Artificial Intelligence
Using a test framework to design better experiences with Amazon Lex
November 2022: This post was updated to work for Amazon Lex V2.
Chatbots have become an increasingly important channel for businesses to service their customers. Chatbots provide 24/7 availability and can help customers interact with brands anywhere, anytime and on any device. To effectively utilize chatbots, they must be built with good design, development, test, and deployment practices. This post provides you with a framework that helps you automate the testing processes and reduce the overall bot development cycle for Amazon Lex bots.
Amazon Lex is a service for building conversational interfaces into any application using voice and text. Conversations with Amazon Lex bots can vary from simple, single-turn Q&A to a complex, multi-turn dialog. During the design phase, the conversation designer creates scripts and conversation flow diagrams that encapsulate the different ways a conversation can flow for a particular use case. Establishing an easy-to-use testing interface allows bot designers to iterate and validate their ideas quickly without depending on engineers. During the development and testing phase, an automated test framework helps engineers avoid manual testing and be more productive.
The test framework described in this post empowers designers and engineers to test many conversations in a few minutes, identify where the predicted intents are incorrect, and implement improvements. The insights provided by this process allow designers to quickly review intents that may be performing poorly, prioritize intents by importance, and modify the bot design to ensure minimal overlap between intents.
Solution architecture
The following diagram illustrates the architecture of our solution.

A test framework for chatbots can empower builders with the ability to upload test suites, run tests, and get test results comprised of accuracy information and test case level outcomes. The solution architecture provides you with the following capabilities:
- Test suites comprised of CSV files are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. These test suites adhere to a predefined format described later in this post.
- Tests are triggered using an Amazon API Gateway endpoint path
/test/run, which runs the test cases against Amazon Lex and returns a test ID, confusion matrix, and summary metrics. The results are also stored in an Amazon DynamoDB - Test details are retrieved from the DynamoDB table using another API path
/test/details/{id}, which returns test case outcomes for the specified test ID.
Deploying the AWS CloudFormation template
You can deploy this architecture using the provided AWS CloudFormation template in us-east-1.
- Choose Launch Stack.
![]()
- Choose Next.

- For Name, enter a stack name.
- Choose Next.
- In the Capabilities and transforms section, select all three check boxes to provide acknowledgment to AWS CloudFormation to create AWS Identity and Access Management (IAM) resources and expand the template.

- Choose Create stack.
This process might take 5 minutes or more to complete. The stack creates the following resources:
- Two DynamoDB tables to store the testing results
- Four AWS Lambda functions
- An API Gateway endpoint that is called by the client application
API key and usage plan
After the CloudFormation template finishes deploying the infrastructure, you see the following values on the Outputs tab: ApiGWKey and LexTestResultAPI.

The LexTestResultAPI requires an API key. The AWS CloudFormation output ApiGWKey refers to the name of the API key. As of this writing, this API key is associated with a usage plan that allows 2,000 requests per month.
- On the stack Outputs tab, choose the link for
ApiGWKey.
The API keys section of the API Gateway console opens.
- Choose Show next to the API key.
- Copy the API key to use when testing the API.
- You can manage the usage plan by following the instructions on Create, configure, and test usage plans with the API Gateway console.
- You can also add fine-grained authentication and authorization to your APIs. For more information about securing your APIs, see Controlling and managing access to a REST API in API Gateway.
Setting up your sample UI
You can build a user interface (UI) using your preferred technology stack to trigger the tests and view the results. This UI needs to be configured with the APIs created as part of running the CloudFormation template. You can also use the provided simple HTML file to follow along with this post, but we recommend building your own user interface for enterprise use.
- Download the sample UI project.
- In the index.html file, update the
APIKeyandAPIUrlwith the value created by the CloudFormation template:
var APIKey = “<API Key>”
var APIUrl = “<API URL, eg: https://xxxxxx.execute-api.us-east-1.amazonaws.com/prod/>”
Testing the solution
To demonstrate the test framework, we’ve created a simple banking bot that includes several intents, such as:
BusinessHoursCancelOrderCancelTransferCheck balanceMyFallbackIntentOrderChecksTransferFunds
This application has purposefully been designed to have failures, either from overlapping intents or missing utterances. This illustrates how the test framework surfaces issues to fix.
Creating your test set
Create a set of test data in a CSV file (or you can follow along using the sample test file). To achieve the best results, your test set of utterances should be different than your training set in order to test the quality of your Lex model. The goal is to have your model generalize on the intents you have created, so that your bot classifies intents correctly even when the utterance provided by a user is different from the utterances in Lex. By using different utterances in your testing set than in your Lex training set, you simulate this behavior before releasing your bot into production.
While labeling or generating your utterances for each intent, be cognizant that you will need both labeled training and testing data for each intent. For example, imagine you’ve labeled 30 utterances for each intent. During this process, the labeled data has broad coverage over the possible ways a user might describe your intent. These utterances should have noun and verb variation, vary in length (using short and long phrases), use slots where appropriate, and be both formal and informal. Next, randomize the utterance set and split it into a training and a testing set (ex: 70/30 split between train and test data). The training utterances go into Lex to create the chatbot, and the testing utterances can be added to your testing .CSV test file to use with this testing framework.
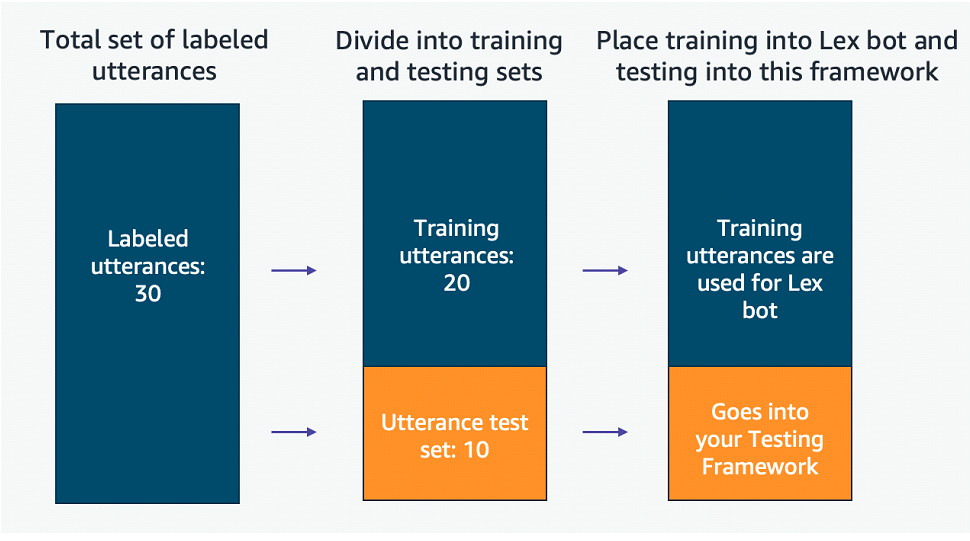
(Example scenario of labeled data single intent for illustrative purposes)
Setting up your test
To set up your test, complete the following steps:
- Download the sample bot with conflicting intents and import it on the console.
- Build the bot and create an alias.
- Create a set of test data in a CSV file (you can use the sample test file to follow along in this post).
- Upload the file to a S3 bucket in your account.
Format of the test file
The test data CSV file consists of six columns.

ConversationID: A unique identifier for the conversation. A conversation can be a single turn or multi-turn. All utterances within a multi-turn conversation will share the same ConversationID.
Utterance: The user text.
Intent: The expected intent from Amazon Lex.
Slots: The expected list of slots and their values from Amazon Lex. Slots are separated using “|” symbol.
Ex: AccountType=Savings|DollarAmount=100
Response: The expected response message from Amazon Lex. This is optional field for the test framework, but helps with the readability of the results.
SessionAttributes: For the given utterance, a list of session attributes which are expected from Amazon Lex. Session attributes are separated using “|” symbol.
Ex: intentName=OrderChecks|NumOfCheckBooks=2
Running a test
To run your test, complete the following steps:
- Open the index.html from the sample UI code in a web browser.
- Choose the sample bot you created.
- Choose the alias you created.
- Enter the Amazon S3 URL for the sample test file.
- Choose Run.

Examining your results
In a few moments, you see a response that has a confusion matrix and test results. The intents that Amazon Lex predicted for each utterance are across the horizontal axis. The vertical axis contains the intents from the ground truth data specified in our test file. The center diagonal from the top left cell to the bottom right cell indicates where intents in the ground truth dataset match the predicted intents.
Any values that fall outside of that center diagonal indicate areas of improvement in the bot design.

In this post, we discuss a few examples from the sample banking bot, which was purposefully designed to have issues.
In the test data CSV file, the first column has a ConversationID label. Each set of utterances making up a conversation is grouped by ID number. Some conversations are a single turn, meaning the request can be satisfied by the bot without the bot asking the user for additional or clarifying slot information. For example, in our simple banking app, the user can ask about the hours of operation and receive an answer in a single turn. In our test data, we’ve included several utterances expected to trigger the BusinessHours intent.
The confusion matrix shows that all utterances that should trigger the BusinessHours intent did so. There are no additional values on the predicted axis aside from the BusinessHours intent, which means this intent is working well. Under the confusion matrix, a more detailed view shows which utterances succeeded and which failed from the test conversations. Again, each of our single-turn conversations 1, 2, and 3 are shown to have succeeded in the Result column.

A quick scan of the other intents indicates that not all were so successful. Let’s take a look at a multi-turn conversation that didn’t perform as well. In the confusion matrix, the TransferFunds row shows that none of our actual utterances were predicted to trigger the TransferFunds intent. That is a problem.
Conversation 15 is a multi-turn conversation intended to trigger the TransferFunds intent. However, it’s shown to have failed. The utterance tested is “Move cash to another account.” That seems like a reasonable thing for someone to say if they’d like to transfer money, but our model is mapping it to one of our other intents.
To fix the problem, return to the Amazon Lex console and open the TransferFunds intent. There are only a few sample utterances and none of the utterances include the words “move” or “money.”

It’s no wonder that the bot didn’t know to map an utterance like “Move cash to another account” to this intent. The best way to fix this is to include additional sample utterances to cover the various ways people may communicate that they want to transfer funds. The other area to look at is those intents that were mis-predicted as being appropriate. Make sure that the sample utterances used for those intents don’t conflict or overlap with utterances that should be directed to TransferFunds.
In the following examples, the bot may be having trouble as indicated in our test output. Slot values are important pieces of information that help the bot fulfill a user’s request, so it’s important that they’re accurately identified. In the Test Conversations section of the test framework, the columns Slots and Predicted Slots should match, otherwise there’s an issue. In our sample bot, conversation 13 indicates that there was a mismatch.
![]()
Finally, the SessionAttr and PredictedSessionAttr columns should match. Otherwise, there may be an issue in the validation or fulfillment Lambda function that is preventing session attributes from being captured. The following screenshot shows conversation 9, in which the SessionAttr column has a forced inaccuracy to demonstrate the mismatch. There is only one session attribute captured in the PredictedSessionAttr column.

The following is the full test conversations matrix. As an exercise, you can try modifying the sample bot design to turn the failure results to successes.

Cleaning up
To remove all the resources created throughout this process and prevent additional costs, delete the CloudFormation stack you created. This removes all the resources the template created.
Conclusion
Having a test framework that enables chatbot owners to automatically run test cases that cover different conversation pathways is extremely useful for expediting the launch of a well-tested chatbot. This reduces the time that you have to put into testing a chatbot comprised of different intents and slots. This post provides an architecture pattern for implementing a test framework for chatbots built using Amazon Lex to get you started with an important capability that can accelerate the delivery of your conversational AI experiences. Start building your conversational AI experiences with Amazon Lex.
About the Authors
 Shanthan Kesharaju is a Senior Architect at AWS who helps our customers with AI/ML strategy and architecture. Shanthan has over a decade of experience managing diverse teams in both product and engineering. He is an award winning product manager and has built top trending Alexa skills. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
Shanthan Kesharaju is a Senior Architect at AWS who helps our customers with AI/ML strategy and architecture. Shanthan has over a decade of experience managing diverse teams in both product and engineering. He is an award winning product manager and has built top trending Alexa skills. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
 Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.
Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.
 Claire Mitchell is a Conversational AI Design Consultant with AWS Professional Services. Occasionally, she spends time exploring speculative design practices, and finding patterns in bits and beats.
Claire Mitchell is a Conversational AI Design Consultant with AWS Professional Services. Occasionally, she spends time exploring speculative design practices, and finding patterns in bits and beats.
 Alicia Torres is a Charlotte, NC-based Senior Conversational AI Designer with AWS Professional Services. She has spent six years in the field of conversational AI having designed award-winning experiences for large-scale platforms across multiple lines of business.
Alicia Torres is a Charlotte, NC-based Senior Conversational AI Designer with AWS Professional Services. She has spent six years in the field of conversational AI having designed award-winning experiences for large-scale platforms across multiple lines of business.
 Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent seven years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions.
Blake DeLee is a Rochester, NY-based conversational AI consultant with AWS Professional Services. He has spent seven years in the field of conversational AI and voice, and has experience bringing innovative solutions to dozens of Fortune 500 businesses. Blake draws on a wide-ranging career in different fields to build exceptional chatbot and voice solutions.
 Chris Brown is a Portland, OR based Principal Natural Language AI consultant at AWS. He has spent his career focused on designing, building, measuring and optimizing digital customer experiences – including mobile apps, websites, marketing campaigns, and most recently conversational AI applications. Chris is an award winning strategist and product manager – working with the Fortune 100 to deliver the best experiences for their customers. In his freetime, Chris enjoys traveling, music, art, and experiencing new cultures.
Chris Brown is a Portland, OR based Principal Natural Language AI consultant at AWS. He has spent his career focused on designing, building, measuring and optimizing digital customer experiences – including mobile apps, websites, marketing campaigns, and most recently conversational AI applications. Chris is an award winning strategist and product manager – working with the Fortune 100 to deliver the best experiences for their customers. In his freetime, Chris enjoys traveling, music, art, and experiencing new cultures.