Artificial Intelligence
Improve governance of your machine learning models with Amazon SageMaker
As companies are increasingly adopting machine learning (ML) for their mainstream enterprise applications, more of their business decisions are influenced by ML models. As a result of this, having simplified access control and enhanced transparency across all your ML models makes it easier to validate that your models are performing well and take action when they are not.
In this post, we explore how companies can improve visibility into their models with centralized dashboards and detailed documentation of their models using two new features: SageMaker Model Cards and the SageMaker Model Dashboard. Both these features are available at no additional charge to SageMaker customers.
Overview of model governance
Model governance is a framework that gives systematic visibility into model development, validation, and usage. Model governance is applicable across the end-to-end ML workflow, starting from identifying the ML use case to ongoing monitoring of a deployed model through alerts, reports, and dashboards. A well-implemented model governance framework should minimize the number of interfaces required to view, track, and manage lifecycle tasks to make it easier to monitor the ML lifecycle at scale.
Today, organizations invest significant technical expertise into building tooling to automate large portions of their governance and auditability workflow. For example, model builders need to proactively record model specifications such as intended use for a model, risk rating, and performance criteria a model should be measured against. Furthermore, they also need to record observations on model behavior, and document the reason they made certain key decisions such as the objective function they optimized the model against.
It’s common for companies to use tools like Excel or email to capture and share such model information for use in approvals for production usage. But as the scale of ML development increases, information can be easily lost or misplaced, and keeping track of these details becomes infeasible quickly. Furthermore, after these models are deployed, you might stitch together data from various sources to gain end-to-end visibility into all your models, endpoints, monitoring history, and lineage. Without such a view, you can easily lose track of your models, and may not be aware of when you need to take action on them. This issue is intensified in highly regulated industries because you’re subject to regulations that require you to keep such measures in place.
As the volume of models starts to scale, managing custom tooling can become a challenge and gives organizations less time to focus on core business needs. In the following sections, we explore how SageMaker Model Cards and the SageMaker Model Dashboard can help you scale your governance efforts.
SageMaker Model Cards
Model cards enable you to standardize how models are documented, thereby achieving visibility into the lifecycle of a model, from designing, building, training, and evaluation. Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. They provide a factsheet of the model that is important for model governance.
Model cards allow users to author and store decisions such as why an objective function was chosen for optimization, and details such as intended usage and risk rating. You can also attach and review evaluation results, and jot down observations for future reference.
For models trained on SageMaker, Model cards can discover and auto-populate details such as training job, training datasets, model artifacts, and inference environment, thereby accelerating the process of creating the cards. With the SageMaker Python SDK, you can seamlessly update the Model card with evaluation metrics.
Model cards provide model risk managers, data scientists, and ML engineers the ability to perform the following tasks:
- Document model requirements such as risk rating, intended usage, limitations, and expected performance
- Auto-populate Model cards for SageMaker trained models
- Bring your own info (BYOI) for non-SageMaker models
- Upload and share model and data evaluation results
- Define and capture custom information
- Capture Model card status (draft, pending review, or approved for production)
- Access the Model card hub from the AWS Management Console
- Create, edit, view, export, clone, and delete Model cards
- Trigger workflows using Amazon EventBridge integration for Model card status change events
Create SageMaker Model Cards using the console
You can easily create Model cards using the SageMaker console. Here you can see all the existing Model cards and create new ones as needed.
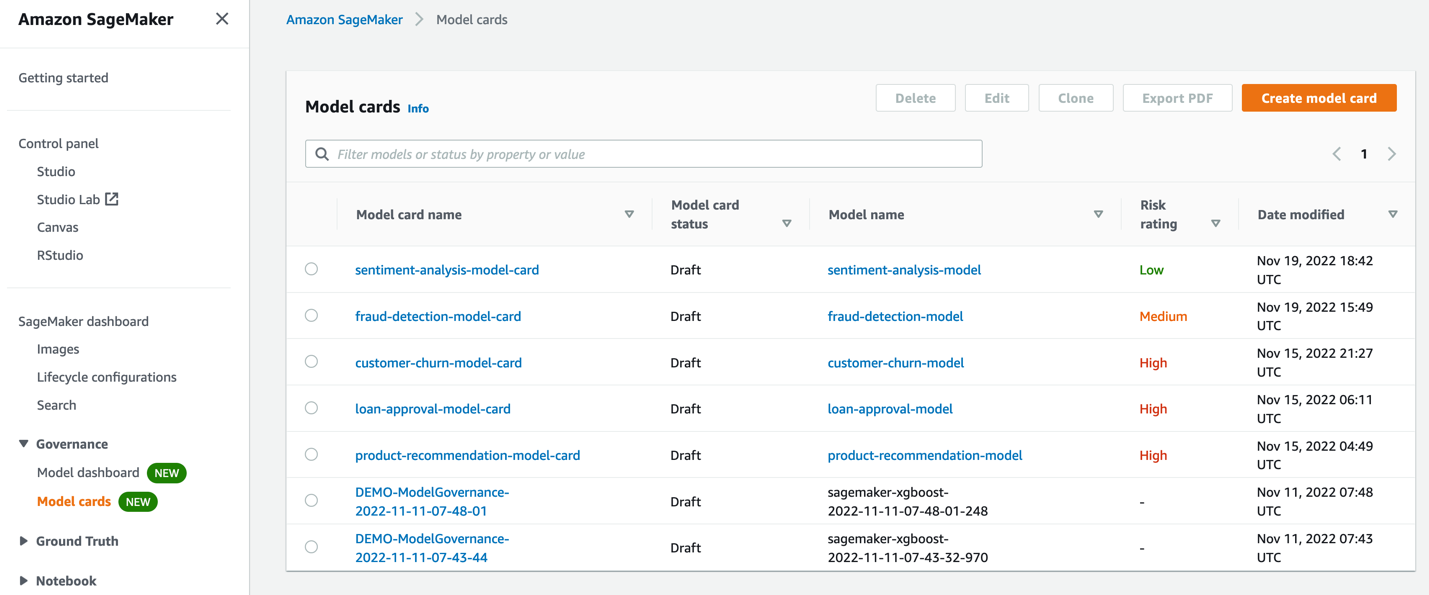
When creating a Model card, you can document critical model information such as who built the model, why it was developed, how it is performing for independent evaluations, and any observations that need to be considered prior to using the model for a business application.
To create a Model card on the console, complete the following steps:
- Enter model overview details.
- Enter training details (auto-populated if the model was trained on SageMaker).
- Upload evaluation results.
- Add additional details such as recommendations and ethical considerations.
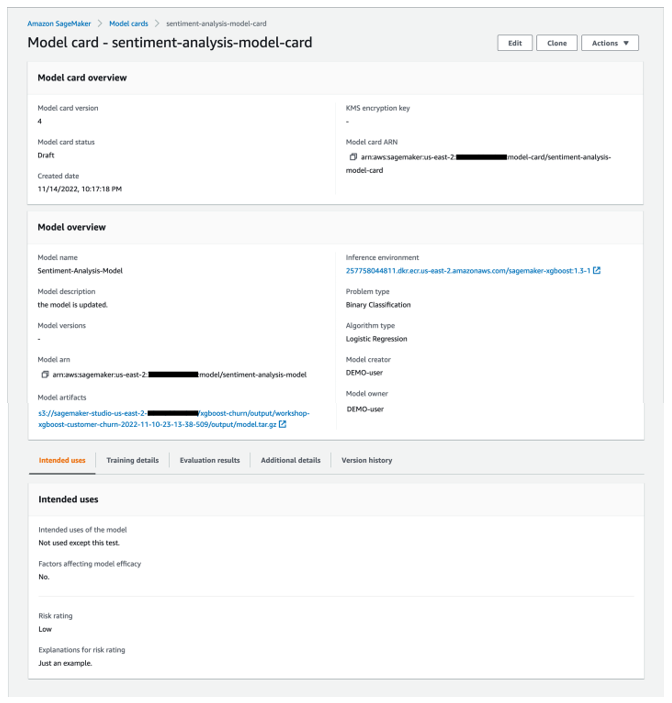
After you create the Model card, you can choose a version to view it.

The following screenshot shows the details of our Model card.
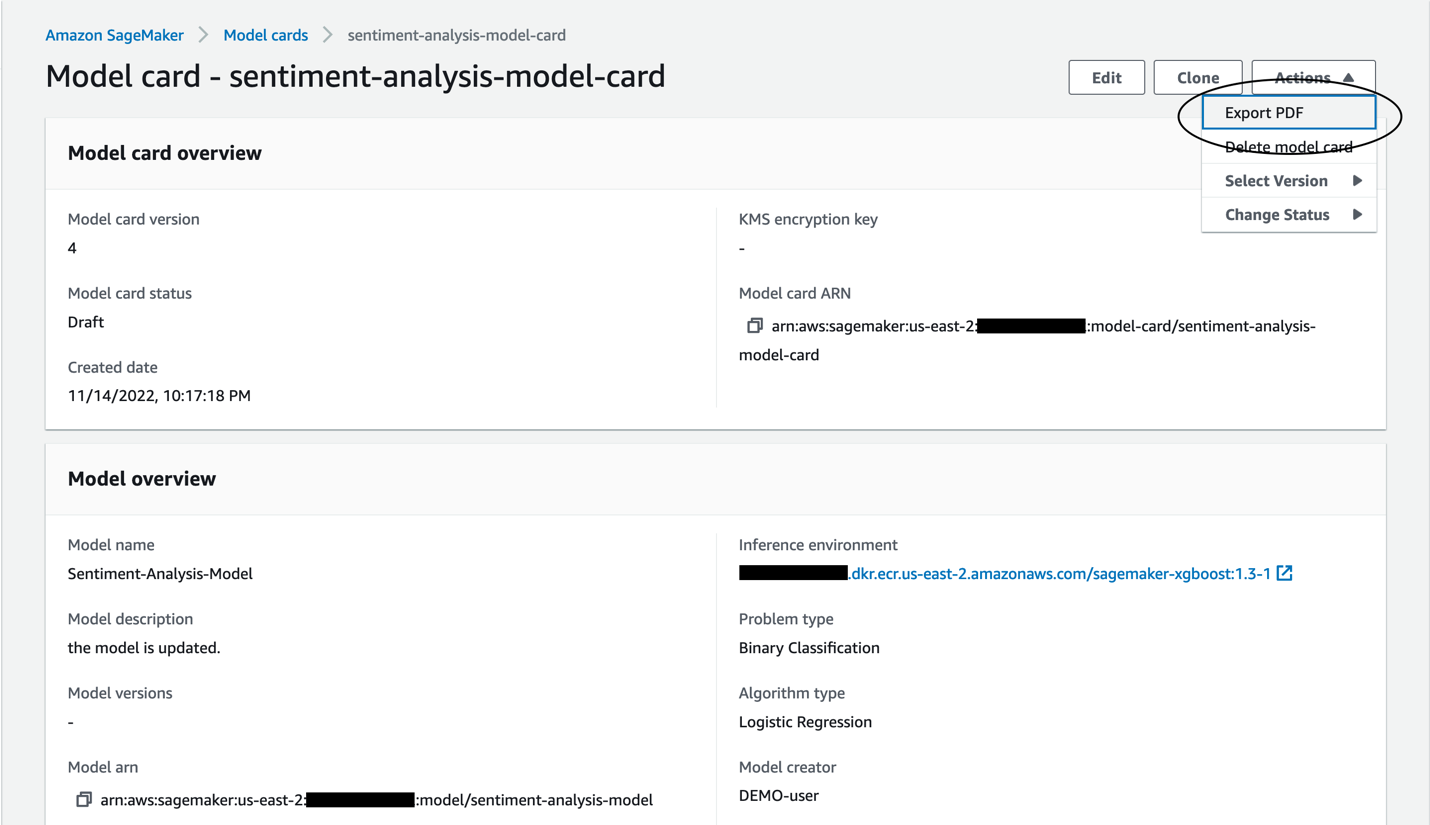
You can also export the Model card to be shared as a PDF.
Create and explore SageMaker Model Cards through the SageMaker Python SDK
Interacting with Model cards isn’t limited to the console. You can also use the SageMaker Python SDK to create and explore Model cards. The SageMaker Python SDK allows data scientists and ML engineers to easily interact with SageMaker components. The following code snippets showcase the process to create a Model card using the newly added SageMaker Python SDK functionality.
Make sure you have the latest version of the SageMaker Python SDK installed:
Once you have trained and deployed a model using SageMaker, you can use the information from the SageMaker model and the training job to automatically populate information into the Model card.
Using the SageMaker Python SDK and passing the SageMaker model name, we can automatically collect basic model information. Information such as the SageMaker model ARN, training environment, and model output Amazon Simple Storage Service (Amazon S3) location is all automatically populated. We can add other model facts, such as description, problem type, algorithm type, model creator, and owner. See the following code:
We can also automatically collect basic training information like training job ARN, training environment and training metrics. Additional training details can be added, like training objective function and observations. See the following code:
If we have evaluation metrics available, we can add those to the Model card as well:
We can also add additional information about the model that can help with model governance:
After we have provided all the details we require, we can create the Model card using the preceding configuration:
The SageMaker SDK also provides the ability to update, load, list, export, and delete a Model card.
To learn more about Model cards, refer to the developer guide and follow this example notebook to get started.
SageMaker Model Dashboard
The Model dashboard is a centralized repository of all models that have been created in the account. The models are usually created by training on SageMaker, or you can bring your models trained elsewhere to host on SageMaker.
The Model dashboard provides a single interface for IT administrators, model risk managers, or business leaders to view all deployed models and how they’re performing. You can view your endpoints, batch transform jobs, and monitoring jobs to get insights into model performance. Organizations can dive deep to identify which models have missing or inactive monitors and add them using SageMaker APIs to ensure all models are being checked for data drift, model drift, bias drift, and feature attribution drift.
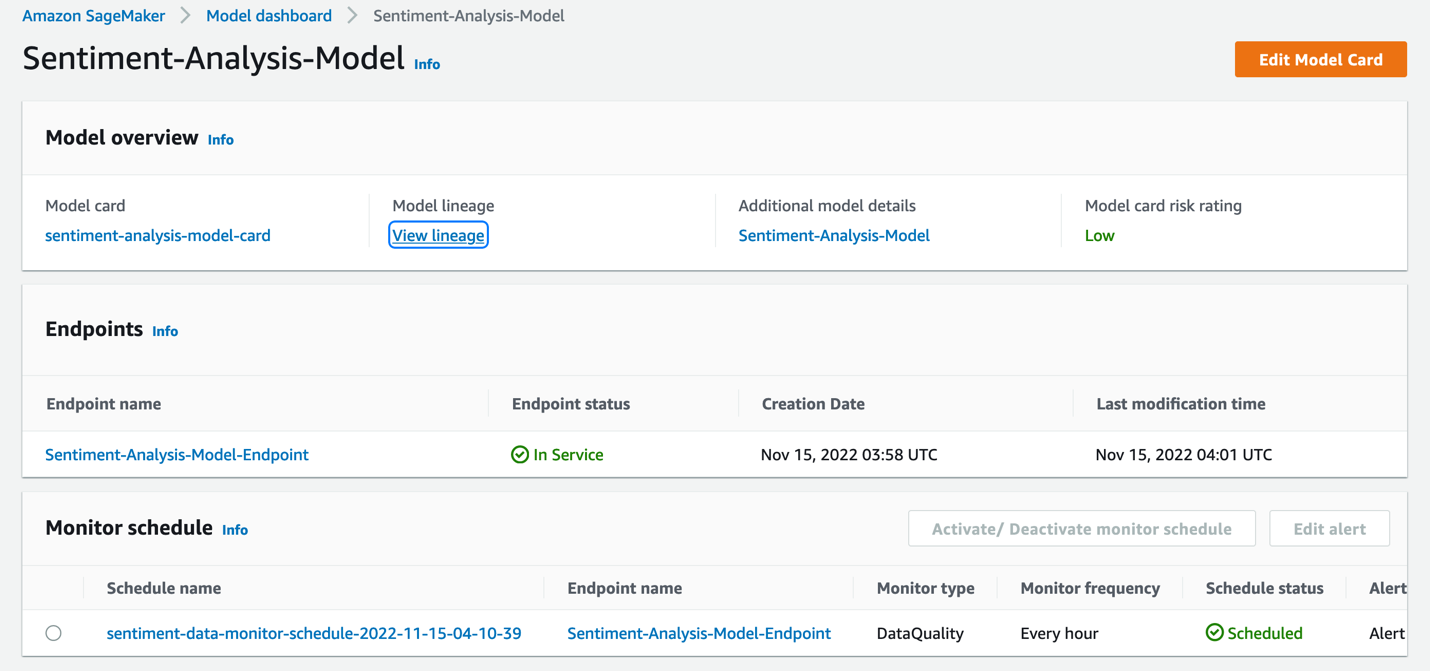
The following screenshot shows an example of the Model dashboard.
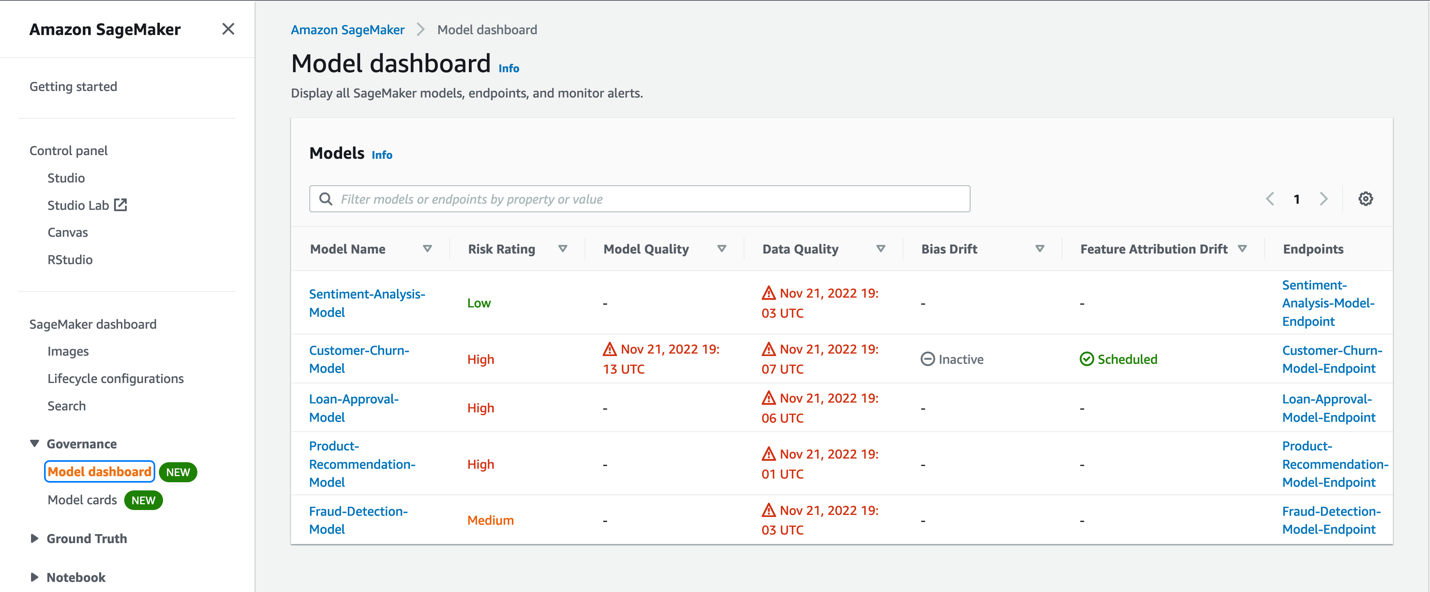
The Model dashboard provides an overview of all your models, what their risk rating is, and how those models are performing in production. It does this by pulling information from across SageMaker. The performance monitoring information is captured through Amazon SageMaker Model Monitor, and you can also see information on models invoked for batch predictions through SageMaker batch transform jobs. Lineage information such as how the model was trained, data used, and more is captured, and information from Model cards is pulled as well.
Model Monitor monitors the quality of SageMaker models used in production for batch inference or real-time endpoints. You can set up continuous monitoring or scheduled monitors via SageMaker APIs, and edit the alert settings through the Model dashboard. You can set alerts that notify you when there are deviations in the model quality. Early and proactive detection of these deviations enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. The Model dashboard gives you quick insight into which models are being monitored and how they are performing. For more information on Model Monitor, visit Monitor models for data and model quality, bias, and explainability.
When you choose a model in the Model dashboard, you can get deeper insights into the model, such as the Model card (if one exists), model lineage, details about the endpoint the model has been deployed to, and the monitoring schedule for the model.

This view allows you to create a Model card if needed. The monitoring schedule can be activated, deactivated, or edited as well through the Model dashboard.
For models that don’t have a monitoring schedule, you can set this up by enabling Model Monitor for the endpoint the model has been deployed to. Through the alert details and status, you will be notified of models that are showing data drift, model drift, bias drift, or feature drift, depending on which monitors you set up.
Let’s look at an example workflow of how to set up model monitoring. The key steps of this process are:
- Capture data sent to the endpoint (or batch transform job).
- Establish a baseline (for each of the monitoring types).
- Create a Model Monitor schedule to compare the live predictions against the baseline to report violations and trigger alerts.
Based on the alerts, you can take actions like rolling back the endpoint to a previous version or retraining the model with new data. While doing this, it may be necessary to trace how the model was trained, which can be done by visualizing the model’s lineage.
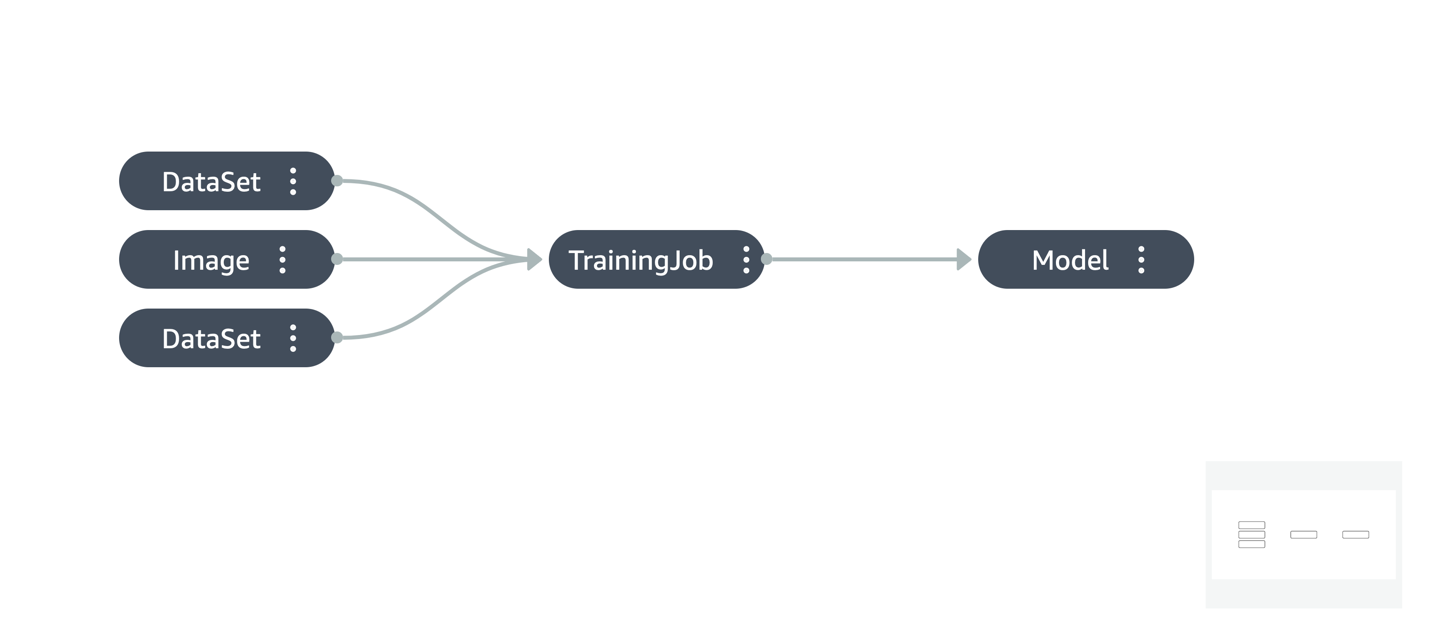
The Model dashboard offers a rich set of information regarding the overall model ecosystem in an account, in addition to the ability to drill into the specific details of a model. To learn more about the Model dashboard, refer to developer guide.
Conclusion
Model governance is complex and often involves lots of customized needs specific to an organization or an industry. This could be based on the regulatory requirements your organization needs to comply with, the types of personas present in the organization, and the types of models being used. There’s no one-size-fits-all approach to governance, and it’s important to have the right tools available so that a robust governance process can be put into place.
With the purpose-built ML governance tools in SageMaker, organizations can implement the right mechanisms to improve control and visibility over ML projects for their specific use cases. Give Model cards and the Model dashboard a try, and leave your comments with questions and feedback. To learn more about Model cards and the Model dashboard, refer to developer guide.
About the authors
 Kirit Thadaka is an ML Solutions Architect working in the SageMaker Service SA team. Prior to joining AWS, Kirit worked in early-stage AI startups followed by some time consulting in various roles in AI research, MLOps, and technical leadership.
Kirit Thadaka is an ML Solutions Architect working in the SageMaker Service SA team. Prior to joining AWS, Kirit worked in early-stage AI startups followed by some time consulting in various roles in AI research, MLOps, and technical leadership.
 Marc Karp is a ML Architect with the SageMaker Service team. He focuses on helping customers design, deploy and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is a ML Architect with the SageMaker Service team. He focuses on helping customers design, deploy and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Ram Vittal is an ML Specialist Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys tennis, photography, and action movies.
Ram Vittal is an ML Specialist Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys tennis, photography, and action movies.
 Sahil Saini is an ISV Solution Architect at Amazon Web Services . He works with AWS strategic customers product and engineering teams to help them with technology solutions using AWS services for AI/ML, Containers, HPC and IoT. He has helped set up AI/ML platforms for enterprise customers.
Sahil Saini is an ISV Solution Architect at Amazon Web Services . He works with AWS strategic customers product and engineering teams to help them with technology solutions using AWS services for AI/ML, Containers, HPC and IoT. He has helped set up AI/ML platforms for enterprise customers.