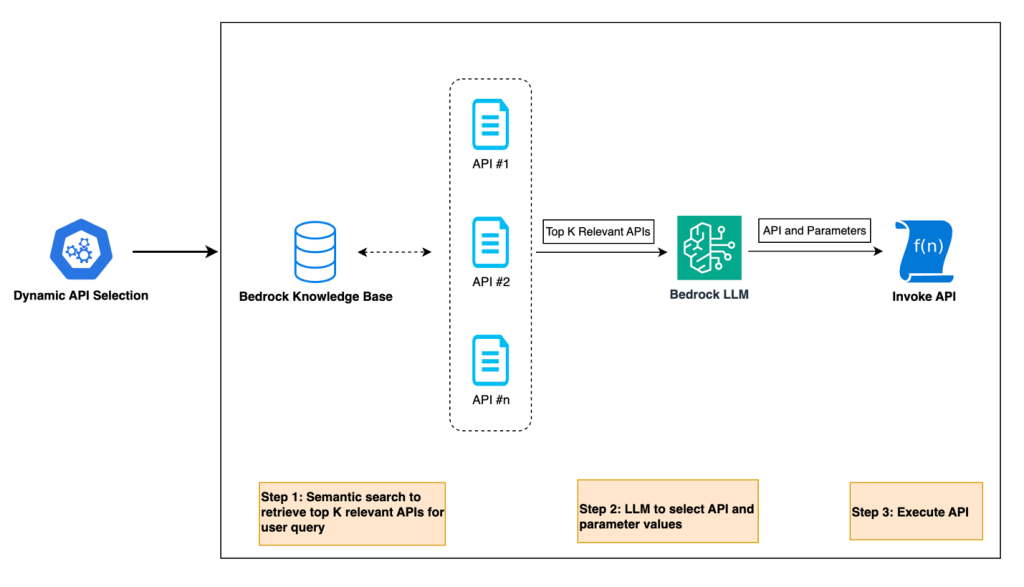
Harnessing the power of generative AI: Druva’s multi-agent copilot for streamlined data protection
Generative AI is transforming the way businesses interact with their customers and revolutionizing conversational interfaces for complex IT operations. Druva, a leading provider of data security solutions, is at the forefront of this transformation. In collaboration with Amazon Web Services (AWS), Druva is developing a cutting-edge generative AI-powered multi-agent copilot that aims to redefine the customer experience in data security and cyber resilience.
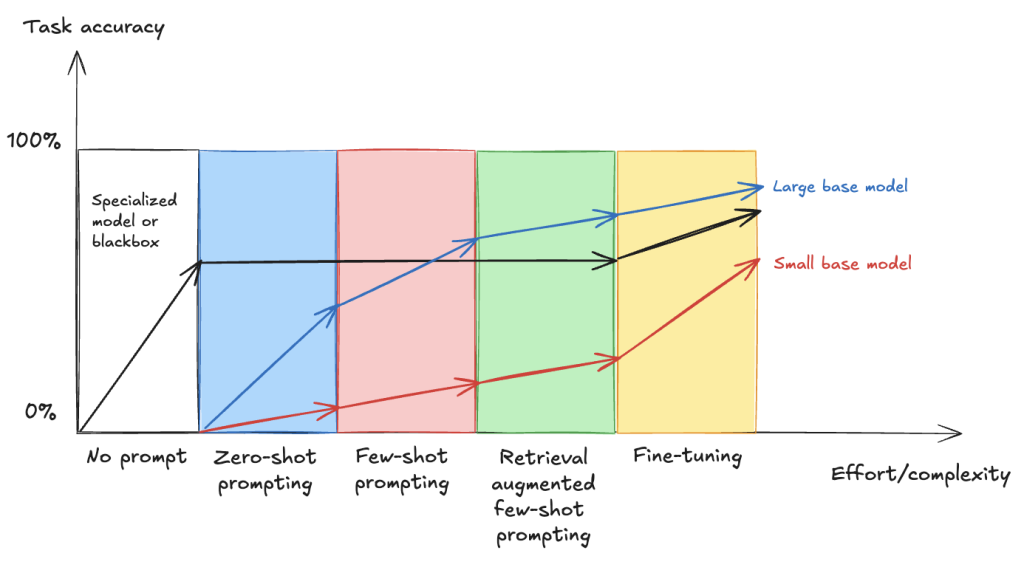
Fine-tune VLMs for multipage document-to-JSON with SageMaker AI and SWIFT
In this post, we demonstrate that fine-tuning VLMs provides a powerful and flexible approach to automate and significantly enhance document understanding capabilities. We also demonstrate that using focused fine-tuning allows smaller, multi-modal models to compete effectively with much larger counterparts (98% accuracy with Qwen2.5 VL 3B).
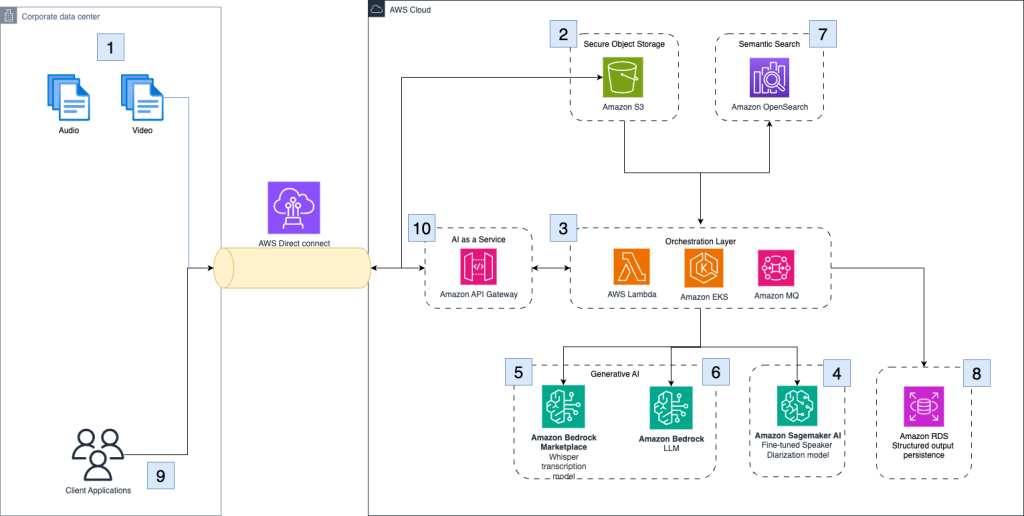
How Clario automates clinical research analysis using generative AI on AWS
In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews.
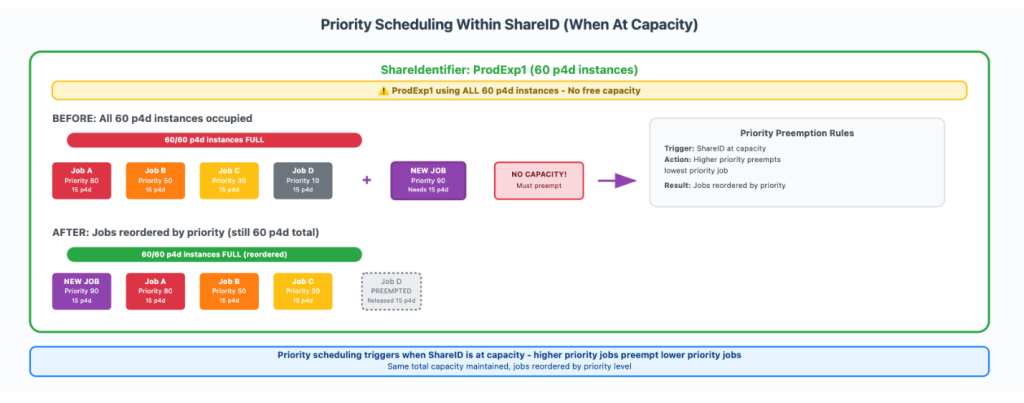
How Amazon Search increased ML training twofold using AWS Batch for Amazon SageMaker Training jobs
In this post, we show you how Amazon Search optimized GPU instance utilization by leveraging AWS Batch for SageMaker Training jobs. This managed solution enabled us to orchestrate machine learning (ML) training workloads on GPU-accelerated instance families like P5, P4, and others. We will also provide a step-by-step walkthrough of the use case implementation.
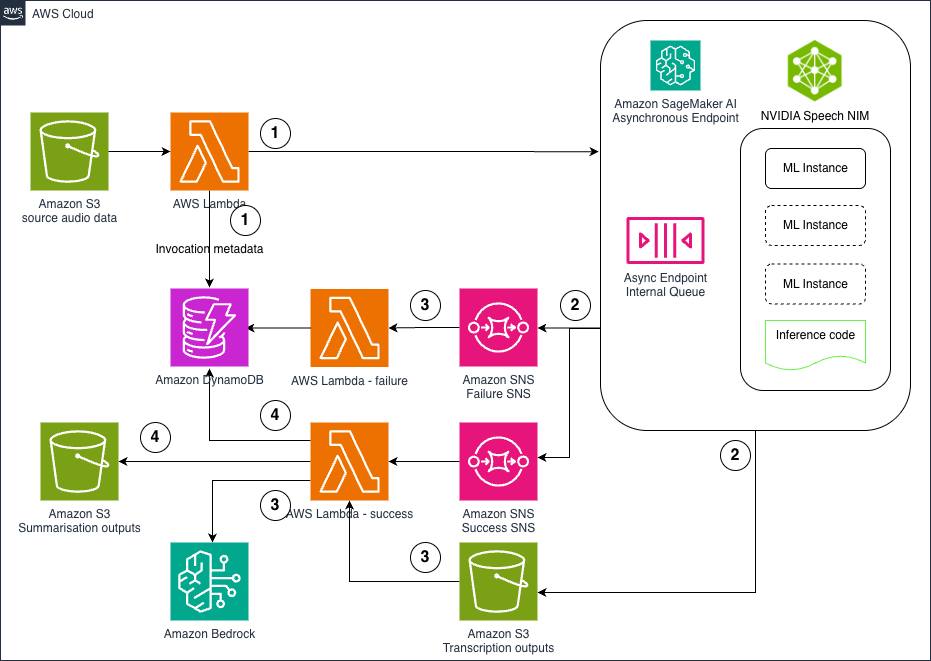
Hosting NVIDIA speech NIM models on Amazon SageMaker AI: Parakeet ASR
In this post, we explore how to deploy NVIDIA’s Parakeet ASR model on Amazon SageMaker AI using asynchronous inference endpoints to create a scalable, cost-effective pipeline for processing large volumes of audio data. The solution combines state-of-the-art speech recognition capabilities with AWS managed services like Lambda, S3, and Bedrock to automatically transcribe audio files and generate intelligent summaries, enabling organizations to unlock valuable insights from customer calls, meeting recordings, and other audio content at scale .
Serverless deployment for your Amazon SageMaker Canvas models
In this post, we walk through how to take an ML model built in SageMaker Canvas and deploy it using SageMaker Serverless Inference, helping you go from model creation to production-ready predictions quickly and efficiently without managing any infrastructure. This solution demonstrates a complete workflow from adding your trained model to the SageMaker Model Registry through creating serverless endpoint configurations and deploying endpoints that automatically scale based on demand .
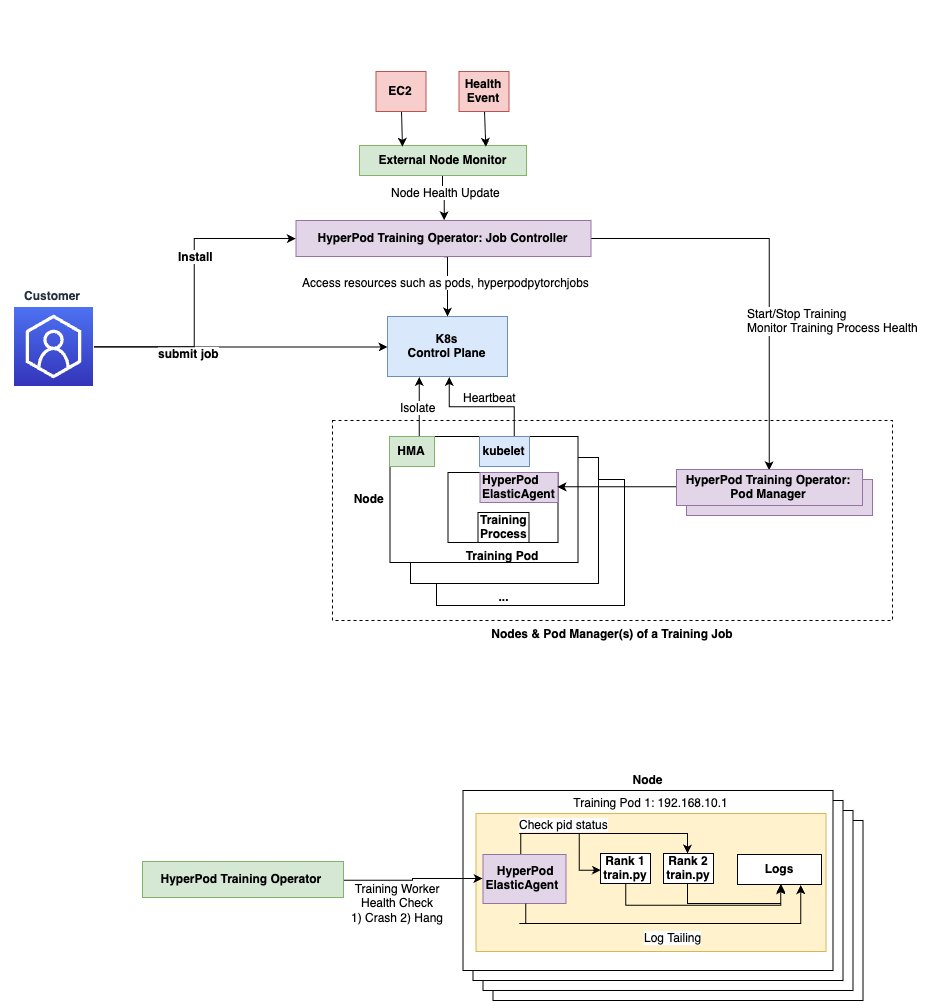
Accelerate large-scale AI training with Amazon SageMaker HyperPod training operator
In this post, we demonstrate how to deploy and manage machine learning training workloads using the Amazon SageMaker HyperPod training operator, which enhances training resilience for Kubernetes workloads through pinpoint recovery and customizable monitoring capabilities. The Amazon SageMaker HyperPod training operator helps accelerate generative AI model development by efficiently managing distributed training across large GPU clusters, offering benefits like centralized training process monitoring, granular process recovery, and hanging job detection that can reduce recovery times from tens of minutes to seconds.

Splash Music transforms music generation using AWS Trainium and Amazon SageMaker HyperPod
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.

Scala development in Amazon SageMaker Studio with Almond kernel
This post provides a comprehensive guide on integrating the Almond kernel into SageMaker Studio, offering a solution for Scala development within the platform.