Artificial Intelligence
Connect Amazon EMR and RStudio on Amazon SageMaker
RStudio on Amazon SageMaker is the industry’s first fully managed RStudio Workbench integrated development environment (IDE) in the cloud. You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale.
In conjunction with tools like RStudio on SageMaker, users are analyzing, transforming, and preparing large amounts of data as part of the data science and ML workflow. Data scientists and data engineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing. Using RStudio on SageMaker and Amazon EMR together, you can continue to use the RStudio IDE for analysis and development, while using Amazon EMR managed clusters for larger data processing.
In this post, we demonstrate how you can connect your RStudio on SageMaker domain with an EMR cluster.
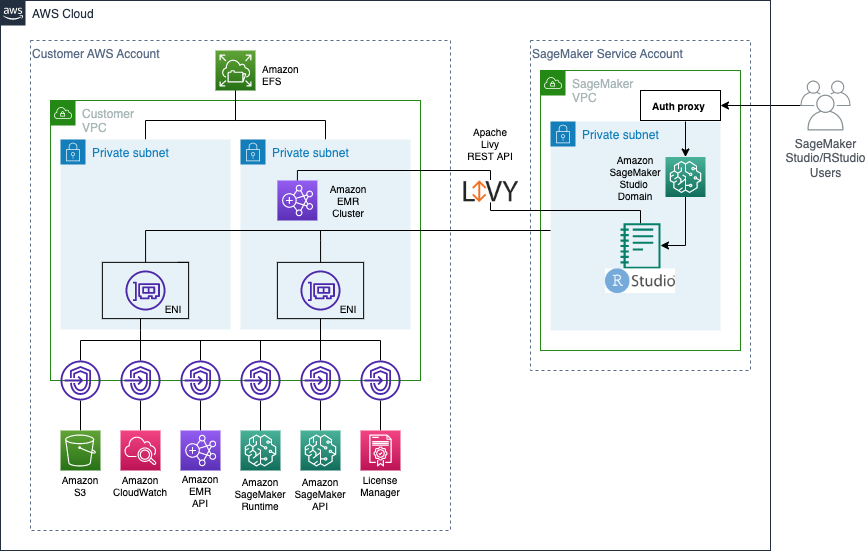
Solution overview
We use an Apache Livy connection to submit a sparklyr job from RStudio on SageMaker to an EMR cluster. This is demonstrated in the following diagram.

All code demonstrated in the post is available in our GitHub repository. We implement the following solution architecture.
Prerequisites
Prior to deploying any resources, make sure you have all the requirements for setting up and using RStudio on SageMaker and Amazon EMR:
- An RStudio Workbench license
- An AWS Identity and Access Management (IAM) role with Amazon EMR permissions
We’ll also build a custom RStudio on SageMaker image, so ensure you have Docker running and all required permissions. For more information, refer to Use a custom image to bring your own development environment to RStudio on Amazon SageMaker.
Create resources with AWS CloudFormation
We use an AWS CloudFormation stack to generate the required infrastructure.
If you already have an RStudio domain and an existing EMR cluster, you can skip this step and start building your custom RStudio on SageMaker image. Substitute the information of your EMR cluster and RStudio domain in place of the EMR cluster and RStudio domain created in this section.
Launching this stack creates the following resources:
- Two private subnets
- EMR Spark cluster
- AWS Glue database and tables
- SageMaker domain with RStudio
- SageMaker RStudio user profile
- IAM service role for the SageMaker RStudio domain
- IAM service role for the SageMaker RStudio user profile
Complete the following steps to create your resources:
Choose Launch Stack to create the stack.
![]()
- On the Create stack page, choose Next.
- On the Specify stack details page, provide a name for your stack and leave the remaining options as default, then choose Next.
- On the Configure stack options page, leave the options as default and choose Next.
- On the Review page, select
- I acknowledge that AWS CloudFormation might create IAM resources with custom names and
- I acknowledge that AWS CloudFormation might require the following capability: CAPABILITY_AUTO_EXPAND.
- Choose Create stack.

The template generates five stacks.

To see the EMR Spark cluster that was created, navigate to the Amazon EMR console. You will see a cluster created for you called sagemaker. This is the cluster we connect to through RStudio on SageMaker.

Build the custom RStudio on SageMaker image
We have created a custom image that will install all the dependencies of sparklyr, and will establish a connection to the EMR cluster we created.
If you’re using your own EMR cluster and RStudio domain, modify the scripts accordingly.
Make sure Docker is running. Start by getting into our project repository:
We will now build the Docker image and register it to our RStudio on SageMaker domain.
- On the SageMaker console, choose Domains in the navigation pane.
- Choose the domain
select rstudio-domain. - On the Environment tab, choose Attach image.

Now we attach the sparklyr image that we created earlier to the domain. - For Choose image source, select Existing image.
- Select the sparklyr image we built.

- For Image properties, leave the options as default.
- For Image type, select RStudio image.
- Choose Submit.

Validate the image has been added to the domain. It may take a few minutes for the image to attach fully.

- When it’s available, log in to the RStudio on SageMaker console using the
rstudio-userprofile that was created. - From here, create a session with the sparklyr image that we created earlier.

First, we have to connect to our EMR cluster. - In the connections pane, choose New Connection.
- Select the EMR cluster connect code snippet and choose Connect to Amazon EMR Cluster.

After the connect code has run, you will see a Spark connection through Livy, but no tables.

- Change the database to
credit_card:
tbl_change_db(sc, “credit_card”) - Choose Refresh Connection Data.
You can now see the tables.

- Now navigate to the
rstudio-sparklyr-code-walkthrough.mdfile.
This has a set of Spark transformations we can use on our credit card dataset to prepare it for modeling. The following code is an excerpt:
Let’s count() how many transactions are in the transactions table. But first we need to cache Use the tbl() function.
Let’s run a count of the number of rows for each table.
Now let’s register our tables as Spark Data Frames and pull them into the cluster-wide in memory cache for better performance. We will also filter the header that gets placed in the first row for each table.
To see the full list of commands, refer to the rstudio-sparklyr-code-walkthrough.md file.
Clean up
To clean up any resources to avoid incurring recurring costs, delete the root CloudFormation template. Also delete all Amazon Elastic File Service (Amazon EFS) mounts created and any Amazon Simple Storage Service (Amazon S3) buckets and objects created.
Conclusion
The integration of RStudio on SageMaker with Amazon EMR provides a powerful solution for data analysis and modeling tasks in the cloud. By connecting RStudio on SageMaker and establishing a Livy connection to Spark on EMR, you can take advantage of the computing resources of both platforms for efficient processing of large datasets. RStudio, one of the most widely used IDEs for data analysis, allows you to take advantage of the fully managed infrastructure, access control, networking, and security capabilities of SageMaker. Meanwhile, the Livy connection to Spark on Amazon EMR provides a way to perform distributed processing and scaling of data processing tasks.
If you’re interested in learning more about using these tools together, this post serves as a starting point. For more information, refer to RStudio on Amazon SageMaker. If you have any suggestions or feature improvements, please create a pull request on our GitHub repo or leave a comment on this post!
About the Authors

Ryan Garner is a Data Scientist with AWS Professional Services. He is passionate about helping AWS customers use R to solve their Data Science and Machine Learning problems.
 Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
 Saiteja Pudi is a Solutions Architect at AWS, based in Dallas, Tx. He has been with AWS for more than 3 years now, helping customers derive the true potential of AWS by being their trusted advisor. He comes from an application development background, interested in Data Science and Machine Learning.
Saiteja Pudi is a Solutions Architect at AWS, based in Dallas, Tx. He has been with AWS for more than 3 years now, helping customers derive the true potential of AWS by being their trusted advisor. He comes from an application development background, interested in Data Science and Machine Learning.
{kind=link}