Artificial Intelligence
Category: Learning Levels
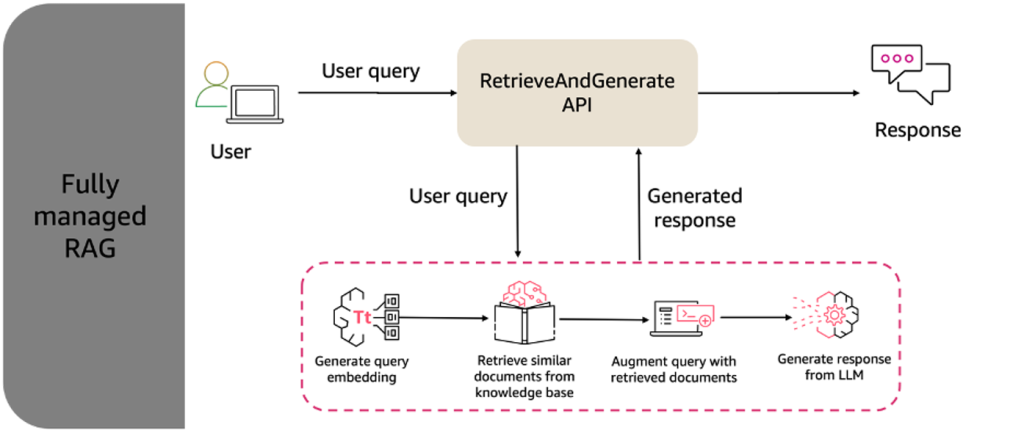
Demystifying Amazon Bedrock Pricing for a Chatbot Assistant
In this post, we’ll look at Amazon Bedrock pricing through the lens of a practical, real-world example: building a customer service chatbot. We’ll break down the essential cost components, walk through capacity planning for a mid-sized call center implementation, and provide detailed pricing calculations across different foundation models.

Automate enterprise workflows by integrating Salesforce Agentforce with Amazon Bedrock Agents
This post explores a practical collaboration, integrating Salesforce Agentforce with Amazon Bedrock Agents and Amazon Redshift, to automate enterprise workflows.

Responsible AI for the payments industry – Part 1
This post explores the unique challenges facing the payments industry in scaling AI adoption, the regulatory considerations that shape implementation decisions, and practical approaches to applying responsible AI principles. In Part 2, we provide practical implementation strategies to operationalize responsible AI within your payment systems.

Responsible AI for the payments industry – Part 2
In Part 1 of our series, we explored the foundational concepts of responsible AI in the payments industry. In this post, we discuss the practical implementation of responsible AI frameworks.

Discover insights from Microsoft Exchange with the Microsoft Exchange connector for Amazon Q Business
Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge. With Amazon Q Business, you can quickly find answers to questions, generate summaries and content, and complete tasks by using the information and expertise stored across your company’s various data sources and enterprise systems. […]
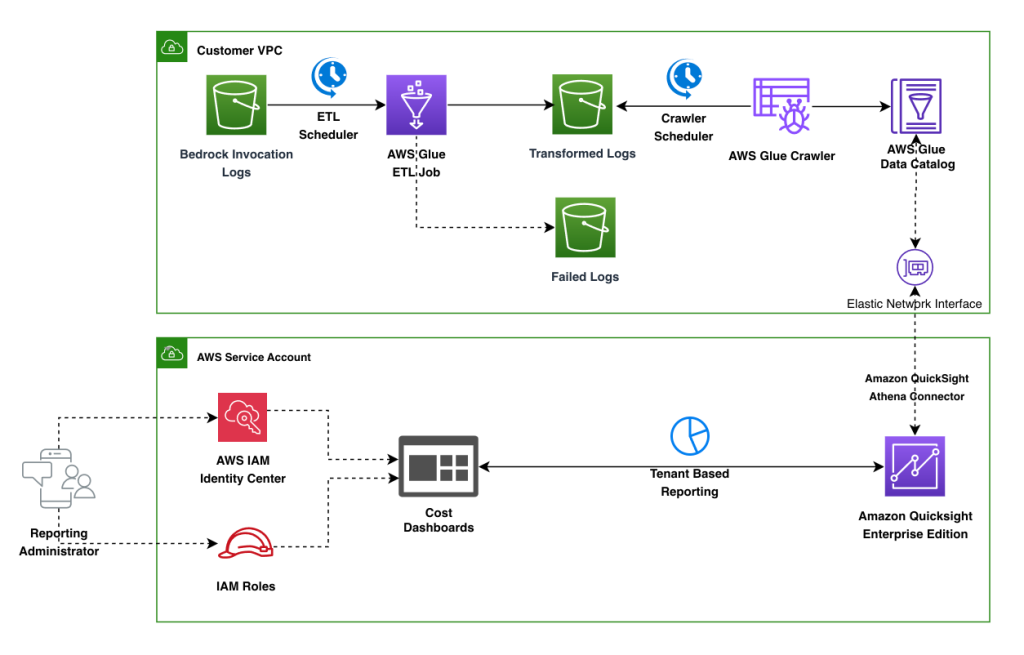
Cost tracking multi-tenant model inference on Amazon Bedrock
In this post, we demonstrate how to track and analyze multi-tenant model inference costs on Amazon Bedrock using the Converse API’s requestMetadata parameter. The solution includes an ETL pipeline using AWS Glue and Amazon QuickSight dashboards to visualize usage patterns, token consumption, and cost allocation across different tenants and departments.

Building an AI-driven course content generation system using Amazon Bedrock
In this post, we explore each component in detail, along with the technical implementation of the two core modules: course outline generation and course content generation.

Building AIOps with Amazon Q Developer CLI and MCP Server
In this post, we discuss how to implement a low-code no-code AIOps solution that helps organizations monitor, identify, and troubleshoot operational events while maintaining their security posture. We show how these technologies work together to automate repetitive tasks, streamline incident response, and enhance operational efficiency across your organization.
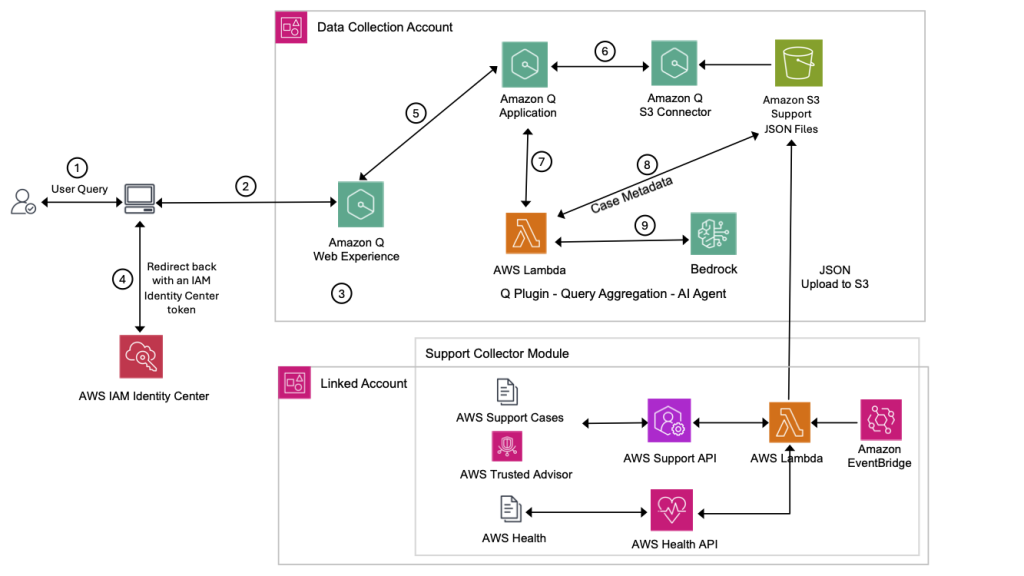
AI agents unifying structured and unstructured data: Transforming support analytics and beyond with Amazon Q Plugins
Learn how to enhance Amazon Q with custom plugins to combine semantic search capabilities with precise analytics for AWS Support data. This solution enables more accurate answers to analytical questions by integrating structured data querying with RAG architecture, allowing teams to transform raw support cases and health events into actionable insights. Discover how this enhanced architecture delivers exact numerical analysis while maintaining natural language interactions for improved operational decision-making.
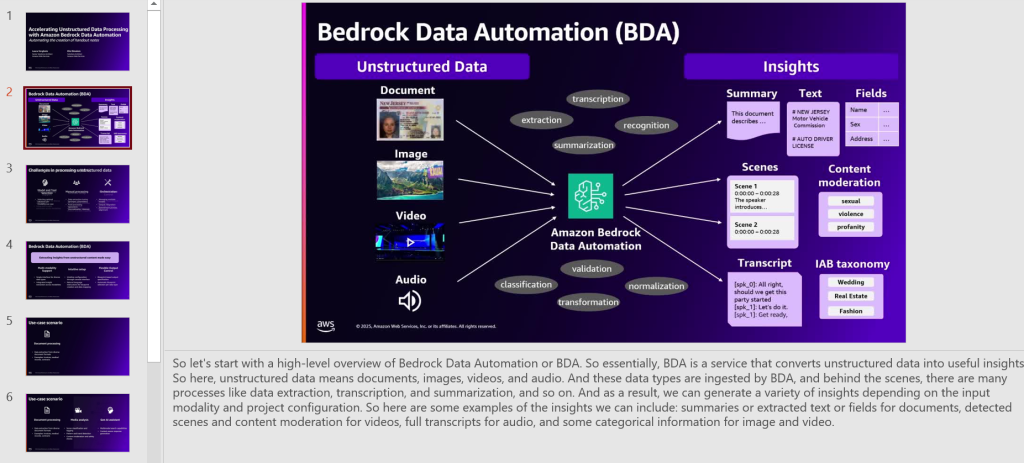
Automate the creation of handout notes using Amazon Bedrock Data Automation
In this post, we show how you can build an automated, serverless solution to transform webinar recordings into comprehensive handouts using Amazon Bedrock Data Automation for video analysis. We walk you through the implementation of Amazon Bedrock Data Automation to transcribe and detect slide changes, as well as the use of Amazon Bedrock foundation models (FMs) for transcription refinement, combined with custom AWS Lambda functions orchestrated by AWS Step Functions.