AWS Machine Learning Blog
Introduction to the Amazon SageMaker Neural Topic Model
Structured and unstructured data are being generated at an unprecedented rate, so you need the right tools to help organize, search, and understand this vast amount of information, it’s challenging to make the data useful. This is especially true for unstructured data, and it’s estimated that over 80% of the data in enterprises is unstructured. Text analytics is the process of converting unstructured text into meaningful data for analysis to support fact-based decision making. There are different techniques used for text analytics, such as topic modeling, entity and key phrases extraction, sentiment analysis, and coreference resolution.
What is topic modeling?
Topic Modeling is used to organize a corpus of documents into “topics” which is a grouping based on a statistical distribution of words within the documents themselves. Amazon Comprehend, our fully managed text analytics service, provides a pre-configured topic modeling API that is best suited for the most popular use cases like organizing customer feedback, support incidents or workgroup documents. Amazon Comprehend is the suggested topic modeling choice for customers as it removes a lot of the most routine steps associated with topic modeling like tokenization, training a model and adjusting parameters. Amazon SageMaker’s Neural Topic Model (NTM) caters to the use cases where a finer control of the training, optimization, and/or hosting of a topic model is required, such as training models on text corpus of particular writing style or domain, or hosting topic models as part of a web application. While Amazon SageMaker NTM provides a starting point of state-of-the-art topic modeling, customers have the flexibility to modify the network architecture as well as hyperparameters to accommodate the idiosyncrasies of their data sets as well as to tune the trade-off between a multitude of metrics such as document modeling accuracy, human interpretability and granularity of the learned topics, based on their applications. In addition, Amazon SageMaker NTM leverages the full power of the Amazon SageMaker platform: easily configurable training and hosting infrastructure, automatic hyperparameter optimization, and fully-managed hosting with auto-scaling.
The technical definition of topic modeling is that each topic is a distribution of words and each document is a mixture of topics across a set of documents (also referred to as a corpus). For example, a collection of documents that contains frequent occurrences of words such as “bike,” “car,” “mile,” or “brake” are likely to share a topic on “transportation.” If another collection of documents shares words such as “SCSI,” “port,” “floppy,” or “serial” it is likely that they are discussing a topic on “computers.” The process of topic modeling is to infer hidden variables such as word distribution for all topics and topic mixture distribution for each document by observing the entire collection of documents. The figure that follows shows the relationships among words, topics, and documents.
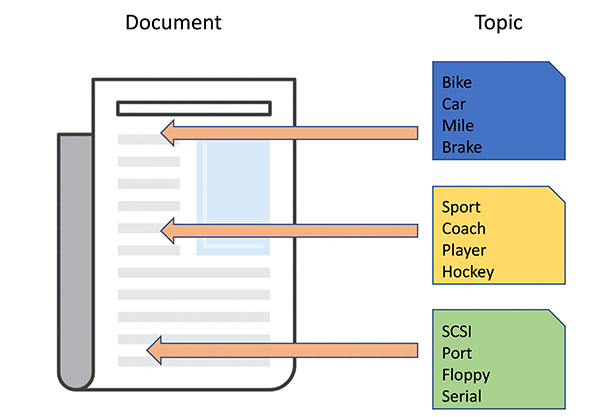
There are many practical use cases for topic modeling, such as document classification based on the topics detected, automatic content tagging using tags mapped to a set of topics, document summarization using the topics found in the document, information retrieval using topics, and content recommendation based on topic similarities. Topic modeling can also be used as a feature engineering step for downstream text-related machine learning tasks. It’s also worth mentioning that, topic modeling is a general algorithm that attempts to describe a set of observations with the underlying themes. Although we focus on text documents here, the observations can be applied other types of data. For example, topic models can also be used for modeling other discrete-data use cases such as discovering peer-to-peer applications on the network of an internet service provider or corporate network.
Amazon SageMaker Neural Topic Model (NTM)
Amazon SageMaker is an end-to-end machine learning platform that provides a Jupyter notebook hosting service, highly scalable machine learning training service, web-scale built-in algorithms, and model hosting service. Among the list of built-in (AKA first-party) algorithms are two topic modeling algorithms: Amazon SageMaker Neural Topic Model (NTM) and Amazon SageMaker Latent Dirichlet Allocation (LDA). In this blog post, we focus on NTM. Topic models are a classical example of probabilistic graphical models that involve challenging posterior inference problems. In SageMaker NTM, we implement topic modeling under a neural-network based variational inference framework [1]. The difficult inference problem is framed as an optimization problem solved by scalable methods such as stochastic gradient descent. Compared to conventional inference schemes, the neural-network implementation allows for scalable model training as well as low-latency inference. Furthermore, the flexibility of the neural inference framework allows us to more quickly add new functionalities and serve a wider range of customer use cases. A high-level architecture of the algorithm is shown in the following figure.

SageMaker NTM takes the high-dimensional word count vectors in documents as inputs, maps them into lower-dimensional hidden representations, and reconstructs the original input back from the hidden representations. The hidden representation learned by the model corresponds to the mixture weights of the topics associated with the document. The semantic meaning of the topics can be determined by the top-ranking words in each topic as learned by the reconstruction layer. The training objective of SageMaker NTM is to minimize the reconstruction error and Kullback–Leibler_divergence, the sum of which corresponds to an upper-bound on the negative log-likelihood of the data.
SageMaker NTM is trained in a highly distributed cluster environment for large scale model training. It supports three data channels for the training job, including the required train channel, and the optional validation and test channels. The validation channel is used to decide when to stop the training job. You have the option to replicate or shard the training and validation data to each of the training nodes or you can stream the data when the streaming feature is available. At inference time, SageMaker NTM takes data inputs in CSV or RecordIO-wrapped-Protobuf file formats.
SageMaker NTM supports a list of hyperparameters for fine tuning model performance. You can use these hyperparameters to configure knobs like the number of topics to extract, the number of epochs, and the learning rate to fine-tune the trade-off between accuracy and training time. We highlight a few hyperparameters in the list that follows. For information about the full list of available hyperparameters, refer to the topic NTM Hyperparameters.
- feature_dim – the feature dimension, it should be set to the vocabulary size
- num_topics – the number of topics to extract
- mini_batch_size – the batch size for each worker instance. Note that in multi-GPU instances, this number will be further divided by the number of GPUs. Therefore, for example, if we plan to train on an 8-GPU machine (such as ml.p2.8xlarge) and want each GPU to have 1024 training examples per batch, mini_batch_size should be set to 8196.
- epochs – the maximal number of epochs to train for, training may stop early
- num_patience_epochs and tolerance controls the early stopping behavior. Roughly speaking, the algorithm will stop training if within the last num_patience_epochs epochs there have not been improvements on validation loss. Improvements smaller than `tolerance` will be considered non-improvement.
- optimizer and learning_rate – by default we use the adadelta optimizer, and learning_rate does not need to be set. For other optimizers, the choice of an appropriate learning rate may require experimentation.
To use SageMaker NTM for model training, you create a training job and specify data channels, hyperparameters, compute resource type, and number. There are multiple ways to create a SageMaker NTM training job. You can use the Amazon SageMaker console to configure and start the training job, or you can use the SageMaker Python SDK in your Python script or Jupyter notebook to configure and start the training job. You can also integrate the NTM model training workflow directly inside a Spark pipeline using the SageMaker Spark SDK.
Amazon SageMaker NTM training works on CPUs but can also fully leverage the computational power of GPUs. For large data sets we recommend using GPU instances, such as P2 or P3 instances.
During training, Amazon SageMaker will output the training statistics to Amazon CloudWatch Logs and the Jupyter console, if the job is started in the Jupyter notebook environment. The training statistics include word distribution for each training step as well as statistics on total loss and KL divergence loss to help you make a decision on whether you want to use the model or not.
As an unsupervised generative model, we do not have an accuracy or error metric to compare model training progress to some established prior expectations. The main indicator of model training progress is the training loss, which corresponds to the negative log-likelihood of data as discussed above. To evaluate how well the trained model generalize to unseen data, we recommend that when you train the NTM that you always supply a validation data set so that the model training progress can be properly assessed and early stopping can be in effect to avoid overfitting.
In addition to training loss, which measures how well the model describes and reconstructs data, for topic modeling on text, the top-N words representing each topic should be semantically meaningful, and thus human-interpretable. However the interpretability is somewhat subjective to evaluate. The most widely accepted metric that can be calculated without human experts is topic coherence based on normalized point-wise mutual information (NPMI). Evaluating NPMI requires a large external reference corpus and intensive computation, and this metric is not currently available in NTM. For users interested in calculating NPMI offline based on the output from NTM, refer to [2].
After the model is trained, you have the option to host the model in Amazon SageMaker with a single API call. Amazon SageMaker provides RESTful API endpoints for the trained model in an auto-scaled cluster environment, and it provides a default inference function for hosting. There are several ways to invoke the hosted NTM SageMaker API endpoint including the AWS SDK, AWS CLI, or SageMaker Python SDK. For model hosting, starting with CPU instances for model serving is usually sufficient. GPU-based instances are also available for higher performance.
The output of the SageMaker NTM model inference looks like the following. (There is a separate prediction output line for each document in the input data. The decimal numbers represent the weights for each of the topics assigned to the document.)

The output format of inference: “topic_weights” is a list of non-negative numbers that represent the strength of topics in each document.
If you want to determine the semantic meaning of each topic, you can map the word distributions for a training job to the actual words. If you open up the CloudWatch Log for a training job, you can find the word distribution by looking for something similar to the following figure, at end of the log. In this figure, each row represents a topic, and the integers in a row represent the top words in the topic. You can then look up the actual words by mapping the integers to the original vocabulary.

Model training using the 20NewsGroup dataset
Let’s train a model using the 20NewsGroup dataset, which consists of 20,000 messages taken from 20 different newsgroups It has been widely used as a benchmark dataset for topic modeling. In this exercise, you will walk through the steps of launching a SageMaker Jupyter instance, training a topic model using the SageMaker training service with the SageMaker NTM algorithm, and then hosting the model using the SageMaker hosting service.
If you don’t already have a SageMaker notebook instance running, follow these instructions to launch a notebook instance and start the Jupyter dashboard.
We will also need an Amazon S3 bucket to store the dataset and model artifact, so let’s get that created as well. Create an S3 bucket called “sagemaker-xx“, where “xx” could be your initials to make the bucket distinct. You will need this bucket when building the notebook later. If you are not familiar with how to create a S3 bucket. Follow the instructions here.
Now we are ready to create a new Jupyter notebook for the exercise. To start, you choose the new drop-down menu and then select the “conda_mxnet_p36” menu item to create an empty notebook. Change the name of notebook so it is easier to identify. In addition, the following cells are available in a Jupyter notebook you can find here, you can also follow along with the prepared notebook rather than starting from scratch.
Data preparation
Fetching the data set
In this section, we first download and unpack the data set. Then, we extract the text content from each of the documents.
The 20NewsGroup data set is available at the UCI Machine Learning Repository at this location. Please be aware of the following requirements about acknowledgements, copyright, and availability, cited from the data set description page, before proceeding to download the data set.
Now we can unpack the package and see 20 folders of documents.
Next we read in all the documents and extract the message body as a list of strings.
Let’s take a quick look at what is in the training dataset by running the following code in a new cell.
As we can see, the entries in the data set are just plain text paragraphs. We will need to process them into a suitable data format.
From plain text to bag-of-words (BOW)
The input documents to the algorithm, both in training and inference, need to be vectors of integers representing word counts. This is so-called bag-of-words (BOW) representation. To convert plain text to BOW, we need to first “tokenize” our documents, that is, identify words and assign an integer ID to each of them. Then, we count the occurrence of each of the tokens in each document and form BOW vectors. We will only keep the most frequent 2,000 tokens (words) because rarely used words have a much smaller impact on the model and thus can be ignored.
In this example, we will use a simple lemmatizer from the nltk package and use CountVectorizer in scikit-learn to perform the token counting. For more details refer to their documentation. Alternatively, spaCy also offers easy-to-use tokenization and lemmatization functions.
In the following cell, we use a tokenizer and a lemmatizer from nltk. In the list comprehension, we implement a simple rule: only consider words that are longer than 2 characters, start with a letter and match the token_pattern.
With the tokenizer defined we perform token counting next while limiting the vocabulary size to vocab_size:
Optionally, we might consider removing very short documents. The following cell removes documents shorter than 25 words. This certainly depends on the application, but there are also some general justifications. It’s hard to imagine very short documents that express more than one topic. Topic modeling tries to model each document as a mixture of multiple topics, thus it may not be the best choice for modeling short documents.
Because all the parameters (weights and biases) in the NTM model are np.float32 type we’d need the input data to also be in np.float32. It is better to do this type-casting upfront rather than repeatedly casting during mini-batch training.
As a common practice in modeling training, we should have a training set, a validation set, and a test set. The training set is the set of data the model is actually being trained on. But what we really care about is not the model’s performance on training set but its performance on future, unseen data. Therefore, during training, we periodically calculate scores (or losses) on the validation set to validate the performance of the model on unseen data. By assessing the model’s ability to generalize we can stop the training at the optimal point via early stopping to avoid over-training.
Note that when we only have a training set and no validation set, the NTM model will rely on scores on the training set to perform early stopping, which could result in over-training. Therefore, we recommend always supply a validation set to the model.
Here we use 80% of the data set as the training set and the rest for validation set and test set. We will use the validation set in training and use the test set for demonstrating model inference.
Store data on Amazon S3
We first need to specify data locations and access roles. This is the only cell of this notebook that you will need to edit. In particular, we need the following data:
- The S3 bucket and prefix that you want to use for training and model data. This should be within the same region as the Notebook Instance, training, and hosting.
- The IAM role is used to give training and hosting access to your data. See the documentation for how to create these.
The NTM algorithm, as well as other first-party SageMaker algorithms, accepts data in RecordIO Protobuf format. The SageMaker Python API provides helper functions for easily converting your data into this format. Here we define a helper function to convert the data to RecordIO Protobuf format and upload it to Amazon S3. In addition, we will have the option to split the data into several parts specified by n_parts.
The algorithm inherently supports multiple files in the training folder (“channel”), which could be very helpful for large data set. In addition, when we use distributed training with multiple workers (compute instances), having multiple files allows us to distribute different portions of the training data to different workers conveniently.
Inside this helper function we use the write_spmatrix_to_sparse_tensor function provided by the SageMaker Python SDK to convert scipy sparse matrix into RecordIO Protobuf format.
Model training
We have created the training and validation data sets and uploaded them to Amazon S3. Next, we configure an Amazon SageMaker training job to use the NTM algorithm on the data we prepared
Amazon SageMaker uses an Amazon Elastic Container Registry (ECR) Docker container to host the NTM training image. The following Amazon ECR containers are currently available for SageMaker NTM training in different Regions. For the latest Docker container registry please refer to Amazon SageMaker: Common Parameters.
The code in the cell below automatically chooses an algorithm container based on the current Region. In the API call to sagemaker.estimator.Estimator we also specify the type and count of instances for the training job. Because the 20NewsGroups data set is relatively small, we have chosen a CPU only instance (ml.c4.xlarge), but feel free to change to other instance types: https://aws.amazon.com/sagemaker/pricing/instance-types/. NTM fully takes advantage of GPU hardware and in general trains roughly an order of magnitude faster on a GPU than on a CPU. Multi-GPU or multi-instance training further improves training speed roughly linearly if communication overhead is low compared to compute time.
Next, we specify hyperparameters specific to NTM. Refer to the discussion in earlier sections about the meaning of these hyperparameters.
Next, we need to specify how the training data and validation data will be distributed to the workers during training. There are two modes for data channels:
FullyReplicated: all data files will be copied to all workers.ShardedByS3Key: data files will be sharded to different workers, that is, each worker will receive a different portion of the full data set.
At the time of writing, by default, the Python SDK will use FullyReplicated mode for all data channels. This is desirable for validation (test) channel but not as efficient for the training channel, when we use multiple workers. We want to have each worker go through a different portion of the full data set to provide different gradients within epochs. We specify distribution to be ShardedByS3Key for the training data channel as follows.
Now we are ready to train. The following cell takes a few minutes to run. The following command will first provision the required hardware. You will see a series of dots indicating the progress of the hardware provisioning process. After the resources are allocated, training logs will be displayed. With multiple workers, the log color and the ID following `INFO` identifies logs emitted by different workers.
If you see the message
at the bottom of the output logs then that means training was successfully completed and the output NTM model was stored in the specified output path. You can also view information about the status of a training job using the Amazon SageMaker console.
Model hosting and inference
A trained NTM model does nothing on its own. We now want to use the model we computed to perform inference on data. For this example, that means predicting the topic mixture representing a given document. We create an inference endpoint using the SageMaker Python SDK deploy() function from the job we defined above. We specify the instance type where inference is computed as well as an initial number of instances to spin up.
After the deployment is completed, run the following code to prepare the test data and invoke the endpoint for inference. We can pass data in a variety of formats to our inference endpoint. Here, we will demonstrate passing CSV-formatted data. We make use of the SageMaker Python SDK utilities csv_serialize and json_deserializer when configuring the inference endpoint and pass 5 documents from the test dataset for inference.
Visualizing predictions
A more intuitive way to see the prediction results is to visualize topic assignments for the 5 sample testing data. Run the following code in a new cell to plot a bar chart for the topic assignment for the 20 topics.
An example output looks as follows:

Delete the endpoint
If you do not want to keep the endpoint around to avoid additional hosting cost, you can run the following code to delete the endpoint and terminate the EC2 instance backing the endpoint.
Conclusion
Congratulations! You have successfully trained a topic model using the SageMaker NTM algorithm. In this exercise you have learned to prepare a 20NewsGroup dataset for the SageMaker NTM algorithm, and you trained a model using the Amazon SageMaker training service. You have also learned to deploy the model using the Amazon SageMaker hosting service and made real-time inference against the endpoint.
You can download the complete notebook, which contains additional instructions and sample code for you to explore the trained model. It also has code for you to visualize a few sample topics as word clouds (see the following screenshot) with word sizes proportional to probability of the words appearing under each topic.

If you want to see how the Amazon SageMaker and Neural Topic Model can be used for a much larger dataset, check out this webinar. It shows you how Amazon EMR can be integrated with Amazon SageMaker to pre-process the entire English Wikipedia, which has over 5.5 million articles, and to learn how models are trained at scale on 16 ml.p3.8xlarge instances each equipped with 4 NVIDIA Tesla V100 GPUs.
References
[1] Yishu Miao, Edward Grefenstette, and Phil Blunsom. Discovering discrete latent topics with neural variational inference. In International Conference on Machine Learning, pages 2410
[2] Jey Han Lau, D avid Newman, and Timothy Baldwin. Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, pages 530
About the Authors
 David Ping is a Principal Solutions Architect with the AWS Solutions Architecture organization. He works with our customers to build cloud and machine learning solutions using AWS. He lives in the NY metro area and enjoys learning the latest machine learning technologies.
David Ping is a Principal Solutions Architect with the AWS Solutions Architecture organization. He works with our customers to build cloud and machine learning solutions using AWS. He lives in the NY metro area and enjoys learning the latest machine learning technologies.
 Ran Ding is an Applied Scientist on the AWS AI Algorithms team, researching and developing machine learning algorithms in Amazon SageMaker. Before Amazon, Ran obtained his PhD in Electrical Engineering from the University of Washington and worked at a startup company making optical processors.
Ran Ding is an Applied Scientist on the AWS AI Algorithms team, researching and developing machine learning algorithms in Amazon SageMaker. Before Amazon, Ran obtained his PhD in Electrical Engineering from the University of Washington and worked at a startup company making optical processors.
 Ramesh Nallapati is a Senior Applied Scientist in the AWS AI SageMaker team. He works on building novel deep neural networks at scale primarily in the natural language processing domain. He is very passionate about deep learning, and enjoys learning about latest developments in AI and is excited about contributing to this field to the best of his abilities.
Ramesh Nallapati is a Senior Applied Scientist in the AWS AI SageMaker team. He works on building novel deep neural networks at scale primarily in the natural language processing domain. He is very passionate about deep learning, and enjoys learning about latest developments in AI and is excited about contributing to this field to the best of his abilities.
 Julio Delgado Mangas is a Software Development Engineer on the AWS AI Algorithms team. He has contributed to AWS services like Amazon CloudWatch and the Amazon QuickSight SPICE engine. Before joining Amazon he was a research engineer on the Human Brain Project.
Julio Delgado Mangas is a Software Development Engineer on the AWS AI Algorithms team. He has contributed to AWS services like Amazon CloudWatch and the Amazon QuickSight SPICE engine. Before joining Amazon he was a research engineer on the Human Brain Project.
 Bing Xiang is a Principal Scientist and Manager at AWS AI. He leads a team of scientists and engineers working on deep learning, machine learning, and natural language processing for several AWS services. Before joining Amazon he was a Principal Research Staff Member and Manager at IBM Watson.
Bing Xiang is a Principal Scientist and Manager at AWS AI. He leads a team of scientists and engineers working on deep learning, machine learning, and natural language processing for several AWS services. Before joining Amazon he was a Principal Research Staff Member and Manager at IBM Watson.