AWS Machine Learning Blog
Category: Technical How-to

Host ML models on Amazon SageMaker using Triton: TensorRT models
Sometimes it can be very beneficial to use tools such as compilers that can modify and compile your models for optimal inference performance. In this post, we explore TensorRT and how to use it with Amazon SageMaker inference using NVIDIA Triton Inference Server. We explore how TensorRT works and how to host and optimize these […]

Build an image search engine with Amazon Kendra and Amazon Rekognition
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Specifically, we use the example of architecture diagrams for complex images due to their incorporation of numerous different visual icons and text. With the internet, searching and obtaining an image has never been easier. Most […]

Automate the deployment of an Amazon Forecast time-series forecasting model
Time series forecasting refers to the process of predicting future values of time series data (data that is collected at regular intervals over time). Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such […]

Get started with generative AI on AWS using Amazon SageMaker JumpStart
Generative AI is gaining a lot of public attention at present, with talk around products such as GPT4, ChatGPT, DALL-E2, Bard, and many other AI technologies. Many customers have been asking for more information on AWS’s generative AI solutions. The aim of this post is to address those needs. This post provides an overview of […]

Optimized PyTorch 2.0 inference with AWS Graviton processors
New generations of CPUs offer a significant performance improvement in machine learning (ML) inference due to specialized built-in instructions. Combined with their flexibility, high speed of development, and low operating cost, these general-purpose processors offer an alternative to other existing hardware solutions. AWS, Arm, Meta and others helped optimize the performance of PyTorch 2.0 inference […]

Hosting ML Models on Amazon SageMaker using Triton: XGBoost, LightGBM, and Treelite Models
One of the most popular models available today is XGBoost. With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. In this post, we dive deep to see how Amazon SageMaker can serve these models using NVIDIA Triton […]

Run your local machine learning code as Amazon SageMaker Training jobs with minimal code changes
We recently introduced a new capability in the Amazon SageMaker Python SDK that lets data scientists run their machine learning (ML) code authored in their preferred integrated developer environment (IDE) and notebooks along with the associated runtime dependencies as Amazon SageMaker training jobs with minimal code changes to the experimentation done locally. Data scientists typically […]

Perform intelligent search across emails in your Google workspace using the Gmail connector for Amazon Kendra
Many organizations use Gmail for their business email needs. Gmail for Business is part of Google Workspace, which provides a set of productivity and collaboration tools like Google Drive, Google Docs, Google Sheets, and more. For any organization, emails contain a wealth of information, which could be within the subject of an email, the message […]

Create SageMaker Pipelines for training, consuming and monitoring your batch use cases
Batch inference is a common pattern where prediction requests are batched together on input, a job runs to process those requests against a trained model, and the output includes batch prediction responses that can then be consumed by other applications or business functions. Running batch use cases in production environments requires a repeatable process for […]
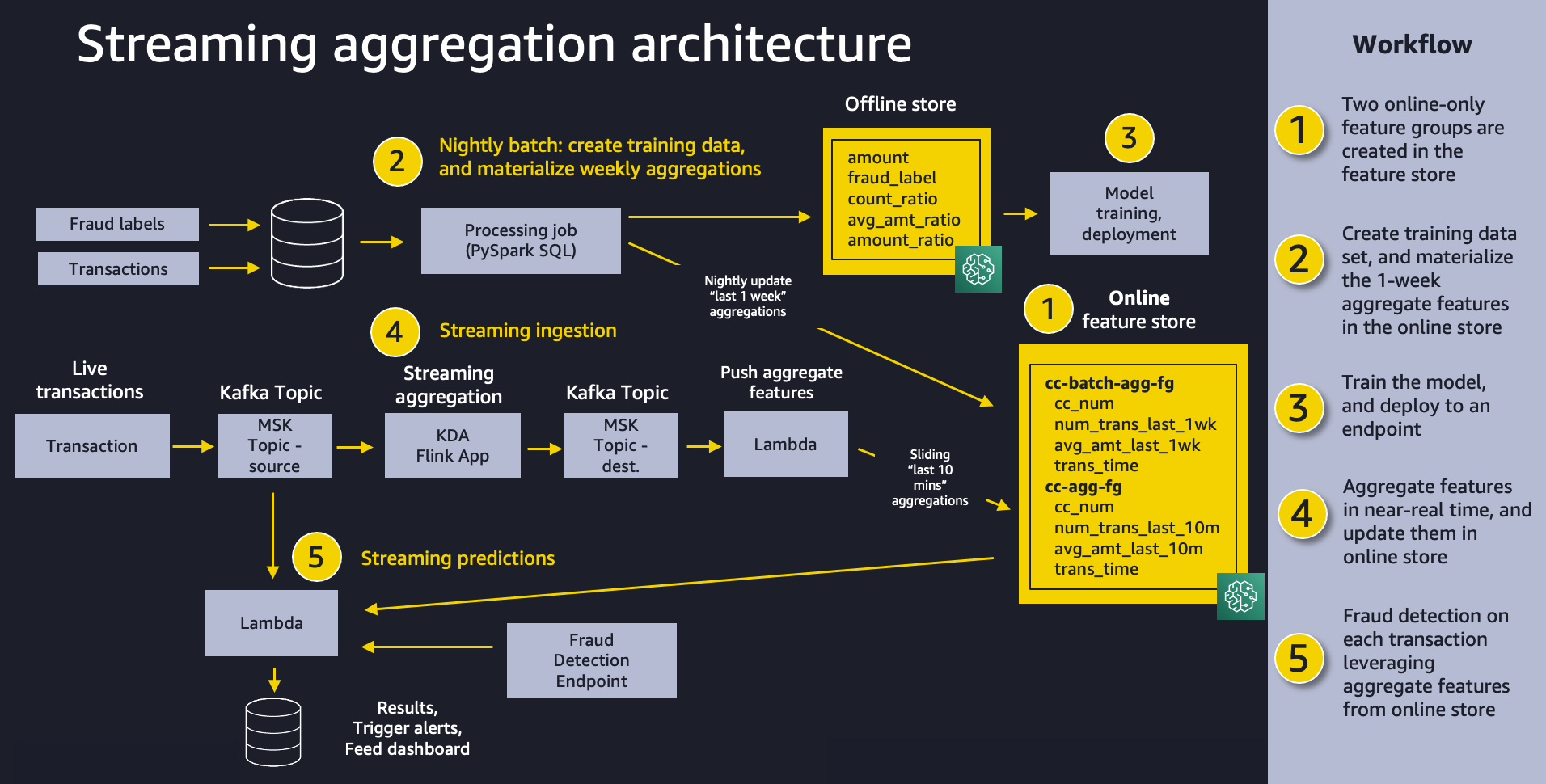
Use streaming ingestion with Amazon SageMaker Feature Store and Amazon MSK to make ML-backed decisions in near-real time
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products […]