Artificial Intelligence
Use pre-trained financial language models for transfer learning in Amazon SageMaker JumpStart
Starting today, we’re releasing new tools for multimodal financial analysis within Amazon SageMaker JumpStart. SageMaker JumpStart helps you quickly and easily get started with machine learning (ML). It provides a set of solutions for the most common use cases that can be trained and deployed readily with just a few clicks. You can now access a collection of multimodal financial text analysis tools, including example notebooks, text models, and solutions.
With these new tools, you can enhance your tabular ML workflows with new insights from financial text documents and potentially help save up to weeks of development time. With the new SageMaker JumpStart Industry SDK, you can easily retrieve common public financial documents, including SEC filings, and further process financial text documents with features such as summarization and scoring of the text for various attributes such as sentiment, risk, and readability. In addition, you can access pre-trained language models trained on financial text for transfer learning, and use example notebooks for data retrieval, text feature engineering, multimodal classification and regression models.
In this post, we show how you can deploy a language model pre-trained on SEC filings text to build financial classification models with transfer learning.
The new financial analysis features include an example notebook that demonstrates APIs to retrieve parsed SEC filings, APIs for summarizers, and APIs to score text for various attributes (see SageMaker JumpStart SEC Filings Retrieval w/Summarizer and Scoring). A second notebook (Multi-category ML on SEC Filings Data) demonstrates multicategory classification on SEC filings. A third notebook (ML on a TabText (Multimodal) Dataset) shows how to undertake ML on multimodal financial data using the Paycheck Protection Program (PPP) as an example. We’re also releasing a SageMaker JumpStart solution (Corporate Credit Rating Prediction) to build a corporate credit scoring model using multimodal ML. For more information, see Use SEC text for ratings classification using multimodal ML in Amazon SageMaker JumpStart.
Four additional text models (RoBERTa-SEC-Base, RoBERTa-SEC-WIKI-Base, RoBERTa-SEC-Large, RoBERTa-SEC-WIKI-Large) are provided to generate embeddings for transfer learning using pre-trained financial models that have been trained on Wiki text and 10 years of SEC filings. This post shows you how to use the new text models.
Language modeling
Machine learning on text begins with representing the text in a document in fixed-length numerical vectors in a high-dimension space. Each word or subword in a document is assigned a vector representation, also known as an embedding. Vector representations of words are generated in many different ways, ranging from context-free to context-rich. Representation learning (Bengio et al. 2012) using transformers (Vaswani et al. 2017) is a novel approach that has proven extremely effective for short text. The transformer in natural language processing (NLP) is a seminal approach for sequence-to-sequence tasks that handles wider context than was possible with traditional word embeddings using attention mechanisms and doesn’t require sequence-aligned RNNs or convolution. The popular BERT (Bidirectional Encoder Representations from Transformers, Devlin et al. 2018) approach has been especially effective in generating context-rich text representations, which are then fed into neural layers for training deep learning classifiers, an approach known as transfer learning (see a survey by Zhang et al.).
Transfer learning is analogous to taking a college-trained student and providing them on-the-job training to utilize the knowledge gained in college to be specialized to a specific task. For example, students who graduate with an undergraduate degree in finance are further trained to become lending officers, thereby transferring (and building upon) their broad knowledge of finance to the sub-field of lending. This is known as fine-tuning in ML parlance.
Likewise, a high-school student studies many general subjects in preparation for college. When they arrive at college, they eventually choose a major (such as finance) and take more courses in a given field. This prepares them for further learning on the job. We can think of a college undergrad as pre-trained in a given field, ready to be fine-tuned further on the job.
Overview
In this post, we present how language models that are pre-trained on common text (such as Wikipedia) and further pre-trained on financial text (SEC filings) can be fine-tuned for specific classification tasks. Some examples of such tasks are rating the credit quality of companies, predicting up or down moves in stock prices, sentiment classification of financial news, or clustering of firms into industry types. Specifically in this post, we examine classification of tweets and sentences from news about cryptocurrencies.
These pre-trained models are known as RoBERTa-SEC models, pre-trained on Wiki text and SEC text. These models emit embeddings (numerical vector representations of text) that may then be used for fine-tuning. The steps are as follows:
- Deploy the embedding model to an Amazon SageMaker endpoint with a single click.
- Call the endpoint to return an embedding representation for each document in a collection of documents in a single function call.
- Use the embeddings to train (fine-tune) a classifier on your own dataset of features and labels.
That’s it!
For financial NLP, using the pre-trained RoBERTa-SEC language models described here may offer good classification performance on financial text.
These text models are now available through SageMaker JumpStart. To get started, you can access SageMaker JumpStart in SageMaker Studio and search for the following four model cards: RoBERTa-SEC-Base, RoBERTa-SEC-WIKI-Base, RoBERTa-SEC-Large, or RoBERTa-SEC-WIKI-Large.
In the following sections, we describe this process and also provide further background on transformer models. The code for this post is available from the text model card we describe, which comes with the notebook for implementation.
Embeddings from transformer models
Transformer models provide embeddings for each token (namely, a word or subword). You can pool these embeddings to generate a single embedding vector for an entire document, thereby representing a document as a single vector of fixed size, so that all documents are represented as vectors of the same size. You can then stack these up in a matrix, which you can use to fit a neural network to training labels.
Transformer models are pre-trained. In other words, they have been trained on a vast corpora of text such as Wikipedia, Book Corpus, and more. The tasks used for pre-training are such that labels are endogenous to the text corpus. Common tasks are predicting missing words in a sentence (known as masked language modeling, MLM) or next sentence prediction (NSP). An encoder-decoder architecture with attention and self-attention is used to train on these tasks. The output of the encoder stack forms the embedding that is emitted from the pre-trained language model.
SageMaker JumpStart supports several text embedding model cards to deploy endpoints for models such as BERT, RoBERTa, and other models, which are pre-trained on general language, or you can use the financial language models we provide, denoted as the four RoBERTa-SEC models we mentioned. We offer four models in this group, of two embedding vector sizes (small and large), all pre-trained on SEC text with or without Wiki text. Each of these four models comes with a single-click deploy card in SageMaker JumpStart.
The pre-trained RoBERTa-SEC language model family
This is a class of financial language models that are pre-trained with a runtime of a few days. It’s called RoBERTa-SEC because it is a RoBERTa model that is trained on Wiki text and SEC filings, so contains the context of SEC filings.
We use the 10K/Q filings data for 10 years (2010–2019) of S&P 500 tickers to pre-train a RoBERTa class model (Liu, et al. 2019). For pre-training, the entire text of the 10K/Q filing was used, not just the MD&A (Management Discussion and Analysis) section, so as to ensure that a broader context of financial language is captured. In particular, we use dynamic masking and remove NSP (next sentence prediction) loss in the pre-training scheme of RoBERTa. Embeddings from the pre-trained model are then used for fine-tuning specific classifiers, namely transfer learning.
Pre-trained BERT (Devlin et al. 2018) models and its variants such as RoBERTa have achieved state-of-the-art results on a wide variety of NLP tasks, including question answering (SQuAD v1.1) and natural language inference (MNLI). The pre-trained BERT models generate bi-directional representations for text, which you can use as additional features or fine-tune in downstream NLP tasks.
To train the model with more than 100 million parameters, we used eight Amazon Elastic Compute Cloud (Amazon EC2) p3dn.24xlarge instances. Each instance has 92 vCPUs and 8 Nvidia V100 Tensor Core GPUs. It needed a distributed deep learning training framework to run the pre-training job using all GPUs on the eight instances. Pre-training data is distributed into 256 size shards (SEC filings are large and sometimes contain more than 100,000 tokens). With dynamic masking, the training instances with random masked tokens are generated on the fly during pre-training. The total number of training iterations is 250,000, with a minibatch size of 2,048 and sequence length 512.
Deploy the embedding endpoint
SageMaker JumpStart enables activating an endpoint that returns embeddings when text is passed to it. To see the different language models available for generating embeddings, see the Text models carousel in JumpStart in SageMaker Studio, as shown in the following screenshot.

Not all the text model cards are only for generating embeddings. Some of the cards provide much greater functionality. For this post, we focus on just the embeddings cards (the second and third ones in the preceding screenshot, which show Task: Text Embedding).
The Text models carousel contains several other text embedding cards, including the RoBERTa_SEC cards for the pre-trained financial language models.

Let’s use the RoBERTa-SEC-Base model with the text embedding task. To deploy the model, choose Deploy.

This generates an endpoint that you can call to get back text embeddings.
In the left panel, you can see the endpoint being created titled jumpstart-dft-mx-tcembedding-roberta-sec-base. This is the auto-generated name of the endpoint. The endpoint generation takes a few minutes to activate and is then ready for use.
After the endpoint has been instantiated, you see the prompt to open the notebook that contains example code demonstrating its use. Choose Open Notebook to access the demo notebook.

The endpoint name is already embedded into the notebook code. This pre-trained model is to be used to create embeddings for a text classification task. You can see the endpoint appear in the left panel.
You have completed Step 1. Now, let’s move on to Step 2, which is getting embeddings from the endpoint. The code for this is in the notebook you opened earlier.
Use the embedding endpoint
Install additional packages in case they’re not already present in the Studio instance. Also invoke the necessary standard packages. This code is provided in the notebook.
The notebook contains the following four functions, for which we only show the stubs here, and we call them to generate embeddings from the endpoint:
Purely for illustrative purposes, you can download a dataset and train a classifier. We provide a link to an open dataset of tweets, labeled with 1 (a disaster-related tweet), or 0 (not a disaster tweet). A financial analyst may find it useful to be notified of tweets that suggest a disaster is being tweeted about, as an early warning system, so that a trading action can be initiated.
Reference: https://github.com/erYash15/Real-or-Not-NLP-with-Disaster-Tweets
See the following code:
The following screenshot shows the top of the dataframe.

We have a dataset of over 11,000 tweets, of which we only use a subset of 5,000 tweets for illustration. We get embeddings for these tweets and then train a classifier (on 4,000 tweets) and test it (on 1,000 tweets):
We now get the embedding vector for each document using the doc2pooled_embedding function:

Now that we have embeddings for all the training and test data, we move on to Step 3, which fine-tunes a classification model using Keras/Tensorflow. The following deep neural net has two hidden layers of 64 neurons each and an output layer of two neurons:
We get the following summary of the neural network that we will train.
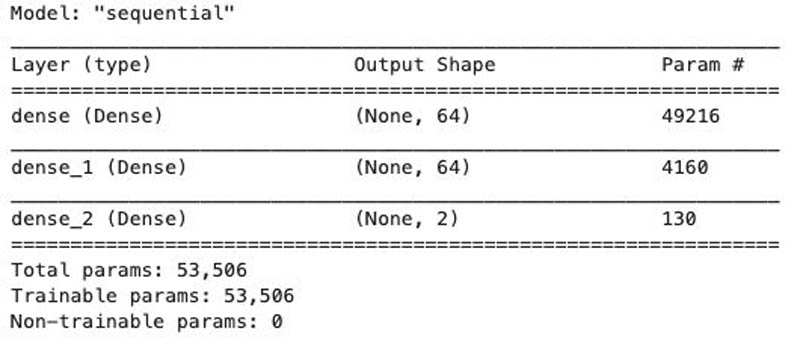
This is the summary of the model, showing over 50,000 trainable model parameters for fine-tuning.
No re-training of the embedding layers is undertaken.
We run only 10 epochs of training as an example. The output of the epochs from Keras is shown in the following screenshot.

You can then use the trained model for inference.
Summary
We have seen how easy it is to use SageMaker JumpStart’s text model cards for embeddings to deploy an embedding endpoint, generate embeddings on any short text of your choosing, and build (fine-tune) a classification model using these embeddings with your own labels.
In particular, for financial NLP, using the pre-trained RoBERTa-SEC language models as we described may offer good classification performance on financial text.
To use these text models, proceed to SageMaker JumpStart in SageMaker Studio (see SageMaker JumpStart), search for RoBERTa-SEC, and choose any of the four model cards, then deploy the model to an endpoint. After that, you can use the notebook that becomes available for modification and further use.
You can open the notebook and try it first, then modify it as needed. When you’re done, you can delete the endpoint to clean up and save resources. Then close and shut down the notebook.
Important: This post is for demonstrative purposes only. It is not financial advice and should not be relied on as financial or investment advice. The post used models pre-trained on data obtained from the SEC EDGAR database. You are responsible for complying with EDGAR’s access terms and conditions if you use SEC data.
Thanks to several team members for support with this work: Miyoung Choi, John He, Sophie Yue, Derrick Zhang, Yue Zhao.
About the Authors
 Dr. Sanjiv Das is an Amazon Scholar and the Terry Professor of Finance and Data Science at Santa Clara University. He holds post-graduate degrees in Finance (M.Phil and Ph.D. from New York University), Computer Science (M.S. from UC Berkeley), an MBA from the Indian Institute of Management, Ahmedabad. Prior to being an academic, he worked in the derivatives business in the Asia-Pacific region as a Vice-President at Citibank. He works on multimodal machine learning in the area of financial applications.
Dr. Sanjiv Das is an Amazon Scholar and the Terry Professor of Finance and Data Science at Santa Clara University. He holds post-graduate degrees in Finance (M.Phil and Ph.D. from New York University), Computer Science (M.S. from UC Berkeley), an MBA from the Indian Institute of Management, Ahmedabad. Prior to being an academic, he worked in the derivatives business in the Asia-Pacific region as a Vice-President at Citibank. He works on multimodal machine learning in the area of financial applications.
 Dr. Xin Huang is an applied scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of robust analysis of non-parametric space-time clustering, explainable deep learning on tabular data, and natural language processing.
Dr. Xin Huang is an applied scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of robust analysis of non-parametric space-time clustering, explainable deep learning on tabular data, and natural language processing.
 Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
Dr. Li Zhang is a Principal Product Manager-Technical for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms, a service that helps data scientists and machine learning practitioners get started with training and deploying their models, and uses reinforcement learning with Amazon SageMaker. His past work as a principal research staff member and master inventor at IBM Research has won the test of time paper award at IEEE INFOCOM.
 Daniel Zhu is a Software Development Engineer Intern at Amazon SageMaker. He is currently a third year Computer Science major at UC Berkeley, with a focus on machine learning.
Daniel Zhu is a Software Development Engineer Intern at Amazon SageMaker. He is currently a third year Computer Science major at UC Berkeley, with a focus on machine learning.